
![]()

In this blog, we will first outline the advantages of incorporating Cloudian HyperStore S3-compatible object storage into Kafka workflows. Then we’ll go through a quick “how to” and see how simple it is to integrate.
Scalability and Cost-effectiveness
Cloudian provides virtually unlimited scalability, allowing businesses to seamlessly store and manage massive volumes of data. This scalability is crucial for Kafka workflows, where data ingestion rates can vary significantly and may spike unpredictably. By leveraging the scale out nature of the Cloudian HyperStore data lake, businesses can effortlessly scale their storage capacity to accommodate growing data volumes as needed without having to worry about being limited to an infrastructure silo.
Durability and Reliability
Cloudian is designed for durability and reliability, offering up to 14 nines of data durability. This level of durability ensures that data stored in the the Cloudian S3-compatible platform is highly resilient to failures, data corruption, and other potential issues. In the context of Kafka workflows, this means that businesses can trust the Cloudian platform to reliably store their data without worrying about data loss or integrity issues.
Additionally, Cloudian provides built-in redundancy and data replication across data centers if required, further enhancing data resilience and ensuring high availability. This reliability is crucial for Kafka workflows, where data consistency and integrity are paramount.
Seamless Data Integration and Accessibility
Integrating Cloudian with Kafka workflows enables seamless accessibility across different systems and applications. It supports a wide range of data formats and protocols, allowing businesses to ingest and store various types of data, including semi-structured, and unstructured data.
This flexibility is particularly beneficial for Kafka workflows, which often involve the ingestion and processing of diverse data sources, such as log files, sensor data, social media feeds, and more. By leveraging Cloudian Hyperstore, businesses can centralize their data into a single secure data lake and make it easily accessible to downstream applications and analytics tools, facilitating real-time data processing and analysis.
Enhanced Data Lifecycle Management
Cloudian HyperStore offers robust data lifecycle management capabilities, allowing businesses to define custom policies for data retention, archival, and deletion. This is especially valuable for Kafka workflows, where data retention requirements may vary based on regulatory compliance, business needs, and data usage patterns.
By leveraging these lifecycle management features, businesses can automate the lifecycle of their Kafka data, ensuring that data is retained for the required duration, archived when necessary, and deleted in accordance with retention policies. This streamlines data management operations, reduces manual overhead, and ensures compliance with data retention regulations.
Integration How-to
For this example on how to integrate Apache Kafka with Cloudian, we first deployed a single Kafka 3.6.1 server running on Ubuntu 20.04.6. (The install is outlined here: How To Install Apache Kafka on Ubuntu 20.04). In our configuration, we used the KRaft default server properties rather than using Zookeeper.
To start your Kafka server using KRaft:
Generate a Cluster UUID
rootuser@kafka01:~$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
Format Log Directories
rootuser@kafka01:~$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
Start the Kafka Server
rootuser@kafka01:~$ bin/kafka-server-start.sh config/kraft/server.properties
For more details on these steps, you can refer to the “Quick Start” section of the Apache Kafka Documentation which can be found here Apache Kafka
Once you have the Kafka server running, now you can create a user on Cloudian that will be the owner of the Kafka bucket(s). Use the Cloudian Management Console (CMC) to create a group (or use an existing group) and create a user in that group. Once the user is created, make note of the Access Key and Secret Key for this user.
We created a group called Kafka-grp and a user called kafka-usr.
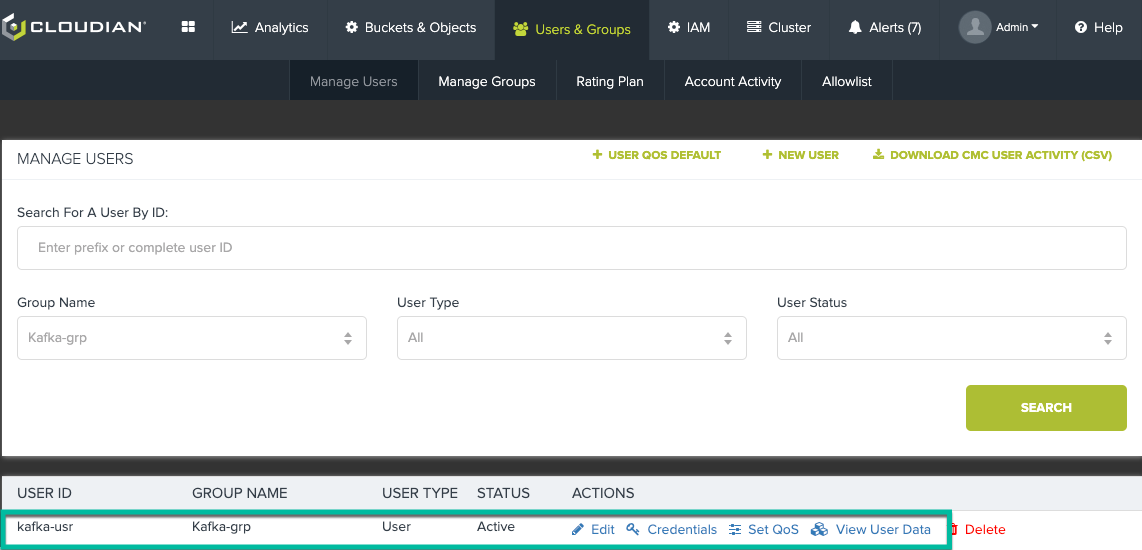

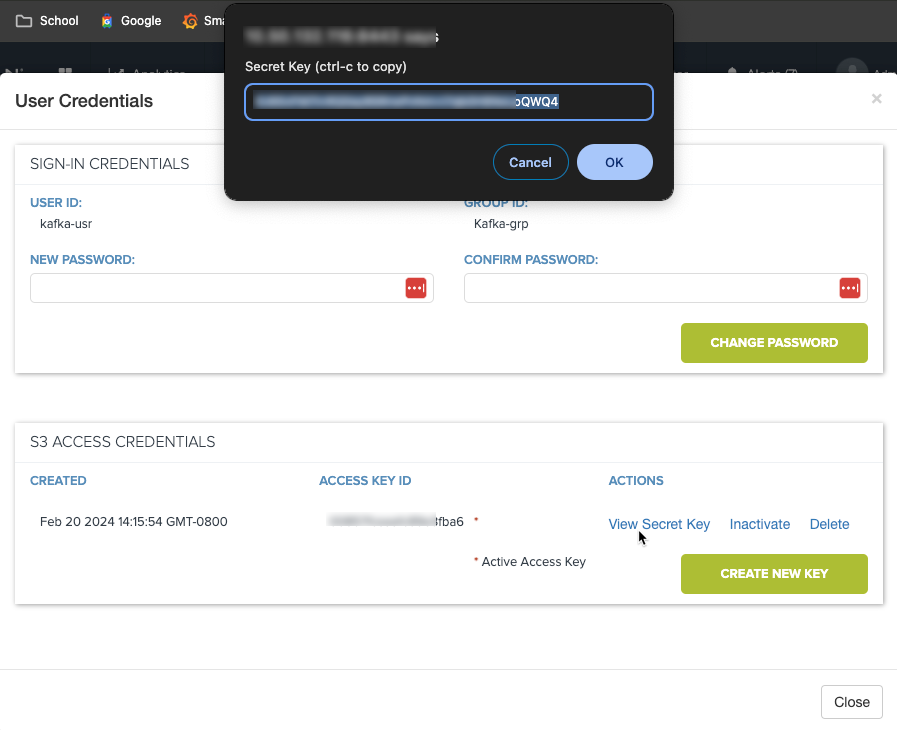

Now, logon to the CMC again using the user credentials and create a bucket which will be used to store the Kafka topic messages.
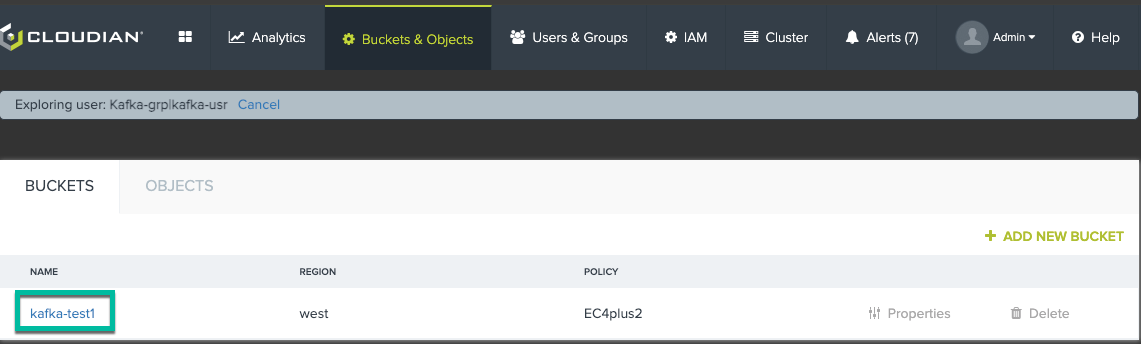

Bucket “kafka-test1” will be the bucket used for this simple integration.
On your Kafka server, configure the default credentials profile to access the Cloudian HyperStore bucket(s) with the Access Key and Secret Key noted above.
kafka@kafka01:~$ pwd /home/kafka kafka@kafka01:~$ mkdir .aws kafka@kafka01:~$ cd .aws kafka@kafka01:~/.aws$ vi credentials
Add the keys in the credentials file as your default profile.
[default] aws_access_key_id = cloudianaccesskeyid aws_secret_access_key = cloudiansecretaccessekyid
Before we download and configure the s3 sink connector, we can can create and start the Kafka topic. In this case we will use “cloudian_demo” as the name for our topic.
kafka@kafka01:~$ pwd /home/kafka kafka@kafka01:~$ cd kafka/ kafka@kafka01:~/kafka$ bin/kafka-topics.sh --create --topic cloudian_demo --bootstrap-server localhost:9092 kafka@kafka01:~/kafka$
You can now install and configure the s3 sink connector. Download the s3 sink connect from this link Kafka S3 Sink Connector. To install the s3 connector, perform the following steps:
- Login to your Kafka server and switch to your Kafka user.
- In the home directory, create a directory called “confluent-plugins” and a directories “plugins and plugins/kafka-connect-s3”.
rootuser@kafka01:~$ su -l kafka
Password:
kafka@kafka01:~$ kafka@kafka01:~$ mkdir confluent-plugins kafka@kafka01:~$ mkdir -p plugins/kafka-connect-s3
- Once the directories are created, scp the s3 sink connector zip file (confluentinc-kafka-connect-s3-10.5.8) you downloaded earlier in the “/home/kafka/confluent-plugins” directory and extract it.
- Then copy the content of the “confluentinc-kafka-connect-s3-10.5.8/lib” diretory into the “plugins/kafka-connect-s3” directory.
kafka@kafka01:~$ cd confluent-plugins kafka@kafka01:~/confluent-plugins$ unzip confluentinc-kafka-connect-s3-10.5.8 kafka@kafka01:~/confluent-plugins$ cp confluentinc-kafka-connect-s3-10.5.8/lib/* ../plugins/kafka-connect-s3/
- Go to the “/home/kafka/plugins” directory and using the editor of your choice, create the config files (connector.properties and s3-sink.properties) that will be required to start the s3 plugin.
kafka@kafka01:~/confluent-plugins$ cd ../plugins/ kafka@kafka01:~/plugins$ kafka@kafka01:~/plugins$ vi connector.properties kafka@kafka01:~/plugins$ vi s3-sink.properties
- The content of the files should be as follows
connector.properties
bootstrap.servers=localhost:9092 plugin.path=/home/kafka/plugins key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.kafka.connect.storage.StringConverter internal.key.converter=org.apache.kafka.connect.json.JsonConverter internal.value.converter=org.apache.kafka.connect.json.JsonConverter internal.key.converter.schemas.enable=false internal.value.converter.schemas.enable=false offset.storage.file.filename=/tmp/connect.offsets
s3-sink.properties
name=s3-sink connector.class=io.confluent.connect.s3.S3SinkConnector tasks.max=1 topics=cloudian_demo s3.region=us-west-2 s3.bucket.name=kafka-test1 s3.part.size=5242880 flush.size=3 store.url=http://s3-west.cloudian-pnslab.com storage.class=io.confluent.connect.s3.storage.S3Storage format.class=io.confluent.connect.s3.format.json.JsonFormat schema.generator.class=io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner schema.compatibility=N0NE
Notice the store.url line which stipulates the custom URL to needed to reach the Cloudian HyperStore S3 object storage platform (http://s3-west.cloudian-pnslab.com), as well as the s3.bucket.name (kafka-test1) and the topics name (cloudian_demo) used in the configuration file. The s3.region is not really used in this case but you still need to include a valid AWS S3 region name, even if it isn’t used.
If you want more information about the various parameters used for these configuration files, you can use this link Amazon S3 Sink Connector Configuration Properties.
You can now start the S3 sink connector.
kafka@kafka01:~$ pwd /home/kafka kafka@kafka01:~$ cd kafka/ kafka@kafka01:~/kafka$ kafka@kafka01:~/kafka$ ./bin/connect-standalone.sh ../plugins/connector.properties ../plugins/s3-sink.properties kafka@kafka01:~/kafka$
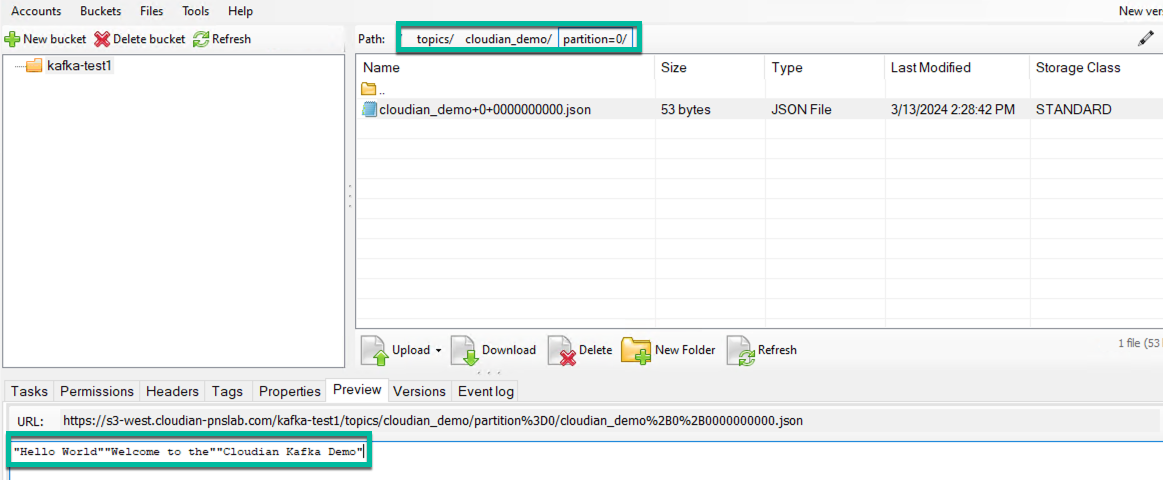
Now you can publish messages in the cloudian_topic and verify they are being store in the bucket. Since we s3-sink.properties file has the flush size set to 3, there will be an object created in the bucket once every 3 messages.
echo "Hello World" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic cloudian_demo >/dev/null echo "Welcome to the" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic cloudian_demo >/dev/null echo "Cloudian Kafka Demo" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic cloudian_demo >/dev/null
Using an S3 bucket browser, you can view and confirm the content of Cloudian HyperStore S3 bucket and verify the content on the object created.

Conclusion
Incorporating Cloudian HyperStore S3-compatible on-prem object storage platform into Kafka workflows offers numerous benefits, ranging from scalability and cost-effectiveness to durability, reliability, and seamless data integration. By leveraging HyperStore’s robust features and capabilities, businesses can enhance their Kafka workflows, streamline data management operations, and unlock new opportunities for real-time data processing and analysis. As organizations continue to harness the power of data-driven insights, the integration of Cloudian with Kafka workflows stands out as a game-changer, empowering businesses to derive maximum value from their data assets.
Learn more at cloudian.com
Or, sign up for a free trial