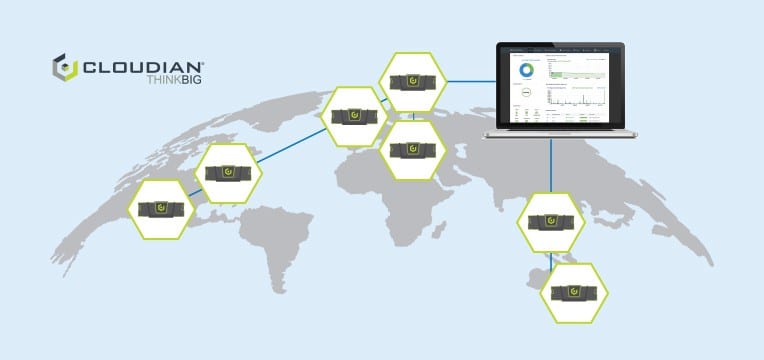
Geo-Distribution
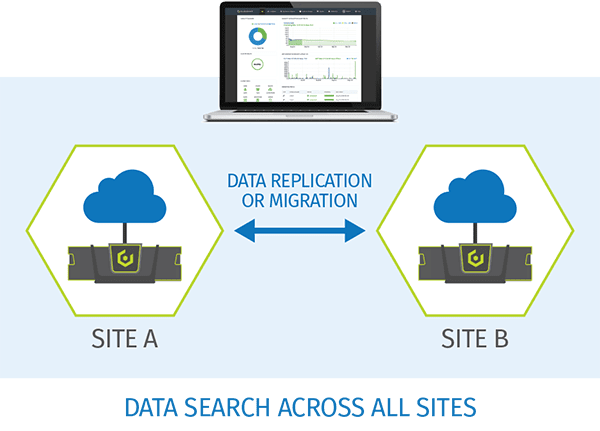
Für kapazitätsintensive Arbeitslasten benötigen die Benutzer schnellen, lokalen Datenzugriff. Die globale Datenstruktur von Cloudian ermöglicht dies auf unkomplizierte Weise mit Speicherknoten, die an jedem beliebigen Standort implementiert werden können. Platzieren Sie Speicherknoten in der Nähe von Datennutzern oder -quellen, um die Latenz, den Netzwerkverkehr zu minimieren und den Durchsatz zu maximieren. Replizieren Sie Daten an andere Standorte, mit dem gewünschten Maß an Konsistenz. Egal ob für die Datenerfassung, -verteilung oder -sicherung: Mit Cloudian können Sie Speicher dort bereitstellen, wo Sie ihn brauchen.

Implementierungsoptionen für jeden Standort
Wählen Sie die für den jeweiligen Standort am besten geeignete Speicherplattform. Zur Auswahl stehen vorkonfigurierte Appliances, Software-definierter Speicher auf dem Server Ihrer Wahl oder virtuellen Maschinen. Unabhängig von Ihrer Implementierung arbeiten alle Cloudian-HyperStores als zentraler, gemeinsamer Speicherpool.
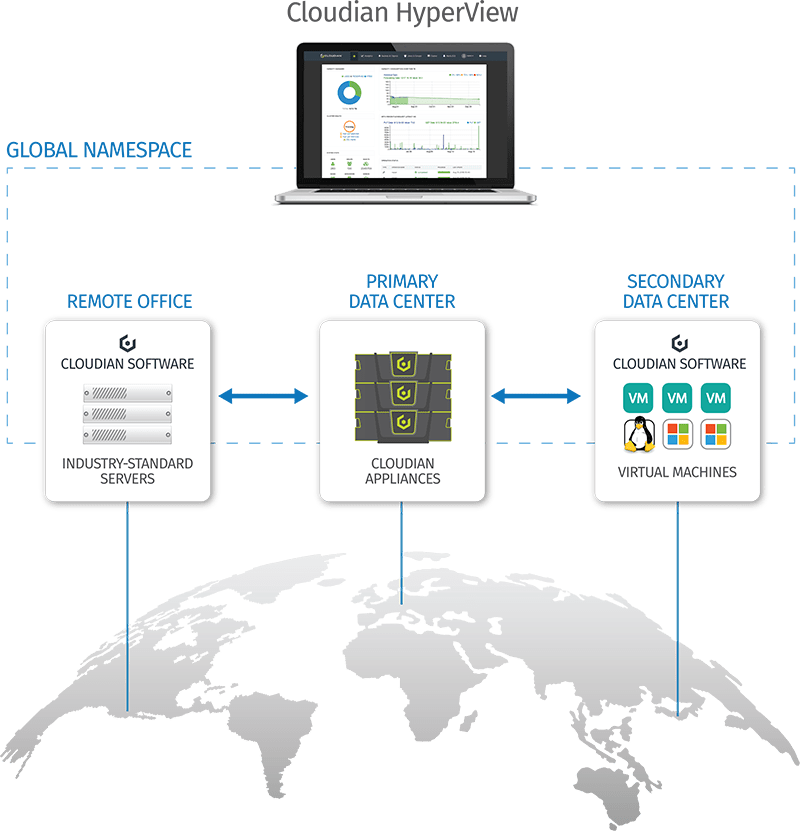

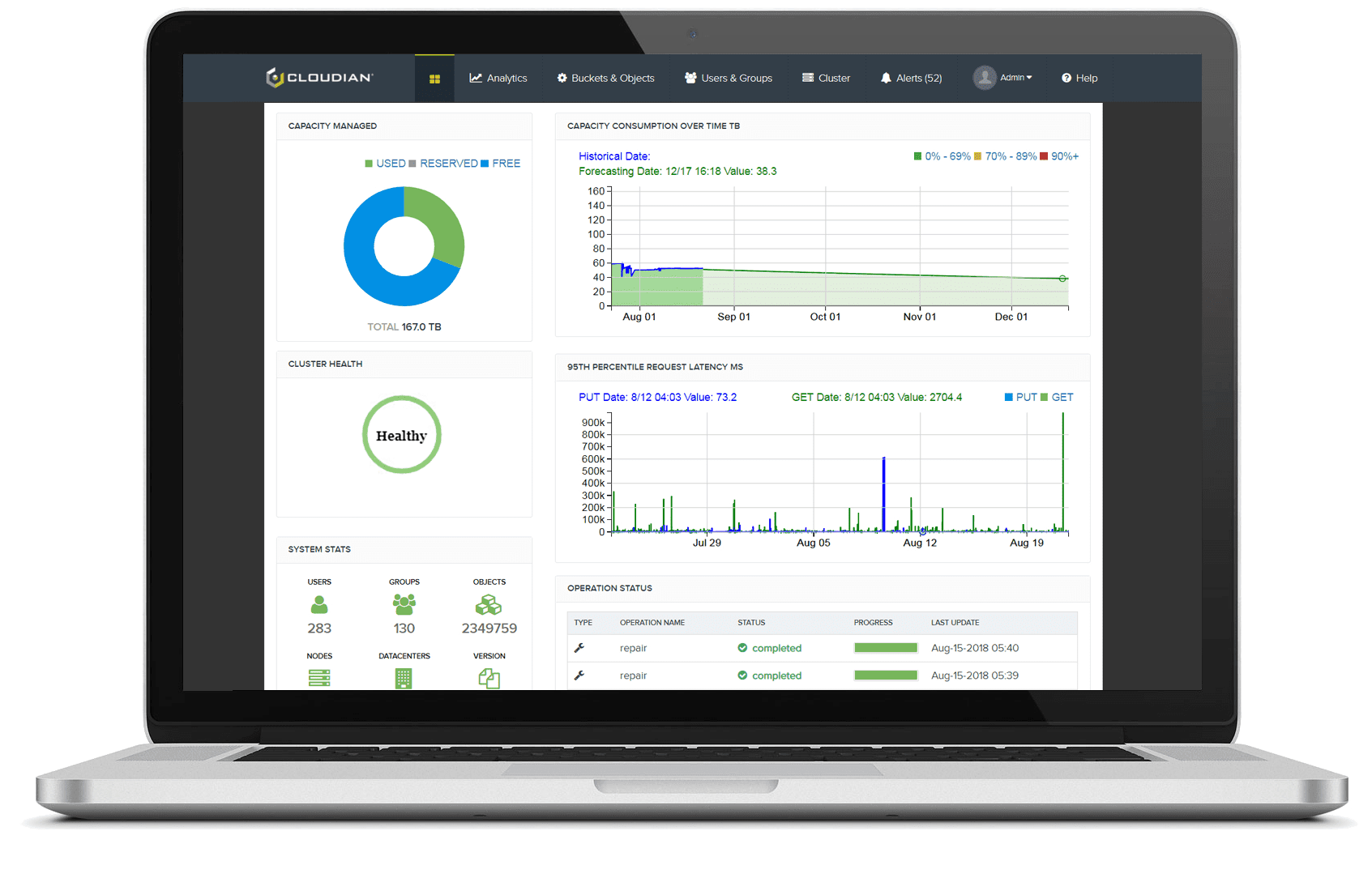

Zentrale Datenansicht über mehrere Standorte hinweg
Durchsuchen Sie Daten und zeigen Sie diese standortübergreifend von einem zentralen Bildschirm aus an. Mit Cloudian können Sie Speicheransichten basierend auf logischen, statt physischen Grenzen festlegen. Mittels Richtlinienverwaltung auf der Bucket-Ebene können Sie die Anforderungen für jeden Datentyp festlegen. Erstellen Sie Richtlinien für Datenreplikation, -sicherung und -konsistenz für verschiedene Anwendungsfälle.
Integrierte Datenverwaltungstools
Verwalten Sie die Datenmigration, -replikaktion und -suche mit einfachen und integrierten Tools. Cloudian ermöglicht die zentrale Verwaltung, Suche und Sicherung von Informationen anhand richtlinienbasierter Tools und Elasticsearch-Integration über mehrere Standorte hinweg.



Test in der Google Cloud
Lernen Sie die Funktionen von Cloudian HyperStore kennen, darunter:
- Erstellung und Verwaltung Ihrer Daten
- Festlegen und Testen von Speicherrichtlinien
- Einrichtung einer granulären Datensicherung auf Bucket-Ebene anhand von Erasure Coding (EC 4+2) und Replikation (RF3)
- Verwaltung Ihrer Daten mit einem einzigen globalen Namensraum
- Bedarfsgerechte Skalierung Ihrer Umgebung, um Leistungsziele zu erfüllen
WGBH Boston
Aktives Hybrid-Cloud-Archiv mit digitalen Inhalten
![]()