

What Is AWS S3 Backup?
Amazon Simple Storage Service (S3) allows you to store objects in the AWS cloud. The service lets you store your data using several types of storage classes offering various types of access, which you can employ as needed to build your own backup solution in the cloud.
You can use Amazon S3 storage to set up hybrid cloud backup, leveraging AWS Storage Gateway to seamlessly deliver data from your on-premise workloads to archival storage in the AWS cloud. AWS Gateway also allows you to replace your on-premise backup tapes. In addition, AWS S3 provides backup features that enable you to version objects, set up encryption, accelerate transfers, and more.
In this article:
- Amazon S3 Backup Use Cases
- Amazon S3 Storage Classes
- Amazon S3 Glacier and S3 Glacier Deep Archive
- AWS S3 Backup Features
- S3-Compatible Storage with Cloudian
This is part of an extensive series of articles about S3 Storage.
Amazon S3 Backup Use Cases
Here are some common backup use cases for Amazon S3.
Hybrid Cloud Backup
Many backup services allow you to send backup data to AWS without disrupting your business operations. If your existing on-prem solution doesn’t have cloud connectors, you can create seamless connections between your on-prem environment and AWS using a gateway service (i.e., AWS Storage Gateway).
You can generate backups on-premises and send them to AWS for storage in Amazon S3, where you can leverage cold storage classes such as Glacier and Glacier Deep Archive. When you restore data from a backup, you can pull the data back to your on-premises environment from the cloud.
The following diagram illustrates the hybrid cloud backup architecture.
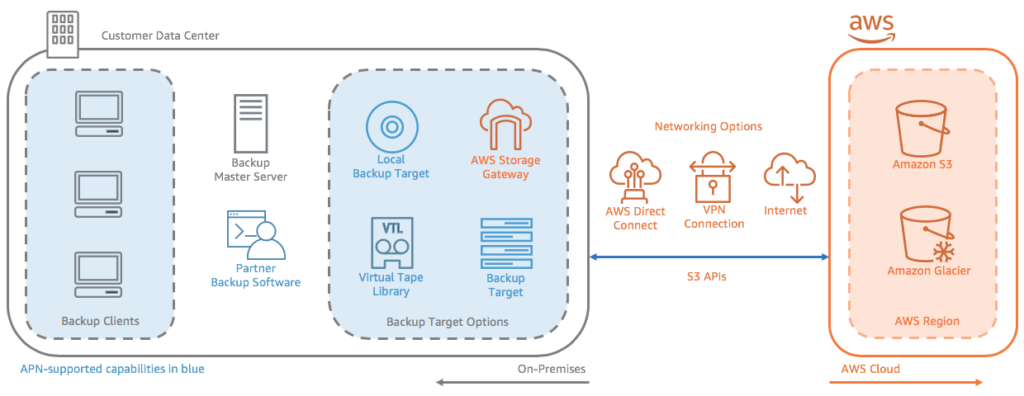
Image Source: AWS
Replacing Tapes
AWS Storage Gateway allows you to replace physical tape libraries with more secure and durable cloud-based alternatives. Without disrupting your workflows, you can transfer backup jobs to AWS from your virtual or on-premises tape library systems. AWS Storage Gateway provides a virtual tape library interface that you can use to update backup infrastructure, minimize upfront costs, reduce the maintenance burden for aging tapes, and avoid having to transfer storage media to or from an offsite facility.
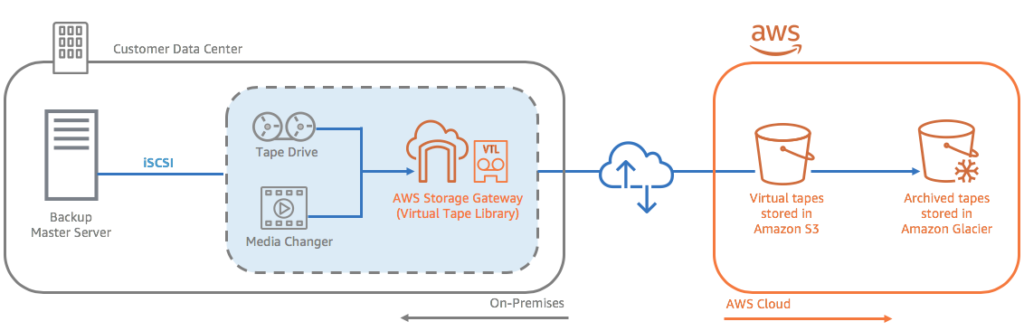
Image Source: AWS
Managing Data Lifecycles
Amazon S3 supports data lifecycle management features. S3 Storage Class Analysis allows you to track data access patterns and helps you determine which data sets you can move to a more cost-effective storage class. You can set a data lifecycle policy based on the reports it generates, allowing you to move data sets automatically and optimize your costs. S3 Lifecycle Management allows you to set policies that schedule deletions of objects at the end of their lifecycle.
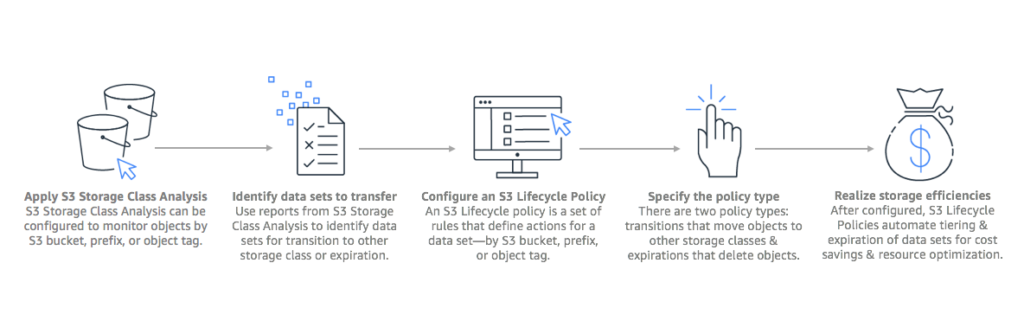
Image Source: AWS
Data Resiliency
The AWS global infrastructure allows you to set up and manage a multi-regional architecture. You can replicate objects across AWS Regions to reduce latency and enhance security. S3 will automatically extend the changes to the replicated objects when you change the source properties.
Compliance
Some regulations require organizations to maintain an archive. Archival storage classes such as S3 Glacier Deep Archive allow you to store data you don’t intend to use for other purposes. You can enable S3 Object Lock to prevent the deletion or modification of archived objects using write-once-read-many (WORM) protection.
Amazon S3 Storage Classes
Here are the seven storage classes offered with Amazon S3:
- S3 Standard—is designed to support frequently-accessed data delivered with low latency and high throughput. This storage class is ideal for dynamic websites, applications, big data workloads, and content distribution.
- S3 Intelligent-Tiering—is designed to support data with either changing or unknown access needs. This storage class offers four access tiers: Deep Archive, Archive, Infrequent Access (IA), and Frequent Access. This class automatically moves data to the least expensive storage tier—according to the access patterns of the customer.
- S3 Standard-IA—offers lower storage pricing for infrequent access. This type of data may be needed less often, but it still requires quick access. This storage class is ideal for backup, data recovery (DR), and long-term data storage.
- S3 One Zone-IA—designed to support infrequently-accessed data that does not require high availability or resilience.
- S3 Glacier—is designed to support archival storage. This tier offers lower prices, but it takes longer to access this data. It offers variable retrieval rates, which range from minutes to hours.
- S3 Glacier Deep Archive—is designed to support data that needs to be accessed only once or twice per year.
- S3 Outposts—lets you store S3 objects in your local AWS Outposts environment, using the regular S3 user interface and API. S3 Outposts are useful when you need to store data physically near to local applications.
S3 Glacier and S3 Deep Archive are popular choices for backup purposes. However, the other storage classes may be more suitable for certain backup scenarios.
Related content: Read our guide to S3 bucket
Amazon S3 Glacier and S3 Glacier Deep Archive
Amazon S3 provides two low-cost storage classes for data archives and long-term backups: Glacier and Glacier Deep Archive. They are highly durable and secure, designed to help customers comply with stringent regulations. Data storage can cost as little as $1 per TB per month. Here are some important features of these storage classes.
Retrieval Options
S3 Glacier offers three retrieval options:
- Standard retrievals—complete between three and five hours.
- Expedited retrievals—complete between one and five minutes, useful for active archives.
- Bulk retrievals—complete in 5-12 hours, useful for retrieving large amounts of data cheaply.
S3 Glacier Deep Archive offers two retrieval options that take 12 to 48 hours to complete.
Scalability and Durability
AWS offers the biggest global cloud infrastructure, automatically distributing data across at least three Availability Zones in an AWS Region.
Security and Compliance Capabilities
S3 Glacier and Glacier Deep Archive support integration with AWS CloudTrail for logging, monitoring, and retaining storage API call activity, allowing you to present audit data to demonstrate compliance. They support various compliance and security standards such as PCI-DSS, GDPR, and HIPAA. You can enhance security using WORM policies and three types of encryption.
Cost-Efficiency
Designed for archiving large volumes of data, Glacier and Glacier Deep Archive are the cheapest S3 storage classes. These more affordable storage options allow you to store massive amounts of data for various use cases, including data analytics, data lakes, machine learning (ML), media asset archives, and compliance. There are no up-front costs or minimum commitments, so you only pay for your usage.
AWS S3 Backup Features
Here are some Amazon S3 features that are useful for backup purposes.
Object Versioning
This feature stores each version of every object, allowing you to restore previous versions in the event of an accidental overwrite or deletion. A major reason for archiving data is to protect it not from external threats like disaster scenarios but human error. Object versioning allows you to retrieve previous versions using GET requests.
When you delete an object with versioning enabled, Amazon S3 tags the object with a deletion marker rather than deleting it directly. You can use lifecycles policies to ensure that S3 only stores old versions for a short time, allowing you to minimize storage costs for redundant versions.
Physical Redundancy
By default, Amazon S3 stores three copies of each file in physically separate data centers within an AWS Availability Zone. You can set up data replication in additional Availability Zones for added redundancy, though you will have to pay for the extra storage.
Transfer Acceleration
Amazon S3 Transfer Acceleration allows you to accelerate data uploads. When enabled, AWS optimizes and re-routes to the appropriate data centers via the AWS transfer channels, improving upload speeds by up to 500%. You should test your data transfer speed before enabling Transfer Acceleration.
Encryption
AWS automatically encrypts all S3 storage data. For added security, you can specify the decryption keys used.
Object Lock
S3 Object Lock allows you to protect objects with a write-once-read-many (WORM) policy. You can protect objects from overwrites and deletions indefinitely or for a specified time frame. Object Lock can also help you comply with regulations requiring a WORM storage model. You can only use Object Lock in versioned buckets.
Object Lock allows you to manage object retention in two ways:
- Retention periods—you specify a fixed time frame for the WORM protection.
- Legal holds—you apply WORM protection to the object indefinitely until you remove it explicitly.
You can apply both retention periods and legal holds to each object version. You have to apply these protections individually to each object version—this won’t prevent the creation of new versions of the same object or extend protection to other versions.
Meet Cloudian: S3-Compatible, Massively Scalable On-Premise Object Storage
Cloudian® HyperStore® is a massive-capacity object storage device that is fully compatible with Amazon S3. You can use it as an on-premise alternative to S3 backup. It can store up to 1.5 Petabytes in a 4U Chassis device, allowing you to store up to 18 Petabytes in a single data center rack. HyperStore comes with fully redundant power and cooling, and performance features including 1.92TB SSD drives for metadata, and 10Gb Ethernet ports for fast data transfer.

HyperStore is an object storage solution you can plug in and start using with no complex deployment. It also offers advanced data protection features, supporting use cases like compliance, healthcare data storage, disaster recovery, ransomware protection and data lifecycle management.
Learn more about Cloudian® HyperStore®.