

Supporting Multiple Tenants with Bucket-Level Object Storage Policies
The ability to create and manage multiple control plane configuration sets (or storage policies) is needed to support multiple tenants and use cases in an object storage system. Cloudian’s HyperStore object storage software supports multiple, bucket-level storage policies as a fundamental architectural principle. The following sections describe some design choices we made in how to manage and use those storage policies.
Why Bucket-Level Storage Policies
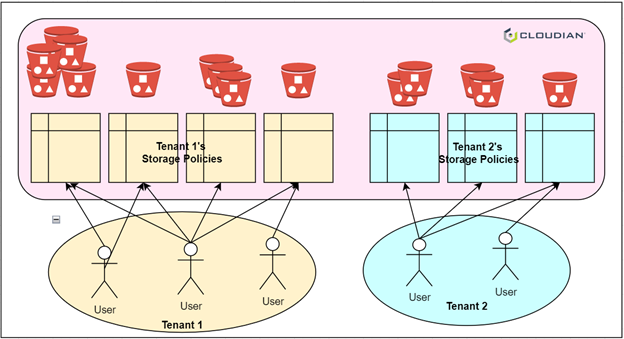
Figure 1: Multiple, bucket-level storage policies
In object storage systems (e.g., Amazon S3), there are two main concepts to organize data: objects and buckets. Objects, such as text files, images, videos, etc., are the data to be stored. Buckets are containers for objects used to group objects together. When creating a new object, the user specifies the bucket to use. Each object belongs to exactly one bucket. Applying an operation to a bucket can affect all the objects in that bucket. For example, access control settings on a bucket dictate user access to the objects in the bucket.
|
{ “Version”:”2012-10-17″, “Statement”: [ { “Sid”:”GrantAnonymousReadPermissions”, “Effect”:”Allow”, “Principal”: “*”, “Action”:[“s3:GetObject”], “Resource”:[“arn:aws:s3:::awsexamplebucket1/*”] } ] } |
Figure 2: An example bucket policy that grants anonymous GET Object access to the bucket “awsexamplebucket1”. From Overview of managing access – Amazon Simple Storage Service
In addition to the data plane of operations on objects and buckets such as storing an object, there are control plane operations that determine how that data is managed on the system. When the object storage system is managed directly by the user, the user must determine the control plane configuration settings. For example, a replication policy on the number of object replicas stored can be set for the system. There are many other control plane configurations for data, including compression type, encryption, geo-distribution across availability zones and regions, data consistency level, and more.
Legacy object storage systems support a single, static control plane configuration for the data. However, for users that want to use objects for different purposes, a single configuration is insufficient. For example, the same user may have a use case that requires strong consistency, such as data used for transactions, while another use case – such as historical log data – can be stored with eventual consistency. Another common situation is that the storage system may have multiple tenants where each tenant has different requirements on data durability and availability. In addition, both the use cases and the tenants may change over time. Having the option to create new storage policies to match the changing use of the storage system is critical.
Assigning a Storage Policy to Data
One of the first questions we addressed was how should a storage policy be assigned to data. Because the primary concepts of an object storage system are simply an object and a bucket, those two concepts were considered. If object granularity were used, then each object can be assigned to its own storage policy. This can be set in an HTTP header when the object is uploaded, e.g, “x-amz-storage-policy: eu4policy”, but this requires the client to know the different storage policies. It also makes comprehending the different storage policies more difficult because each object, even different versions of the same object, may have different storage policies.
Alternatively, assigning a storage policy to a bucket is a good cognitive fit because buckets are already used to group objects together. Then the workflow is when a bucket is created, a storage policy is selected for the bucket and applied to all objects to be created in the bucket. A user can then split their data by storage policies by selecting a bucket and creating a new bucket if a different storage policy is warranted. These considerations made it clear that a per-bucket or bucket-level storage policy was the best choice.
The Configuration Content of a Storage Policy
Some control plane configuration settings were mentioned earlier. The tradeoff was to avoid having an overly verbose and complex policy by including every setting vs. providing enough control to the user to be useful. In this case, user feedback was needed to understand how they wanted to use multiple storage policies. We interviewed several existing users for this purpose. Some configuration settings were unanimously cited, including replication strategy (replicas or erasure coding, number of fragments, geo-distribution) and data consistency level (read, write, multiple availability zones). One interesting learning was that users wanted flexibility to handle use cases that were not yet known. As a result, the set of configuration settings grew over time as more control to handle new use cases was requested.
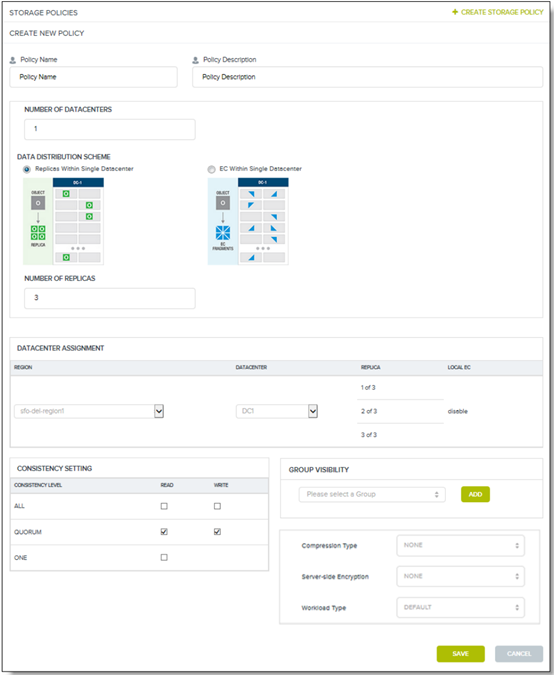
Figure 3: Creating a new storage policy
Managing a Storage Policy
When it came to managing a storage policy, considerations included how to create, view, edit, and delete storage policies, how to manage access, and how to present this capability in an easy-to-use, functional user experience. An HTTP API was first designed that provided all the functionality to manage both a single storage policy and multiple storage policies. Then various iterations of a user interface were developed. The user interface was allowed to only use the existing API. This ensures that users can develop their own software to use the API and have full functionality.
Bringing It All Together
An illustrative example of multiple, per-bucket storage policies is a hub-and-spoke model where the hub is a central data center and multiple satellite offices are connected to the hub by the spokes as depicted in Figure 4. A large satellite office (DC1) is configured with a storage policy that stores 3 replicas of each object in the satellite office data center and 1 replica in the central data center (DC0). A small satellite office (DC2) is configured with a storage policy with 1 replica in the satellite office and 1 replica in the central data center.
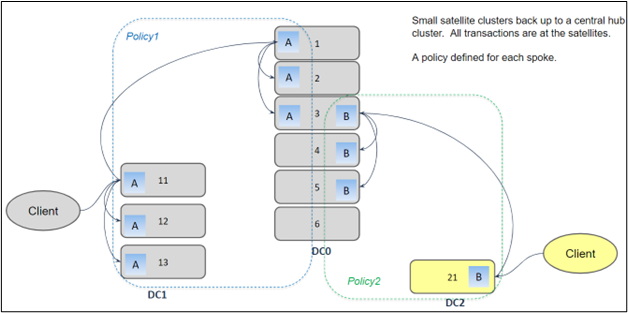
Figure 4: Storage policies for a hub-and-spoke model
Next Steps
The bucket-level storage policies functionality has been an important discriminator of Cloudian’s HyperStore object system. It “future-proofs” the system since new users and groups and new use cases can be accommodated by adding new storage policies to a running system.
Future work includes how much flexibility is allowed to change existing storage policies that may already apply to millions of objects and to associate different billing rates to different storage policies.
For further information on Cloudian HyperStore and its multiple storage policies, please request a demo or download a free trial.


Gary Ogasawara, CTO, Cloudian