
What Is AWS S3 Bucket?
Amazon Simple Storage Service (Amazon S3) is an object storage solution that provides data availability, performance, security and scalability. Organizations from all industries and of every size may use Amazon S3 storage to safeguard and store any amount of information for a variety of use cases, including websites, data lakes, backup and restore, mobile applications, archives, big data analytics, IoT devices, and enterprise applications.
To retain your information in Amazon S3, you use resources called objects and buckets. A bucket is a container that houses objects. An object contains a file and all metadata used to describe the file.
To retain an object in Amazon S3, you develop a bucket and upload the object into it. Once the object is within the bucket, you may move it, download it, or open it. When you don’t require the bucket or object any longer, you can discard them to trim back on your resources.
In this article:
- How to Use an Amazon S3 Bucket
- Tutorial: Creating a Bucket
- What Is S3 Bucket Policy?
- S3 Bucket URL and Other Methods to Access Your Buckets
- S3 Bucket Configuration: Understanding Subresources
- Best Practices for Keeping Amazon S3 Buckets Secure
- S3 Bucket with Cloudian
This is part of an extensive series of articles about S3 Storage.
How to Use an Amazon S3 Bucket
An S3 customer starts by establishing a bucket in the AWS region of their choosing and assigns it a unique name. AWS suggests that customers select regions that are geographically close to them in order to minimize costs and latency.
After creating the bucket, the user chooses a storage tier based on the usage requirements for the data—there are various S3 tiers ranging in terms of price, accessibility and redundancy. A single bucket can retain objects from distinct S3 storage tiers.
The user may then assign particular access privileges regarding the objects retained in the bucket using various mechanisms, including bucket policies, the AWS IAM service, and ACL.
An AWS customer may work with an Amazon S3 bucket via the APIs, the AWS CLI, or the AWS Management Console.
Related content: Read our guide to the S3 API
Tutorial: Creating a Bucket
Before you can store content in S3, you need to open a new bucket, selecting a bucket name and Region. You may also wish to select additional storage management choices for your bucket. Once you have configured a bucket, you can’t modify the Region or bucket name.
The AWS account that opened the bucket remains the owner. You may upload as many objects as you like to the bucket. According to the default settings, you can have as many as 100 buckets for each AWS account.
S3 lets you create buckets using the S3 Console or the API.
Keep in mind that buckets are priced according to data volume stored in them, and other criteria. Learn more in our guide to S3 pricing
Developing an S3 bucket via the S3 console:
- Access the S3 console.
- Select Create bucket.
- In Bucket name, create a DNS-accepted name for your bucket.
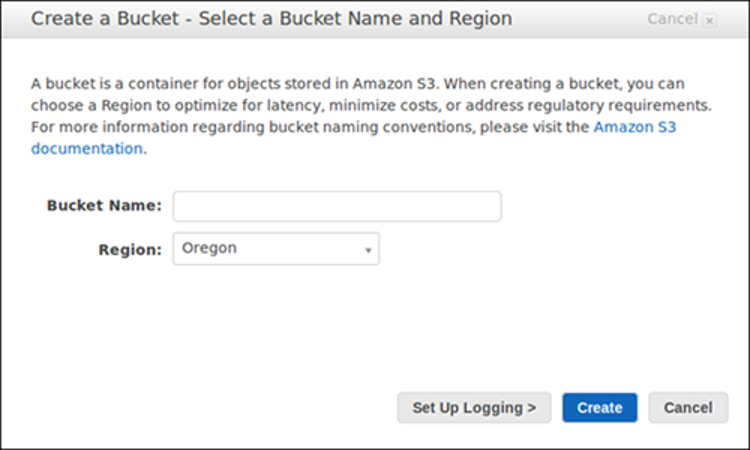

Image Source: AWS
The bucket name must be unique, begin with a number or lowercase letter, be between 3-63 characters, and may not feature any uppercase characters.
4. Select the AWS Region for the bucket. Select a Region near you to keep latency and cost to a minimum and to address regulatory demands. Keep in mind there are special charges for moving objects outside a region.
5. In Bucket settings for Block Public Access, specify if you want to allow or block access from external networks.
6. You can optionally enable the Object Lock feature in Advanced settings > Object Lock.
7. Select Create bucket.
What Is S3 Bucket Policy?
S3 provides the concept of a bucket policy, which lets you define access permissions for a bucket and the content stored in it. Technically, it is an Amazon IAM policy, which employs a JSON-based policy language.
For instance, policies permit you to:
- Enable read access for unknown users
- Restrict a particular IP address from accessing the bucket
- Place a limit on access to a particular HTTP referrer
- Require multi-factor authorization
S3 Bucket URLs and Other Methods to Access Your Buckets
You can perform almost any operation using the S3 console, with no need for code. However, S3 also provides a powerful REST API that gives you programmatic access to buckets and objects. You can reference any bucket or the objects within it via a unique Uniform Resource Identifier (URI).
Amazon S3 provides support for path-style and virtual-hosted-style URLs to gain access to a bucket. Given that buckets are accessible to these URLs, it is suggested that you establish buckets with bucket names that are DNS-compliant.
Virtual-Hosted-Style Access
In a virtual-hosted-style request, the bucket name is a component of the domain name within the URL.
Amazon S3 virtual-hosted-style URLs employ this format:
https://bucket-name.s3.Region.amazonaws.com/key name
For example, if you name the bucket bucket-one, select the US East 1 (Northern Virginia) Region, and use kitty.png as your key name, the URL will look as follows:
https://bucket-one.s3.us-east-1.amazonaws.com/kitty.png
Path-Style Access
In Amazon S3, path-style URLs use this format:
https://s3.Region.amazonaws.com/bucket-name/key name
For example, if you created a bucket in the US East (Northern Virginia) Region and named it bucket-one, the path-style URL you use to access the kitty.jpg object in the bucket will look like this:
https://s3.us-east-1.amazonaws.com/bucket-one/kitty.jpg
Accessing a Bucket Via S3 Access Points
As well as working with a bucket directly, you can work with a bucket via an access point.
S3 access points exclusively support virtual-host-style addressing. To address a bucket via an access point, you must employ the following format:
https://AccessPointName-AccountId.s3-accesspoint.region.amazonaws.com.
Accessing a Bucket Using S3://
Certain AWS services need you to specify an Amazon S3 bucket via S3://bucket, where you will need to follow this format:
S3://bucket-name/key-name
Note that when employing this format the bucket name does not feature the AWS Region. For example, a bucket called bucket-one with a kitty.jpg key will look like this:
S3://bucket-one/kitty.jpg
S3 Bucket Configuration: Understanding Subresources
AWS provides various tools for Amazon S3 buckets. An IT specialist may enable different versions for S3 buckets to retain every version of an object when an operation is carried out on it, for example a delete or copy operation. This may help stop IT specialists from accidentally deleting an object. Similarly, when creating a bucket, a user can establish server access logs, tags, object-level API logs, and encryption.
S3 Transfer Acceleration can assist with the execution of secure and fast transfers from the client to an S3 bucket via AWS edge locations.
Amazon S3 provides support for different alternatives for you to configure your bucket. Amazon S3 offers support for subresources so you can manage and retain the bucket configuration details. You can employ the Amazon S3 API to manage and develop these subresources. You may also utilize the AWS SDKs or the console.
These are known as subresources since they function in the context of a certain object or bucket. Below lists subresources that let you oversee bucket-specific configurations.
cors (cross-origin resource sharing): You may configure your bucket to permit cross-origin requests.
event notification: You may permit your bucket to alert you of particular bucket events.
lifecycle: You may specify lifecycle regulations for objects within your bucket that feature a well-outlined lifecycle.
location: When you establish a bucket, you choose the AWS Region where you want Amazon S3 to develop the bucket. Amazon S3 retains these details in the location subresources and offers an API so you can gain access to this information.
logging: Logging lets you monitor requests for access to the bucket. All access log records give details regarding one access request, including bucket name, requester, request action, request time, error code, and response status.
object locking: Enables the object lock feature for a bucket. You may also wish to configure a default period of retention and mode that applies to the latest objects that are uploaded to the bucket.
policy and ACL (access control list): Both buckets and the objects stored within them are private, unless you specify otherwise. ACL and bucket policies are two ways to grant permissions for an entire bucket.
replication: This option lets you automatically copy the content of the bucket to additional buckets, within the Amazon Region. Replication is asynchronous.
requestPayment: By default, the AWS account that sets up a bucket also receives bills for requests made to the bucket. This setting lets the bucket creator pass on the cost of downloading data from the bucket to the account downloading the content.
tagging: This setting allows you to add tags to an S3 bucket. This can help you track and organize your costs on S3. AWS shows the tags on your charges allocation report, with costs and usage aggregated via the tags.
transfer acceleration: Transfer acceleration enables easy, secure and fast movement of files over extended distances between your S3 bucket and your client. Transfer acceleration leverages the globally distributed edge locations via Amazon CloudFront.
versioning: Versioning assists you when recovering accidental deletes and overwrites.
website: You may configure the bucket for static website hosting.
Best Practices for Keeping Amazon S3 Buckets Secure
AWS S3 Buckets may not be as safe as most users believe. In many cases, AWS permissions are not correctly configured and can expose an organization’s AWS S3 buckets or some of their content.
Although misconfigured permissions are by no means a novel occurrence for many organizations, there is a specific permission that entails increased risk. If you allow objects to be public, this establishes a pathway for cyberattackers to write to S3 buckets that they don’t have the correct permissions to access. Misconfigured buckets are a major root cause behind many well-known attacks.
To protect your S3 buckets, you should apply the following best practices.
Block Public S3 Buckets at the Organization Level
Assign AWS accounts for public S3 utilization and stop all other S3 buckets from accidentally becoming public by putting in place S3 Block Public Access. Employ Organizations Service control policies (SCPs) to ensure that the Block Public Access setting is not alterable. S3 Block Public Access offers a degree of safety that functions at the level of the account and also on single buckets, encompassing those that you develop in the future.
You retain the capacity to prevent existing public access—irrespective of whether it was specified by a policy or an ACL—and to make sure that public access is not given to items you newly create. This provides only specific AWS accounts with public S3 buckets and stops all other AWS accounts.
Implement Role-Based Access Control
Outline roles that cover the access needs of users and objects. Make sure those roles have the least access needed to carry out the job so that if a user’s account is breached, the damage is kept to a minimum.
AWS security is founded on AWS Identity and Access Management (IAM) strategies. A principal is an identity that may be validated, for example, with a password. Roles, users, applications, and federated users (from separate systems) may all be principals. When a validated principal requests an entity, resource, service, or a different asset, verification begins.
Verification policies determine what access the principal has to the resource being requested. Approval is given based on resource-based methods or identity. Matching each validated principal with each validated policy will ascertain if the request is permitted.
Another data security methodology is splitting or sharing data into different buckets. For instance, a multi-tenant application could require separate Amazon S3 buckets for every tenant. You can use another AWS tool, Amazon VPC, which grants your endpoints secure access to sections of your Amazon S3 buckets.
Encrypt Your Data
Even with your greatest efforts, it remains good practice to assume that information is always at risk of being exposed. Given this, you should use encryption to stop unauthorized individuals from using your information if they have managed to access it.
Make sure that your Amazon S3 buckets are encrypted during transit and while sitting on the server. If you just have a single bucket, this is likely not complex, but if buckets are being developed dynamically, it may be difficult to keep track of them and manage encryption appropriately.
On the server side, Amazon S3 buckets support encryption, but this has to be enabled. Once encryption is turned on, the information is encrypted at rest. Encrypting the bucket will make sure that any individual who manages to access the data will require a password (key) to decrypt the data.
For transport security, HTTPS is used to make sure that information is encrypted from one end to another. Every additional version of Transport Layer Security (TLS) ensures that the protocol is more secure and does away with out-of-date, now insecure, encryption methods.
S3-Compatible Storage On-Premises with Cloudian
Cloudian® HyperStore® is a massive-capacity object storage device that is fully compatible with Amazon S3. It allows you to easily set up an object storage solution in your on-premises data center, enjoying the benefits of cloud-based object storage at much lower cost.
HyperStore can store up to 1.5 Petabytes in a 4U Chassis device, allowing you to store up to 18 Petabytes in a single data center rack. HyperStore comes with fully redundant power and cooling, and performance features including 1.92TB SSD drives for metadata, and 10Gb Ethernet ports for fast data transfer.

{kind=link}

HyperStore is an object storage solution you can plug in and start using with no complex deployment. It also offers advanced data protection features, supporting use cases like compliance, healthcare data storage, disaster recovery, ransomware protection and data lifecycle management.
Learn more about Cloudian® HyperStore®.