


This dramatic improvement was realized by offloading the indexing process to NVIDIA L40S GPUs using NVIDIA cuVS accelerated vector search and leveraging Cloudian S3 with RDMA for high-speed data transfer, compared to a CPU-based Milvus setup with regular S3 over TCP. In our test case, this advancement significantly boosted the efficiency of real-time data ingestion and query readiness for large-scale vector search applications.

Introduction: The Business Challenge of Data Velocity
In today’s AI data-driven world, the ability to quickly transform raw data into usable information for actionable insights is paramount. Many organizations struggle with the “data gravity” problem – the sheer volume and velocity of incoming data making it difficult to keep up with indexing and preparation for real-time querying. Moreover, modern enterprise AI applications ingest TB – PB scale documents which takes days to weeks of embedding and indexing time and is unacceptable for critical vector store applications.
For applications relying on vector similarity search, the bottleneck often lies in the compute-intensive process of creating vector embeddings and then building efficient indexes on these embeddings within a vector database like Milvus.
CPU-bound indexing, coupled with TCP-based object storage access, can lead to significant delays, hindering the business’s ability to react to new information promptly.
Benefits of Vector Indexing in Scalability and Cost Reduction
To understand why indexing performance matters so critically for AI applications, it’s essential to examine how modern retrieval-augmented generation systems work. RAG (retrieval augmented generation) incorporates vector indexing, employing a vector database as an external knowledge base to augment the LLM’s reasoning response accuracy by retrieving relevant contextual information that the model can then incorporate into its responses, effectively expanding its knowledge beyond what was learned during training.

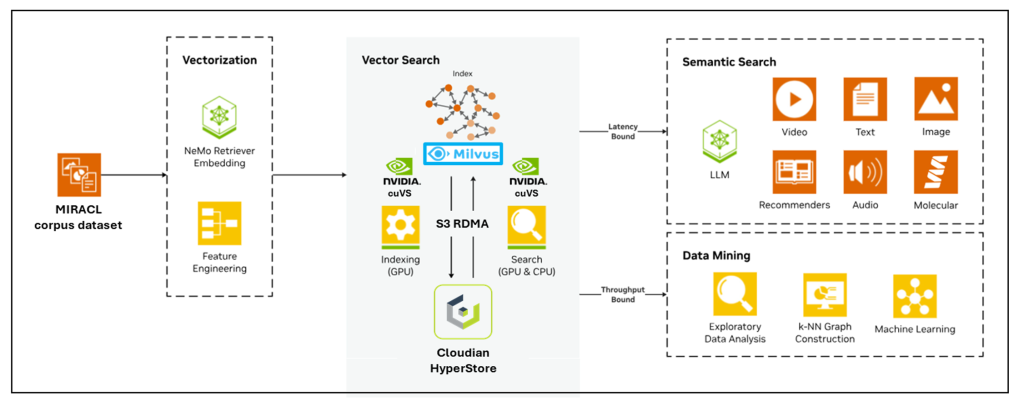
In our test scenario, the MIRACL dataset https://project-miracl.github.io/ is stored in an S3 bucket as raw data and is used as the base data set which is tokenised and vectorised with the NVIDIA llama-3.2-nv-embedqa-1b-v2 NIM.
The next step involves loading the vectorized data into the Milvus vector database and indexing the data to optimise similarity search accuracy and response times. Without an index, a database would have to perform an exhaustive “brute-force” search, comparing a query vector to every single vector in the database. Brute-force search is incredibly slow and doesn’t scale for large datasets, which are becoming more common in modern AI applications.
Indexing benefits include:
- Reduced Search Time: Like a machine learning model, vector search indexes create a structured, searchable model that organizes the vectors for the database to quickly narrow down the search space to a small subset of likely candidates instead of scanning everything. Indexing can reduce search time from a linear to a logarithmic time complexity.
- Scalability: Indexing allows vector databases to handle millions or even several billions of data points without a proportional decrease in performance. As the dataset grows, the index remains efficient, ensuring the system can scale with increasing data volumes and user demands.
- Reduced Computational Cost: By avoiding an exhaustive scan of the entire dataset, indexing significantly lowers the computational resources required for each query. This leads to lower hardware costs and more efficient operations during data query workloads.
But indexing has a cost. Building and storing a vector index can require a significant amount of memory, compute power and storage space. This is particularly true for large datasets. When building RAG applications this should be considered as a specific workload to plan for.
High-Level Overview of the Testing Stack
The architecture for our testing included the following software and hardware components.
- Milvus Vector Database: An open-source vector database specifically designed for storing, indexing, and querying high-dimensional vector embeddings. Its distributed architecture, coupled with Cloudian HyperStore as its S3 object storage backend, provides a highly scalable, performant, and durable solution for managing massive vector datasets generated by RAG pipelines. Milvus enables millisecond-level query response times for billion-scale vector datasets, making it an ideal choice for similarity search in RAG, generative AI and data mining applications.
- Cloudian HyperStore: The primary data store for raw data, snapshot files of logs, index files for scalar and vector data, and intermediate query results via accelerated S3 with RDMA. The key differentiator in our test was the use of RDMA (Remote Direct Memory Access). RDMA-enabled S3 allows direct memory access between servers without involving the CPU. This significantly reduced latency and increased throughput for data transfer. This is crucial for rapidly moving large volumes of vector data between storage and the indexing compute nodes.
- NVIDIA cuVS : A high-performance, GPU-accelerated library for vector search and indexing. cuVS supports multiple programming languages and can be used directly or integrated into databases like Milvus. It’s also part of the NVIDIA RAPIDS ecosystem, designed to bring GPU acceleration to AI, data science and data analytics workflows. By offloading the computationally intensive indexing tasks to the GPU, cuVS can process data orders of magnitude faster than traditional CPU-based methods.
- NVIDIA L40S GPU: A powerful data center GPU designed for a wide range of workloads, including AI training, inference, and data processing. Its high core count and massive memory bandwidth make it ideal for accelerating the complex algorithms involved in vector indexing, providing the raw compute power needed to leverage cuVS effectively. The key difference when using NVIDIA cuVS is the hardware used for this computationally intensive process, which dramatically reduces the time it takes.
- NVIDIA ConnectX-7 NICs: Both the GPU and storage servers are equipped with NVIDIA ConnectX-7 NICs, which enable high-performance storage and data access with RoCE and GPUDirect®
Benefits of cuVS
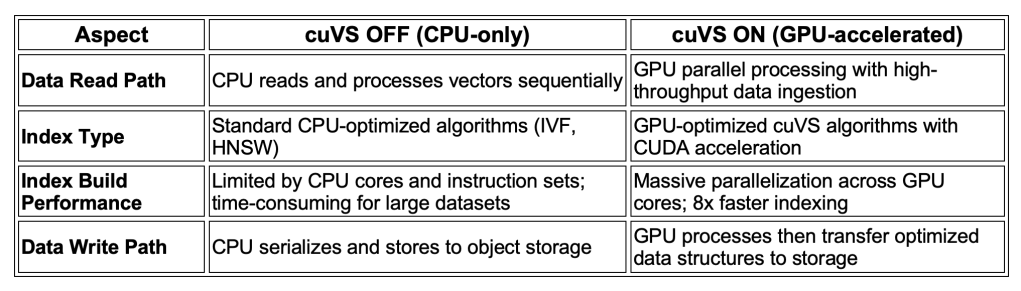
The key difference when using NVIDIA cuVS is the hardware used for this computationally intensive process, which dramatically reduces the time it takes.
Without NVIDIA cuVS
Without cuVS, Milvus performs the entire indexing process on the CPU. When you insert vectors into a collection, Milvus Index Nodes use CPU cores to:
- Cluster Vectors: Based on the chosen index type (e.g., IVF, HNSW), the CPU performs the complex calculations to group similar vectors.
- Build Graph/Index Structure: The CPU constructs the search index, such as a graph with hierarchical connections (for HNSW) or an inverted file structure (for IVF).
- Serialize and Store: Once built, the index is serialized and stored in an object storage system (like Cloudian HyperStore or AWS S3).
- This process is highly parallelized and optimized, but it is limited by the number of CPU cores, and their instruction sets. For very large datasets (millions or billions of vectors), this CPU-based index building can be time-consuming.
With NVIDIA cuVS
With NVIDIA cuVS, Milvus leverages the massive parallel processing power of NVIDIA GPUs to accelerate the indexing process. The integration with cuVS is a fundamental architectural shift that offloads the most demanding parts of indexing from the CPU to the GPU.
- GPU-Accelerated Calculations: When vectors are inserted, the Milvus Index Nodes transfer the data to the GPU.
- Parallel Index Construction: The GPU’s thousands of cores build the index structure in parallel, which is orders of magnitude faster than a CPU. This is particularly effective for graph-based algorithms like CAGRA (a GPU-native alternative to HNSW) and IVF.
- Improved Performance: Benchmarks have shown that using cuVS with a modern GPU can build indexes up to 50x faster than state-of-the-art CPU-based methods. This drastically reduces the time and resources needed for indexing large datasets.
- The final index is still serialized and stored in object storage, but the core computation is performed on the GPU meaning data is available ready for search much faster, critical for real-time applications and frequent data updates.

Benefits of Cloudian S3 RDMA enabled storage with GPUDirect
Cloudian HyperStore provides S3-compatible object storage, offering massive scalability and enterprise features. Remote Direct Memory Access (RDMA) allows one computer to directly access the memory of another remote computer, enabling seamless data movement between the two memory spaces. The data transfer occurs without requiring any involvement from the CPU on either the sending or the receiving end of the data path. The ability to bypass the CPU and the operating system kernel for data movement is what fundamentally differentiates RDMA from conventional network communication methods.
RDMA over Converged Ethernet (RoCE) is a network protocol that allows RDMA to be executed over standard Ethernet networks by encapsulating InfiniBand transport packets, which natively support RDMA, over Ethernet.
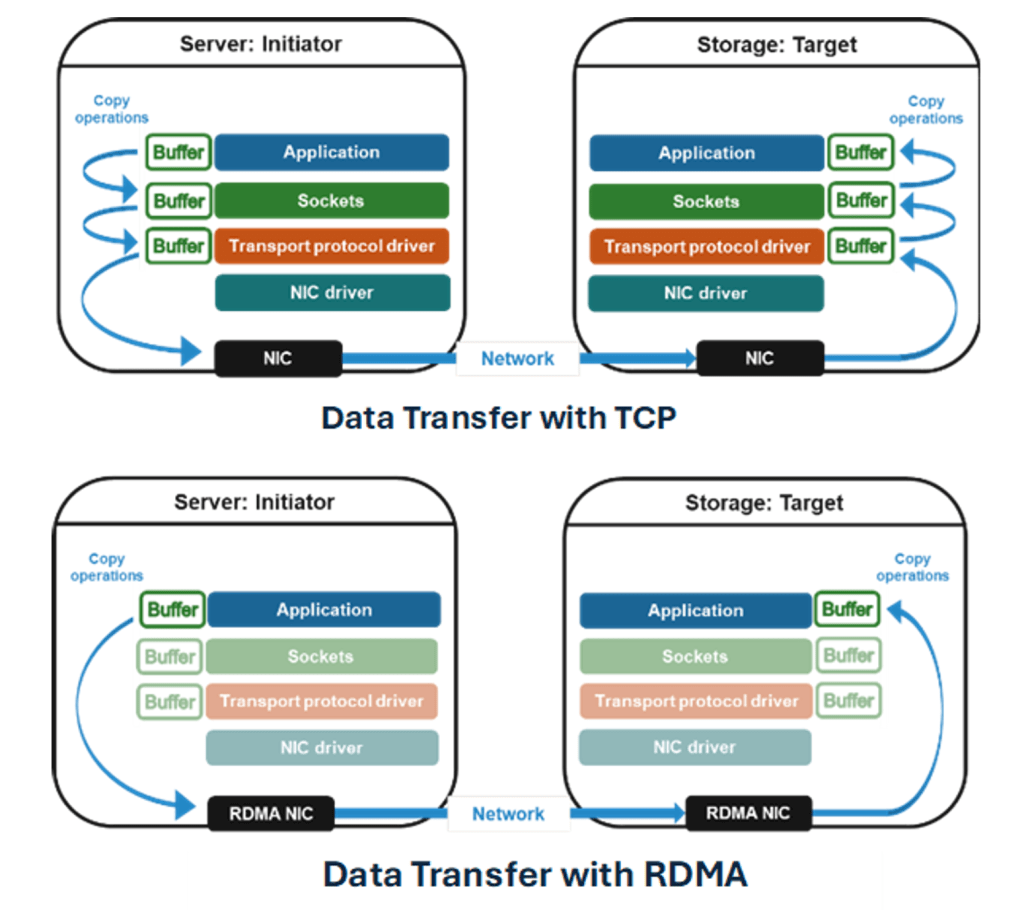

Cloudian HyperStore is the world’s first production ready storage platform to deliver S3 storage over RoCE, improving sustained throughput for data read workloads by 7 to 8X vs S3 over regular TCP. A 6-node HyperStore cluster can deliver data transfers of 210 GB/s on (35 GB/s per node), with linear performance scalability as more nodes are added to the storage cluster. Additionally, by removing the TCP processing stack from CPUs, CPU utilization drops by 40%+ on both compute and storage nodes.
With the integration of NVIDIA GPUDirect, Cloudian S3 RDMA goes one step further by bypassing the CPU and system memory entirely. Instead, it creates a direct, high-speed connection that allows data to move straight from the Cloudian object storage system to the GPU’s memory. This direct communication, sometimes referred to as “GPUDirect for Object,” dramatically increases data processing throughput, reduces latency, and frees up the CPU to focus on other tasks, leading to faster query response times for inferencing workloads.
Test setup
The test environment included a single compute node configured with 2 Intel Xeon Gold 6448Y 32 Core CPU and 2 NVIDIA L40S GPUs as a point of comparison between the two processor’s capability for a vector indexing workload. A 6 node Cloudian HyperStore cluster was deployed on servers that were configured with ConnectX-7 NICs and SSD drives to ensure storage media was not a bottleneck for the testing.
The compute and storage platforms were interconnected with a NVIDIA Spectrum-4 switch which provides port throughput of 800Gb/s.
Test dataset
The MIRACL (Multilingual Information Retrieval Across a Continuum of Languages) corpus is a large-scale, multilingual dataset for ad-hoc information retrieval. The dataset covers 18 diverse languages, ranging from high-resource languages like English and Chinese to lower-resource ones like Swahili and Telugu. It consists of human-annotated relevance judgments for queries over a corpus of Wikipedia articles.
The purpose of MIRACL is to serve as a benchmark for training and evaluating retrieval models, with the goal of improving search capabilities for diverse populations and spurring research on multilingual retrieval and cross-lingual transfer. For full information and access to the MIRACL data set please visit https://huggingface.co/datasets/miracl/miracl-corpus
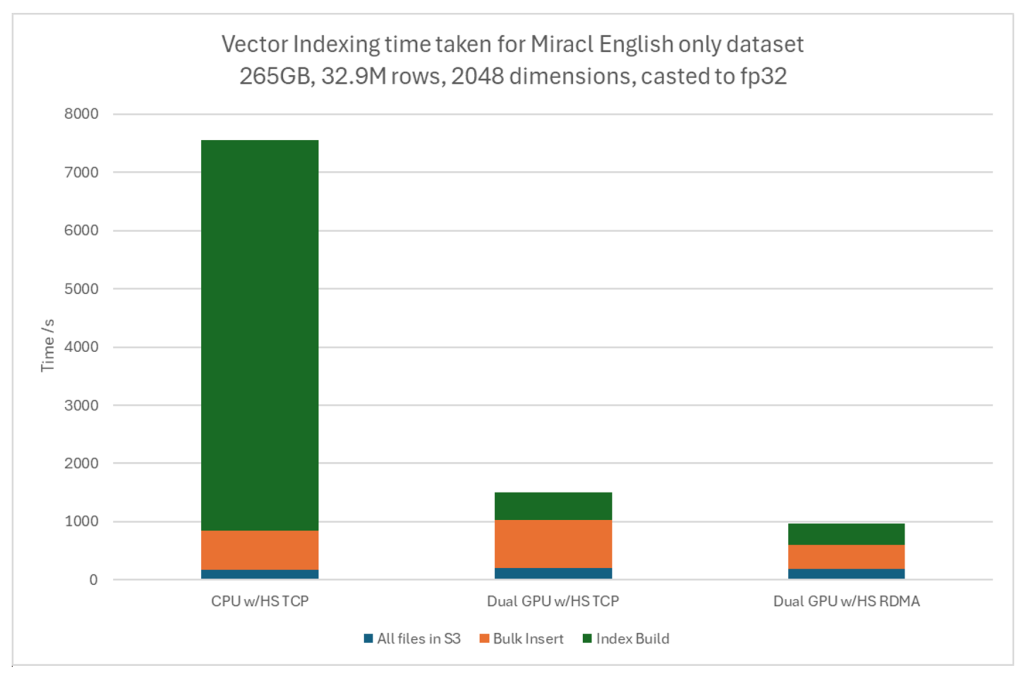
The English language version of the MIRACL dataset was used – 265GB, 32.9M rows, 2048 dimensions, casted to fp32
The NVIDIA NeMo Retriever embedding model was used to convert the raw text data to vectors for storage and retrieval in the Milvus database.
Results
English language MIRACL dataset
- GPU Performance: By switching the index build from 2 x 32 core CPUs to 2xL40S GPU resulted in a 16x reduction in Index Build Time (6685s vs 410s); 6x reduction in E2E indexing time.
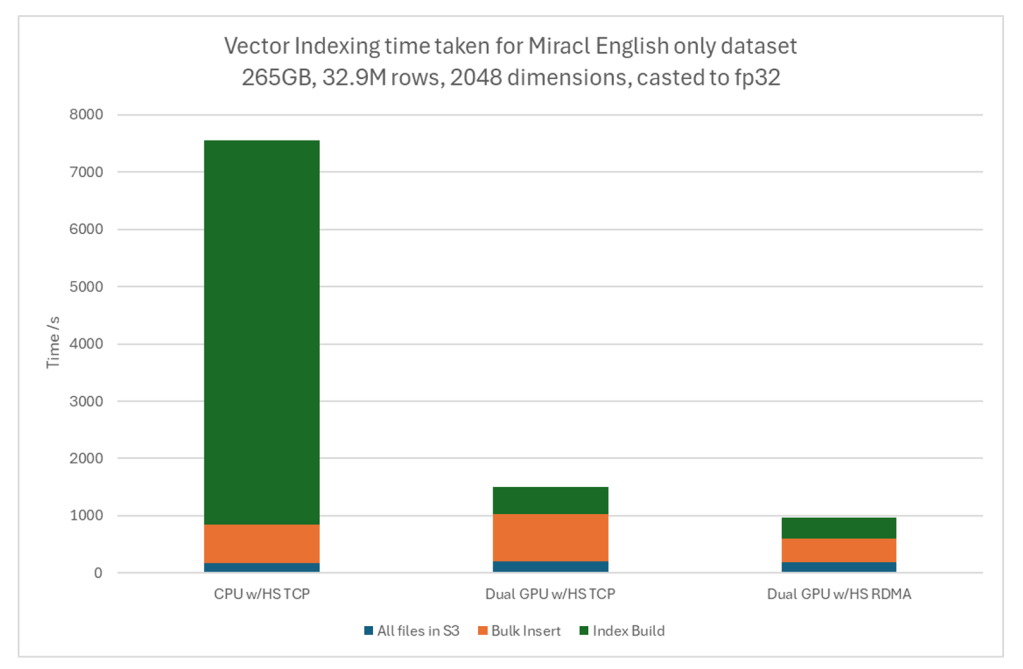

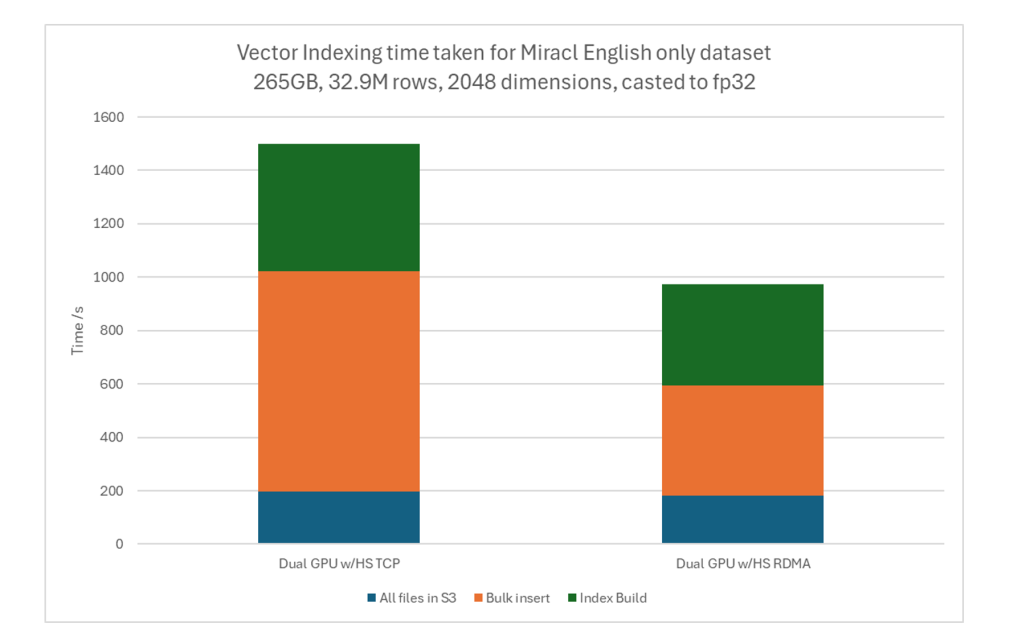
2. RDMA Performance: By switching to RDMA from TCP for GPU Indexing, a 1.5x reduction in data ingestion time (Data ingestion was the bottleneck for GPU Indexing which we have relieved with RDMA).

Summary
The combination of these technologies creates a formidable indexing pipeline:
- High-Speed Data Ingestion: Raw data is stored on Cloudian S3 with RDMA. When new data arrives for indexing, the RDMA capability ensures that this data is transferred to the compute nodes with minimal latency and maximum bandwidth. This eliminates the storage I/O bottleneck often seen in high-volume data pipelines.
- GPU-Accelerated Indexing: Once the data reaches the compute nodes, the vector embedding generation (if not already done) and the subsequent Milvus indexing process are handed over to the NVIDIA L40S GPUs. NVIDIA cuVS takes full advantage of the L40S’ parallel processing capabilities, accelerating the index construction phase dramatically.
- Efficient Milvus Integration: The Milvus vector database seamlessly integrates with this accelerated pipeline. It leverages the fast storage provided by Cloudian S3 for persisting the indexed data and benefits directly from the speed of the GPU-accelerated index creation. This allows Milvus to rapidly ingest and make new data available for similarity queries.
The result is an 8x reduction in indexing time, transforming what could be hours of processing into minutes. This not only makes real-time data integration feasible but also significantly lowers the operational costs associated with maintaining large-scale vector search systems by optimizing compute resource utilization. Organizations can now empower their applications with fresher data, leading to more accurate recommendations, more relevant search results, and faster insight.