
What Is AWS S3 Data Lake?
Amazon Simple Storage Service (S3) is AWS’s popular object storage solution for structured and unstructured data. It is an optimal storage service for building a data lake. Amazon S3 lets you build and adjust the scale of a secure data lake in a cost-effective manner offering 99.999999999% durability.
By building your data lake on Amazon S3, you can leverage AWS-native services for various use cases. These include AI and machine learning (ML), big data analytics, high-performance computing (HPC) workloads, and data processing apps that provide useful insights from large amounts of unstructured data.
You can use Amazon FSx for Lustre to run file systems for ML and HPC applications, process massive media workloads, and perform other actions directly from the data lake. An AWS data lake also offers the flexibility to support your chosen AI, ML, HPC, and analytics apps from Amazon Partner Network (APN).
Amazon S3 offers features that allow storage admins, data scientists, and IT managers to manage data storage and access privileges. These features help enforce data policies and support auditing processes across your S3 data lake.
In this article:
Amazon S3 as a Data Lake Storage Platform
AWS data lakes use Amazon S3 as their main storage service, leveraging S3’s high scalability and durability. S3 lets you seamlessly increase storage capacity to petabytes of data and leverage intuitive features, access control, and encryption. It also integrates with various AWS and third-party tools to ingest, process, and secure data.
Amazon S3 offers several important features for data lakes:
- Decoupled storage and data processing—a conventional data warehouse has tightly coupled storage and compute, making cost optimization harder. S3 cost-effectively stores all data types in the original format and enables scalability to support specific use cases.
- Centralized architecture—you can easily build multi-tenant environments with multiple users running different tools on the same data. This architecture is more cost-effective and promotes strong data governance.
- Data replication across regions—you can replicate objects across different buckets in your AWS account to reduce latency, improve efficiency, and ensure compliance.
- Integration with serverless tools—Amazon S3 is compatible with various services for processing and querying data. It also supports serverless computing with AWS Lambda, which processes S3 event notifications. You pay only for the data processed or the computing power used. Another tool that integrates with S3 is Amazon SageMaker, which is useful for storing training data for machine learning models.
- API standardization—S3 offers user-friendly RESTful APIs with wide support from third-party vendors like Apache Hadoop. Standardized APIs let you integrate your chosen analytics tools.
- Security by default—Amazon S3 is a secure platform with support for access controls like authentication and bucket policies. S3 also offers an Access Points feature to manage access to shared data in your data lake. You can use HTTPS to access secured data through an SSL endpoint. Server-side data encryption adds another security layer.
- Raw data and iterative data set storage—the data in a data lake often undergoes many transformations, resulting in multiple versions of one data set. Amazon S3 lets you create separate layers to store data at different pipeline stages, including logs, curated, and raw data.
- Structured and unstructured data storage—S3 is highly scalable and supports all types of data, including structured, unstructured, and semi-structured data, making it suitable for data lakes.
What Is AWS Lake Formation?
Lake Formation is a fully managed Amazon service that facilitates the building, management, and security of AWS data lakes. It helps simplify and automate the complex manual processes typically involved in creating a data lake, including data collection, cleaning, transfer, cataloging, and preparation for processing. It helps you keep your data secure while accessing it for machine learning and analytics use cases.
Lake Formation has a unique access permissions model to augment your identity and access management (IAM) strategy. This model is centrally defined, enabling granular access control for data stored in your data lake. It makes granting or revoking privileges easy, similar to relational database management systems (RDMS).
You enforce Lake Formation permissions with fine-grained controls at the row, column, and cell levels throughout AWS ML and analytics machine learning services such as Athena, QuickSight, and Redshift.
With AWS Lake Formation, you can perform various data management actions more easily. For example, Lake Formation lets you register the Amazon S3 buckets where your data lake resides. It also helps you orchestrate the data flow to ingest, transform, and arrange raw data. You can create a data catalog to store and manage metadata related to your data sources.
However, the most important function of Lake Formation is to set granular access policies to your data and metadata based on a simple permissions model.
Here is a depiction of the workflow to load and secure data using Lake Formation:
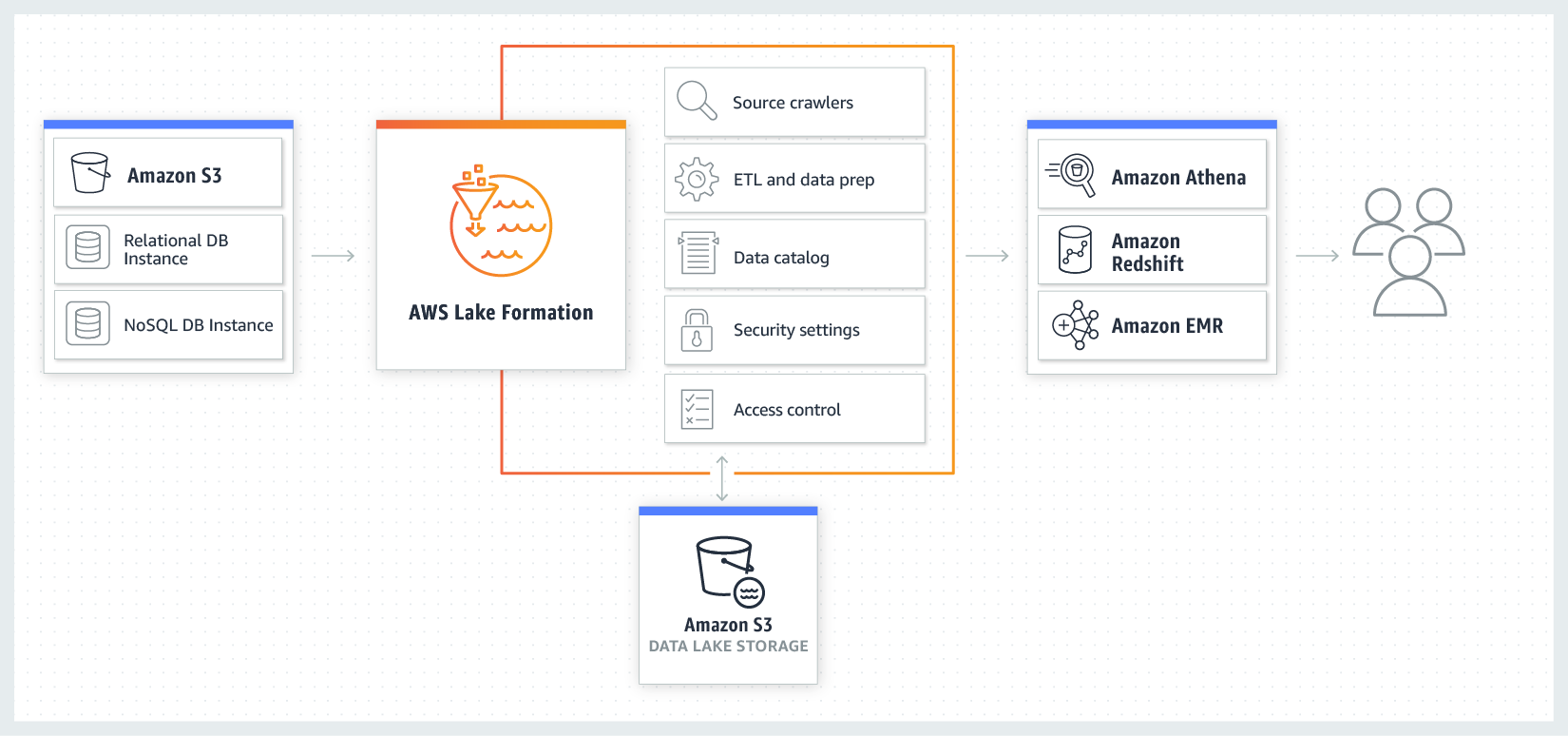

The features that Lake Formation can manage include AWS Glue crawlers, Glue ETL jobs, the data catalog, access control, and security settings. Once the data resides securely inside your data lake, you can access it with your chosen AWS analytics service (i.e., Athena, Redshift, EMR, etc.).
4 AWS Data Lake Best Practices
Use the following best practices to make the most of your S3 data lake.
1. Store Data in the Raw Format
Configure your data lake to store all raw data in the original format before transforming, cleaning, or processing the data. Storing data in raw formats allows data scientists and analysts to use the data in various ways, make novel queries, and create new enterprise data use cases.
Amazon S3 offers cost-effective and scalable on-demand scalability data storage, allowing you to retain your organization’s data in the cloud for a long time. The data you capture and store today may be useful in several months or years when addressing new problems or asking new questions.
Storing all data in the source format ensures that no details get lost. The AWS data lake thus becomes your single source of truth for all ingested raw data.
2. Optimize Costs with Storage Classes
Amazon S3 offers several cloud storage classes to help you optimize costs for specific data use cases based on the expected frequency of access. For example, you may choose the Amazon S3 Standard class for a data ingestion bucket where you send raw data from on-premise and cloud applications. On the other hand, you can use cheaper options to store less frequently accessed data.
Leverage S3 Intelligent Tiering to reduce costs by automatically switching between different storage tiers based on frequent or infrequent access requirements or archiving use cases. This option best stores processed data with changing or unpredictable access requirements.
The most cost-effective storage option is Amazon S3 Glacier, which provides a deep archive to store historical data and reduce the cost of retaining data for auditing and compliance purposes.
3. Govern Data Storage with Lifecycle Policies
A data lifecycle policy allows DevOps teams to manage data flows in the data lake throughout the lifecycle of a data asset. For example, a data lifecycle policy might determine what happens to an object entering S3. Other policies might specify when to transfer data to a more cost-effective storage class, such as an archive or delete objects that are no longer useful.
While Intelligent Tiering helps triage the objects in the AWS data lake to optimal storage classes, it is a service based on pre-configured policies which might not meet your specific business requirements. S3 data lifecycle management lets you create and apply customized lifecycle configurations to groups of objects, allowing you to control data transfer, storage, and deletion.
4. Leverage Object Tags
Amazon S3 allows you to easily tag objects to categorize and mark your data. An object tag contains a key-value pair—the key has up to 128 characters and the value up to 256 characters. Typically, the key defines the object’s specific attribute while the value component assigns the attribute’s value.
You can assign up to 10 tags to each object in an AWS data lake (each tag must be unique). Multiple objects can share a tag. There are many reasons to tag objects in S3. Object tagging lets you replicate data across multiple regions, locate and analyze all objects that share a given tag, implement data lifecycle policies to objects that share a tag, or give users access permissions to specific groups of objects in the data lake.
Related Articles: Data Warehouse vs Data Lake and Data Lakehouse.
Data Protection with Cloudian
Data protection requires powerful storage technology. Cloudian’s storage appliances are easy to deploy and use, let you store Petabyte-scale data and access it instantly. Cloudian supports high-speed backup and restore with parallel data transfer (18TB per hour writes with 16 nodes).
Cloudian provides durability and availability for your data. HyperStore can backup and archive your data, providing you with highly available versions to restore in times of need.
In HyperStore, storage occurs behind the firewall, you can configure geo boundaries for data access, and define policies for data sync between user devices. HyperStore gives you the power of cloud-based file sharing in an on-premise device, and the control to protect your data in any cloud environment.
Learn more about data protection with Cloudian.