


Setting New Performance Standards for AI Storage
Our testing confirms that Cloudian HyperStore achieves an impressive 200 GiB/s read throughput on a modest 6-node cluster (12U total). This object storage performance translates to nearly 35 GiB/s per storage node.
These results demonstrate that Cloudian HyperStore not only meets but significantly exceeds NVIDIA’s recommended storage performance guidelines for GPU-intensive AI workloads. With NVIDIA recommending 1.5 GB/s per GPU, our 6-node configuration delivers enough throughput to support over 130 GPUs—far more than the 32 GPUs in our reference architecture’s baseline configuration.
Testing Methodology
To ensure our object storage performance measurements reflect real-world workloads, we conducted comprehensive testing using the following configuration:
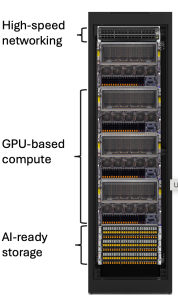

- Storage Configuration: 6-node Cloudian HyperStore cluster
- Storage Nodes: Standard Supermicro Hyper A+ Servers 2U (AS-2115HS-TNR)
- Media: TLC flash media
- Object Size: 5MB
- Client Configuration: 8 concurrent clients with 64 threads per client
- Benchmark Tool: GOSBench (synthetic workload benchmark)
- RDMA workload: Employs direct memory access
Network Infrastructure
- NVIDIA Spectrum-X Networking
- Single ConnectX-7 NIC per node
- 400 Gb connectivity
- Network topology identical to our SuperMicro reference architecture
Download the full reference architecture here.
This testing environment closely mirrors the Cloudian-Supermicro Full AI Stack Reference Architecture, providing a validated blueprint for organizations looking to deploy rack-scale AI infrastructure.
Scalability: The Key to AI Infrastructure Growth
With linear scalability of the Cloudian HyperStore architecture, this object storage performance grows as organizations add storage nodes to their clusters. This allows an organization to achieve proportional increases in throughput—scaling to terabytes per second in larger deployments.
This linear scaling characteristic is particularly valuable for AI workloads, which typically grow in both data volume and computational demands over time. Unlike traditional storage architectures that can only be scaled to fixed limits, Cloudian’s peer-to-peer, shared nothing architecture allows organizations to start with a right-sized deployment and expand seamlessly as their AI initiatives mature.
Implications for Enterprise AI Initiatives
For data scientists, ML engineers, and IT architects, these object storage performance results translate to tangible business benefits:
-
- Maximized GPU Utilization: Ensures expensive GPU resources are never idle waiting for data
- Reduced Training Time: Faster data delivery means more training iterations and quicker model convergence
- Ideal for Inference: In addition to high bandwidth, Cloudian also delivers low latency, making it ideal for inference workloads that demand fast response and scalable capacity
- Cost-Efficient Scaling: Object storage economics combined with high performance eliminates the need for expensive specialized file systems
- Simplified Infrastructure: S3-compatible object storage with RDMA acceleration delivers file storage-level performance with cloud-native simplicity
The Technology Behind the Numbers
Cloudian HyperStore achieves these breakthrough performance levels through a combination of architectural innovations:
- RDMA Integration: Direct memory access capabilities reduce CPU overhead and latency
- Parallel Architecture: Distributed design enables simultaneous data access across all nodes
- Optimized Data Placement: Intelligent data distribution maximizes throughput while maintaining redundancy
- High-Speed Networking: Full integration with NVIDIA Spectrum-X and ConnectX-7 NICs
Conclusion
As AI workloads continue to push the boundaries of infrastructure performance, storage systems must evolve to match the computational power of modern GPUs. Our testing demonstrates that Cloudian HyperStore is ready to meet this challenge, delivering exceptional object storage performance that scales linearly with infrastructure growth.
The full details of our testing methodology and results are available in the Cloudian-NVIDIA-Supermicro Full AI Stack Reference Architecture document, which provides a comprehensive blueprint for organizations looking to deploy high-performance AI infrastructure.
For more information on implementing Cloudian HyperStore in your AI infrastructure, visit www.cloudian.com.
Download the full stack reference architecture here.