
What Is Storage for AI and Analytics?
AI and analytics storage solutions require high-performance, scalable, and durable infrastructure to manage massive, rapid data ingestion, training, and inference needs. Key solutions include high-speed NVMe/flash-based storage for training, data lakes for massive datasets, and hybrid cloud storage. Key providers like Cloudian, Pure Storage, and WekaIO provide specialized solutions for these workloads.
The demands of AI and analytics force storage technologies to handle diverse data formats, from massive image repositories to real-time sensor streams. As organizations train complex models or run analytics jobs requiring frequent access to petabytes of data, the storage layer must deliver both high throughput and low latency. This specialized storage ensures data scientists and applications can work with the data at the required speed and scale
Key storage architectures for AI/analytics:
- Object storage: Essential for storing unstructured data (images, videos, text) used in AI training, often using S3-compatible APIs for scalability
- Distributed file storage: Enables parallel access to data, critical for high-performance computing (HPC) and training large models
- NVMe/flash storage: Provides the, required for feeding data to GPUs without bottlenecks
- Data lakehouses: Combine the flexibility of data lakes with the performance of data warehouses
This is part of a series of articles about AI infrastructure
In this article:
- How AI and Analytics Workloads Stress Storage Systems
- Key Storage Architectures for AI/Analytics
- Notable Storage Solutions for AI and Analytics
- Best Practices for Deploying Storage for AI and Analytics
How AI and Analytics Workloads Stress Storage Systems
AI and analytics workloads impose unique and intensive demands on storage infrastructure. These workloads are not only data-hungry but also require high-speed, parallel access to massive datasets. Below are the key ways these workloads stress storage systems:
- High data volume: AI and analytics systems often work with petabytes of data, including images, video, logs, and sensor outputs. Traditional storage systems are not designed to ingest or manage such volumes efficiently, leading to performance bottlenecks.
- Unstructured and diverse data types: Unlike structured transactional data, AI workloads rely heavily on unstructured data (text, images, audio, etc.) that require different storage formats and indexing strategies. Supporting diverse file types increases metadata complexity and demands flexibility from the storage backend.
- Random and parallel access patterns: Model training and analytics queries frequently access data in non-sequential patterns and from multiple nodes in parallel. This places pressure on IOPS (input/output operations per second) and demands low-latency performance across the entire dataset.
- Iterative and repetitive Reads: During model training, the same dataset may be read repeatedly over many epochs. Inefficient storage systems can become a bottleneck, increasing job runtimes and reducing GPU utilization.
- High throughput requirements: Feeding data into distributed computing environments, especially when using accelerators like GPUs, requires sustained throughput to avoid idle compute resources. Storage systems must deliver consistent performance even under concurrent access.
- Scalability and elasticity: As data grows or training jobs scale out, the storage infrastructure must grow accordingly without manual intervention. Inflexible systems may require costly upgrades or downtime to expand.
- Data lifecycle and tiering challenges: AI workflows involve multiple data stages, from raw ingestion to processed outputs to archived results. Managing the lifecycle and moving data between hot, warm, and cold tiers can create complexity without proper automation.
Key Storage Architectures for AI/Analytics
Object Storage
Object storage is a popular choice for AI and analytics because it is designed to manage vast amounts of unstructured data with flexible scalability and durability. Each object is stored along with its metadata and a unique identifier, which makes managing billions of files easier.
This architecture is especially useful for storing image, video, genomic, or log data that doesn’t fit neatly into filesystems or databases. Its flat namespace enables efficient horizontal scaling and high availability, which is critical for uninterrupted AI training and analytics. Modern object storage solutions also offer integrations with data processing platforms and can be deployed on-premises or in the cloud.
Distributed File Storage
Distributed file storage systems are engineered to provide high-speed, concurrent access to shared datasets across clusters of compute nodes. By distributing files and directories over many servers, these architectures enable parallel data processing without centralized bottlenecks.
This approach is commonly used in environments where multiple GPUs or servers process overlapping files, such as in large-scale ML training or data analytics workflows. Scalability is built into their design, making it possible to add capacity and throughput by simply adding nodes.
NVMe/Flash Storage
NVMe (Non-Volatile Memory Express) and flash-based storage introduce significant performance gains for AI and analytics by providing ultra-low latency and exceptionally high throughput. These storage systems are designed to serve data directly to high-speed CPUs or GPUs with minimal delay, drastically reducing job training or query time.
By using parallelism offered by flash memory and direct PCIe connections, NVMe storage can feed data to even the fastest compute hardware without becoming a bottleneck. This technology is especially useful for workloads requiring rapid access to large data batches, such as deep learning model training or interactive analytics on big data.
Data Lakehouses
Data lakehouses blend the cost-effective scalability of data lakes with the robust management, reliability, and transactional features of data warehouses. This unified architecture allows organizations to store massive volumes of raw and processed data in a single system, making it readily available for both AI and analytics use cases.
Lakehouses, such as those based on Apache Iceberg, Delta Lake, or Databricks, support a variety of data formats and provide ACID transactions, which ensure data consistency across complex data pipelines. Lakehouses remove traditional barriers between structured and unstructured data, enabling seamless queries and interactive analytics while supporting direct machine learning workflows.
Notable Storage Solutions for AI and Analytics
1. Cloudian
![]()

Cloudian HyperStore is a native S3-compatible object storage platform designed to serve as the scalable foundation for enterprise AI and large-scale analytics. As AI workloads move from experimental to production, HyperStore provides the necessary exabyte-scalable data lake for ingesting, storing, and managing the massive volumes of unstructured data—images, video, and text—required for model training and Retrieval-Augmented Generation (RAG) workflows. By offering a shared-nothing, peer-to-peer architecture, Cloudian ensures that both capacity and performance scale linearly, allowing organizations to maintain absolute data sovereignty by keeping sensitive training sets behind the corporate firewall.
Eliminating GPU Starvation with All-Flash Performance A primary challenge in AI storage is providing enough throughput to keep high-cost GPUs utilized. Cloudian addresses this with all-flash NVMe configurations that deliver the low-latency, high-IOPS performance needed for fast model loading and iterative training cycles. By leveraging S3 RDMA and advanced metadata handling, HyperStore enables data science teams to execute complex analytics and inference tasks without the bottlenecks common in legacy storage or high-latency public cloud environments.
Foundational Storage for RAG and Vector Databases For organizations deploying AI agents and generative models, HyperStore acts as the high-durability repository for both raw source data and the resulting vector embeddings. Its deep integration with the S3 API allows for seamless connectivity with vector databases and AI frameworks, ensuring that the “long-term memory” of the AI system is secure, searchable, and always available. This architecture is particularly vital for regulated sectors like finance and healthcare, where data residency and immutable audit trails are non-negotiable.
Key features include:
- Native S3 API compatibility: Provides the industry-standard interface for all major AI/ML frameworks (TensorFlow, PyTorch) and analytics engines, ensuring seamless data portability and integration.
- Exabyte-scale flash storage: Supports massive data ingestion with all-flash NVMe performance, specifically engineered to eliminate I/O bottlenecks and maximize GPU utilization.
- Military-grade security and sovereignty: Built-in S3 Object Lock for WORM (Write Once, Read Many) immutability, FIPS 140-3 validation, and granular access controls to protect proprietary training data and intellectual property.
- Unified global namespace: Enables a single control plane to manage data across multiple sites, edge locations, and hybrid cloud environments, facilitating automated data tiering and lifecycle management.
- Shared-nothing architecture: Ensures high availability and linear scalability, allowing organizations to add nodes non-disruptively as AI datasets grow from petabytes to exabytes.
2. Pure Storage FlashBlade


FlashBlade//S is a scale-out, all-flash storage system optimized for unstructured data workloads across AI, analytics, and high-performance computing (HPC). Built on a modular architecture, it allows organizations to scale performance and capacity independently, avoiding the limitations of legacy systems. FlashBlade//S delivers low-latency, high-throughput file and object storage in a single platform.
Key features include:
- Unified file and object storage: Supports both access types in a single high-performance system, suitable for diverse AI and analytics workloads
- Modular scale-out Design: Enables independent scaling of performance and capacity with minimal disruption or waste
- All-QLC DirectFlash® architecture: Delivers high density and throughput with low power consumption
- Zero move tiering: Eliminates complexity of traditional data tiering, improving efficiency and lowering TCO
- Evergreen//Forever™ upgrades: Offers automatic, non-disruptive hardware and software updates to extend system life


3. WEKA Storage


WEKA is a GPU-optimized data platform to accelerate AI inference workloads by delivering low latency and high IOPS. Its architecture enables fast model loading, efficient GPU utilization, and end-to-end support for inferencing tasks. By combining a distributed design with native support for file and object storage, including S3, WEKA provides performance and scalability for real-time inference at scale.
Key features include:
- Low latency and high throughput: Accelerates inference pipelines with fast, consistent data access
- GPU-optimized architecture: Reduces data delivery bottlenecks and improves GPU utilization for efficient model execution
- Unified file and object storage: Native support for S3 and POSIX simplifies integration into AI/ML pipelines
- Scalability: Scales across on-prem, cloud, and hybrid environments without performance degradation
- Simplified data management: Unifies compute and storage layers for streamlined inferencing workflows
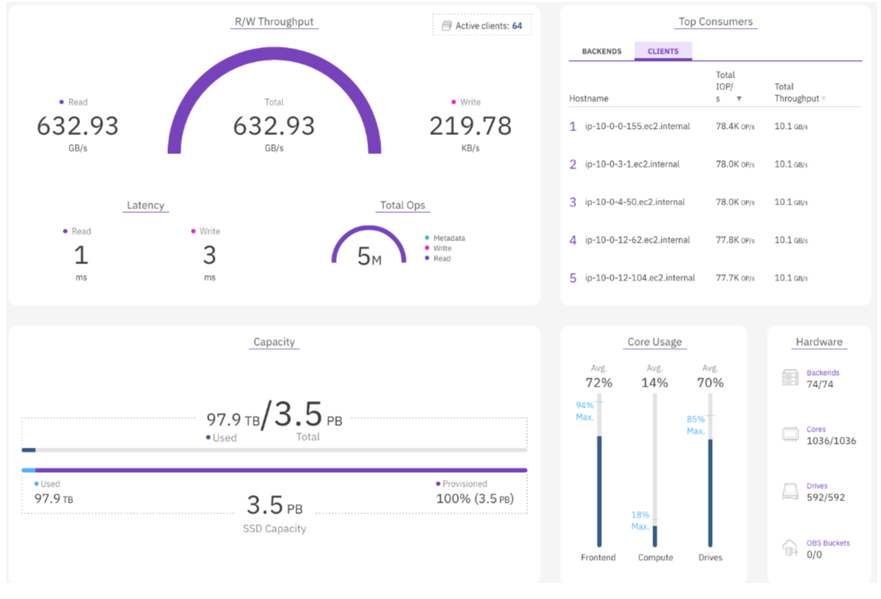

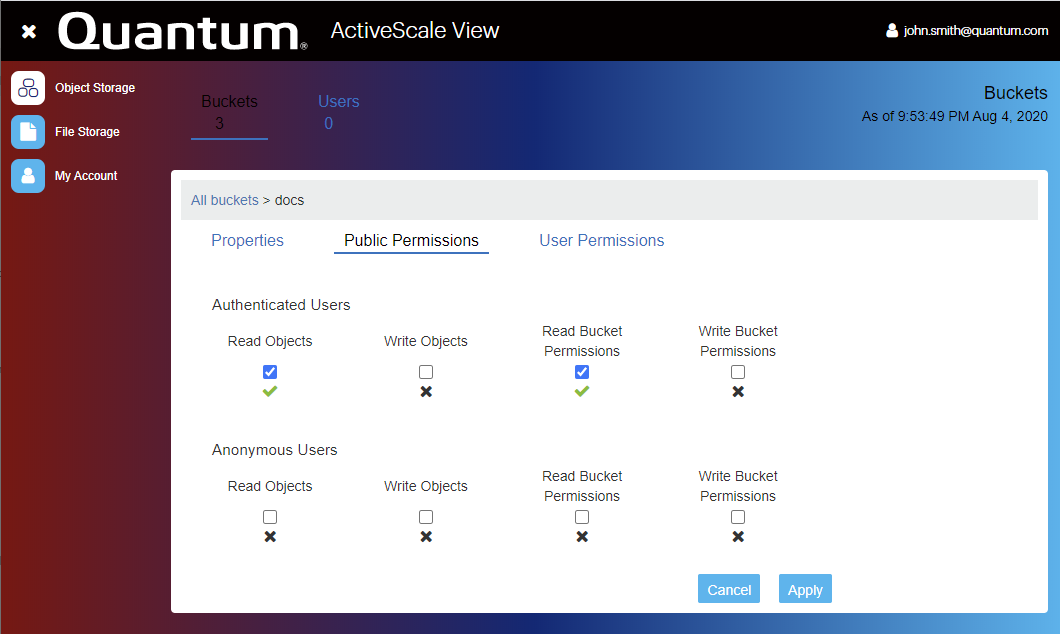
4. Quantum ActiveScale


Quantum ActiveScale is a scalable object storage platform that unifies active and cold data in a single namespace. It is optimized for AI, analytics, backup, and archival workloads that demand long-term accessibility and protection. It integrates object storage with a native, S3 Glacier-compatible cold tier, simplifying data lifecycle management.
Key features include:
- Unified active and cold storage: Manages both hot and archival data in one platform with a shared namespace
- Patented 2D erasure coding: Delivers up to 19 nines durability while reducing resource overhead compared to traditional multi-copy methods
- S3 Glacier-compatible cold tier: Enables cost-efficient long-term retention with full cloud compatibility
- Enterprise-grade security: Offers object immutability, per-object encryption, IAM controls, MFA, and air-gapped storage for ransomware protection
- Scalability: Scales from TBs to EBs with dynamic data placement and no rebalancing during expansion

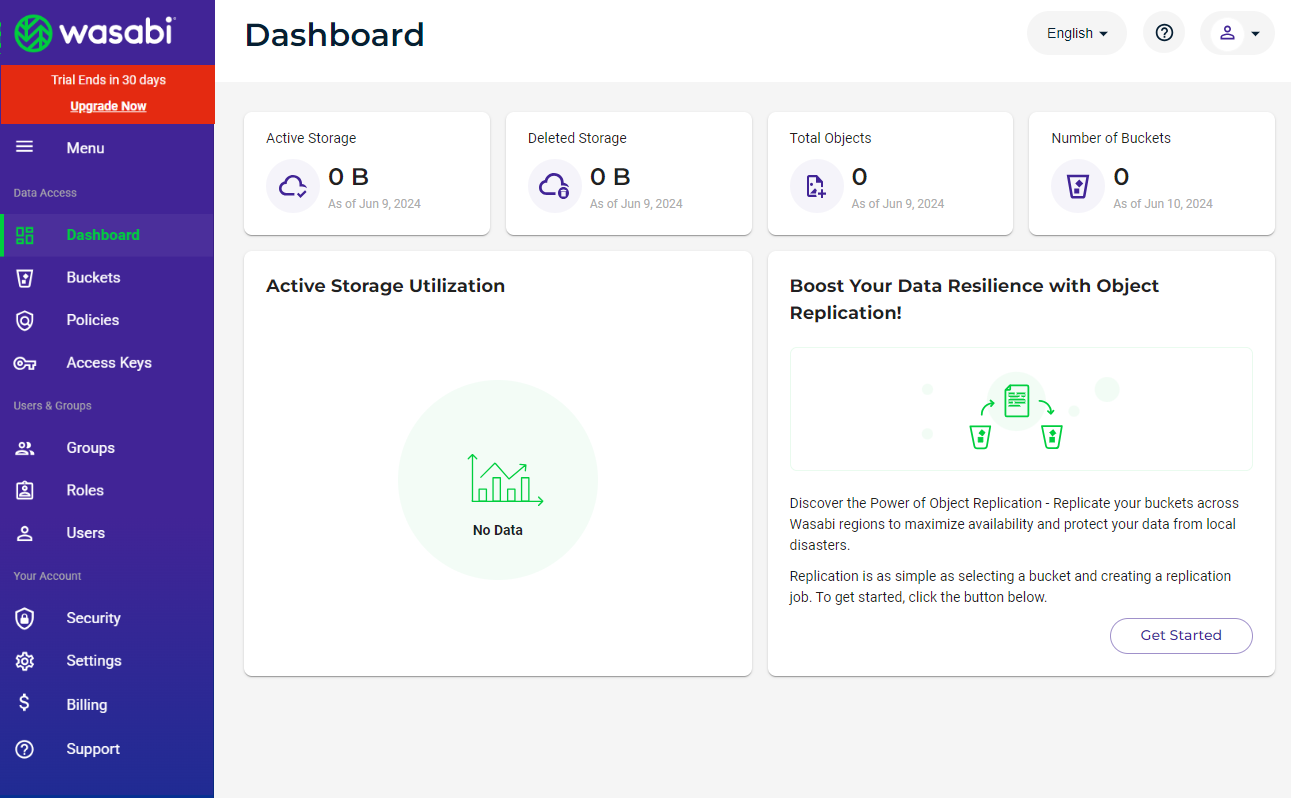
5. Wasabi AI Storage
![]()

Wasabi provides scalable, high-performance cloud object storage to support AI workloads from data ingestion to long-term model archiving. Designed for both structured and unstructured data, Wasabi enables fast access to datasets across the AI pipeline. Its S3-compatible platform integrates with popular AI/ML tools and infrastructure, while offering features like immutability and virtual air gapping.
Key features include:
- High-performance object storage: Supports low-latency access and up to 100 Gbps direct connect for fast training and inference
- Scalable and cost-predictable: Stores petabytes of AI data with flat-rate pricing and no egress or API fees
- Workflow integration: Seamlessly connects to AI/ML platforms and tools using standard S3 APIs
- Immutable archives for compliance: Ensures retention of model versions and input data for auditing and regulatory needs
- Security and data protection: Offers virtual air gapping, data immutability, and account-level security for sensitive workloads

Related content: Read our guide to AI storage
Best Practices for Deploying Storage for AI and Analytics
Here are some useful considerations when setting up a storage system for AI and analytics workloads.
1. Align Storage Architecture with Workload Patterns
Selecting the right storage architecture requires a deep understanding of how workloads will access data across the AI and analytics lifecycle. For example, workloads that require massive parallel reads benefit from distributed file systems, while those focused on object-based archiving or unstructured data analysis are best served by object storage.
Evaluating performance demands, concurrency needs, and access patterns enables organizations to avoid bottlenecks and maximize infrastructure ROI. It is also important to anticipate scaling, both in terms of data growth and compute expansion. Aligning storage selection with the characteristics of model training, feature engineering, and real-time analytics ensures that storage does not become a limiting factor.
2. Separate Hot, Warm, and Cold AI Datasets
AI and analytics pipelines often generate data that varies in usage frequency and performance requirements. Separating “hot” data (actively processed or frequently accessed) from “warm” and “cold” data ensures storage costs and infrastructure performance are optimized.
Hot datasets, such as training samples or features in active development, belong on high-performance storage like NVMe or flash arrays. Warm data, often required for on-demand analytics, can reside on less expensive but still performant storage tiers, while infrequently accessed cold data should be archived on high-capacity, cost-efficient platforms.
Implementing clear tiering strategies simplifies management as data volumes and project portfolios expand. Automated policy-driven data movement between tiers can further enhance efficiency, ensuring that the most valuable data is always available for analytics jobs or AI retraining without unnecessarily consuming premium storage resources.
3. Minimize Data Movement Across Pipelines
Excessive data movement can introduce bottlenecks, increase latency, and drive up infrastructure costs. To minimize these issues, organizations should design AI and analytics pipelines that reduce the need to copy or transfer data between storage platforms and environments.
Using integrated storage solutions that support multiple protocols and direct access for compute nodes allows for seamless data processing without unnecessary staging or manual transfers. Centralizing data in unified or tiered storage architectures, such as lakehouses or scalable object stores, enables diverse workflows to access the same data without redundant copies.
4. Plan for Metadata Scalability Early
AI and analytics workloads are heavily dependent on metadata for efficient data discovery, access management, and pipeline automation. As datasets and project teams grow, the scalability of metadata systems often becomes a limiting factor for performance and manageability. Planning for metadata handling from the outset (in both object and file storage architectures) prevents future slowdowns.
Effective metadata management involves selecting storage systems with high-performance metadata engines and integrating metadata services with ML/data catalog tools. This makes it possible to track lineage, control permissions, and automate lifecycle or policy-driven actions, all of which are crucial for regulatory compliance and reproducibility in AI workflows.
5. Continuously Monitor Performance and Utilization
Continuous monitoring is key to maintaining optimal storage performance as AI and analytics demands evolve. Implementing real-time tracking of I/O metrics, throughput, latency, and capacity utilization enables proactive identification of bottlenecks or hardware failures. This data-driven visibility allows teams to adjust provisioning, rebalance workloads, or plan expansions before issues impact job completion times or user experience.
Using integrated monitoring tools and setting automated alerts ensures problems are addressed quickly, minimizing downtime and protecting investments in costly compute resources. Over time, monitoring also provides insights into workload patterns and trends, guiding further optimizations in storage configuration or tiering strategies.
Related content: Read our guide to AI workloads
Conclusion
Storage for AI and analytics must balance performance, scalability, durability, and cost across a wide range of workload patterns. From high-throughput model training to long-term dataset retention, the storage layer directly affects GPU utilization, job completion times, and overall infrastructure efficiency. By aligning architecture with access patterns, implementing clear tiering strategies, minimizing data movement, and planning for metadata and operational scale, organizations can build storage environments that support sustained innovation.