
As enterprises stand up AI factories, an awkward pattern keeps emerging: the more workloads they run, the more storage clusters they end up managing. A training environment here, a RAG pipeline there, a separate cluster for the regulated business unit, another one for the customer-facing inference service. Each new workflow brings another silo — and with it another set of administrators, another procurement cycle, another integration project, and another pool of capacity that’s full when its neighbor is empty.
This is the silo problem that object storage was supposed to have solved a decade ago. It’s back, dressed in GPU clothing, and it’s one of the biggest threats to AI factory economics.
The way out is multi-tenancy — where a single physical cluster behaves to each consumer exactly as if it were a dedicated system of its own. Cloudian HyperStore was designed for this from day one, and as AI factories proliferate inside the enterprise, multi-tenancy has become its most operationally valuable feature. This post explains what real multi-tenancy looks like, why AI factories cannot work without it, and how HyperStore delivers it.
What multi-tenancy actually means
True multi-tenancy is the ability to take one physical storage cluster and present it to many separate consumers as if each had a cluster of their own. Each tenant sees its own namespace, its own users and groups, its own access policies, its own quotas, its own performance budget, its own encryption keys, its own audit log — but the operator sees one system, with one capacity pool, one set of nodes to patch, and one set of operational procedures.
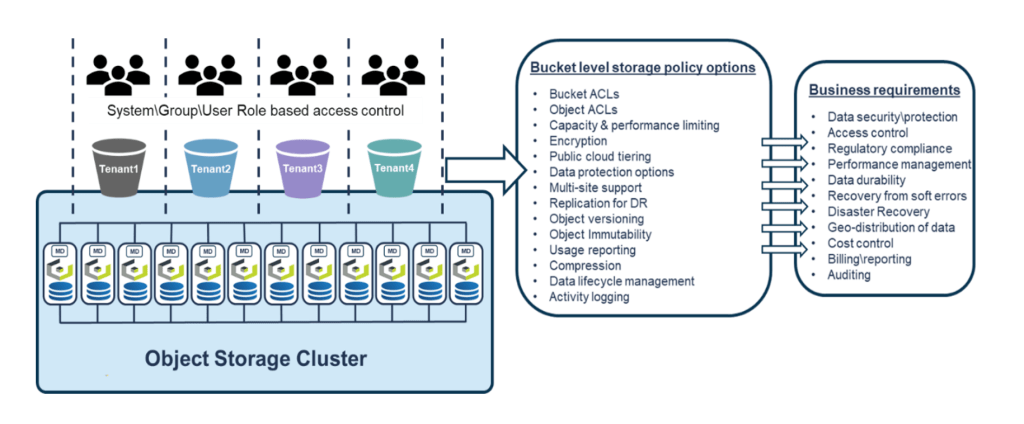

That is fundamentally different from carving up a data centre into a series of smaller, dedicated clusters. Dedicated clusters give you isolation, but they reproduce every form of waste — stranded capacity, duplicated operations, mismatched performance headroom, redundant DR plans, and a fragile mesh of data movers between pools. Multi-tenancy gives you the isolation and the consolidation.
Why AI factories make this requirement non-negotiable
An AI factory is rarely one workload. It’s a portfolio: model training and fine-tuning, retrieval-augmented generation, vector search, KV-cache offload, agentic pipelines, evaluation runs — plus all the raw ingest, curated datasets, embeddings, model artefacts, and inference logs that feed them. Different teams own different pieces. Different regulatory regimes apply to different datasets. Different customers — internal or external — fund different workloads.
If each of those needs its own storage cluster, the economic case for on-premises AI collapses under operational overhead before a single GPU is bought. If they all share a cluster without real isolation, the first noisy-neighbor incident — or the first compliance review — ends the project.
The only viable path is to consolidate the entire AI data lifecycle onto a single, high-performance pool, and rely on multi-tenancy to keep tenants safely separated.
How HyperStore delivers it
HyperStore’s multi-tenancy model treats each bucket as an independently configurable namespace. A tenant’s buckets are logically isolated by default — invisible and inaccessible to other tenants unless permission is explicitly granted. From the tenant’s perspective, the bucket endpoint behaves as a dedicated S3-native service. From the operator’s perspective, it’s all the same system.
That isolation extends across every dimension that matters in production:
- HyperStore integrates with one or more Active Directory or LDAP systems and supports SAML federated SSO, MFA, and selective AWS IAM API support including IAM users, groups, and role-based access control. Each tenant authenticates against its own directory and manages its own users.
- AES-256 at rest, configurable per bucket or per object, with the option of customer-provided keys (SSE-C) or external KMS integration via KMIP. Tenants who need to hold their own keys can.
- Quality of service. Group- and user-level rate limits stop any one tenant from monopolizing the system. Quotas can be set on capacity, object count, or both, with usage reporting at system, group, and user level to support chargeback.
- Retention, immutability (S3 Object Lock / WORM), versioning, replication targets, and lifecycle rules are configured independently per tenant — or even per bucket within a tenant.
- Per-tenant access logs and audit trails export cleanly to SIEM tooling.
The security and compliance posture behind all of this is unusually deep for an object store: FIPS 140-3 Level 1 cryptography, S3 Object Lock for ransomware defense, Secure Delete that exceeds NIST 800-88, and certifications aligned with SEC Rule 17a-4(f). HyperStore Shell and RootDisable harden the platform at the OS level, eliminating the porous root access that has historically plagued comparable solutions. The point isn’t the alphabet soup — it’s that a regulated tenant on a shared HyperStore cluster doesn’t have to relax any of the controls it would expect on dedicated hardware.
When logical isolation isn’t enough
For most AI factory tenants, logical separation is plenty. But some workloads — air-gapped classified data, certain sovereign AI use cases, customers with strict physical-isolation contracts — need to know their bits live on dedicated hardware. HyperStore handles that without giving up the unified management model: storage nodes can be grouped into data-center constructs, and buckets pinned to a specific group. The tenant gets physical isolation; the operator still runs one system.

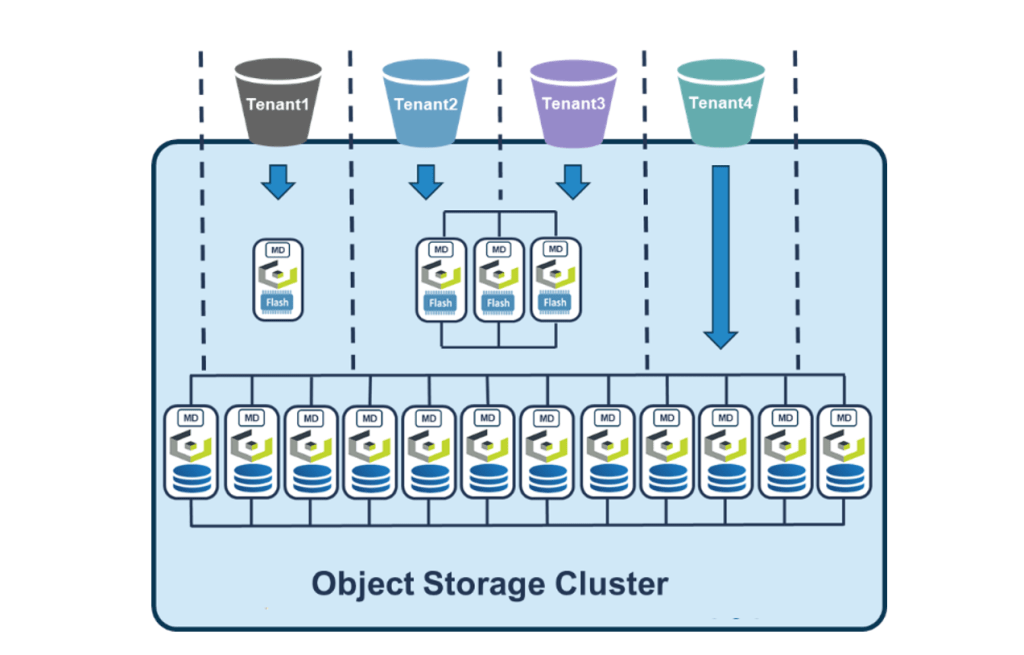
What this unlocks for the AI factory
Multi-tenancy is what turns “one big storage pool” from a slogan into a viable operating model. With it, a single HyperStore cluster can host:
- A regulated business unit, with tenant-managed keys, WORM retention, and SEC 17a-4(f) audit posture.
- A research team running training and fine-tuning, with QoS limits that protect production tenants from training-burst bandwidth spikes.
- A production RAG service, with low-latency RDMA for S3 compatible storage paths feeding embeddings and source documents directly into GPU memory.
- An external customer or a subsidiary, with chargeback metering and its own identity provider.
- A KV-cache offload tier for inference servers, tuned for high-frequency small-object access.
All on the same cluster. All sharing the same capacity pool, the same operations team, the same management plane. None of them aware of, or affected by, the others.
And because HyperStore exposes one S3-native API across every tenant, workloads built against it are portable — they run unchanged on-premises, at the edge, or in the cloud, which matters as enterprises increasingly operate hybrid AI factories.
The bottom line
The AI factory era is consolidating compute around GPUs. The storage layer underneath has to consolidate too — or the silos that compute is leaving behind simply migrate to the data plane and stall the whole program. Multi-tenancy is the mechanism that makes consolidation safe: it lets every AI workflow, every business unit, every regulatory regime, and every external customer share one physical cluster while remaining fully isolated from one another.
That is what HyperStore was built for. The economics of a single platform with the isolation guarantees of dedicated ones — which, for AI factories that multiply workloads faster than they can multiply budgets, is the difference between an operating model that scales and one that suffocates under its own sprawl.
For more information visit cloudian.com.