
Splunk is a big data solution that can help you turn raw data into insights. Splunk architecture comes with a set of tools that help you integrate with data sources and then perform collection, queries, indexing, analyses, and visualization. You can integrate Splunk with NoSQL and relational databases, and establish connections between your workflow tools and Splunk.
Splunk also provides several methods for backing up large data sets to on-premise and S3-compatible storage. Learn more in our article about Splunk backup.
In this article you will learn:
- Splunk solutions for big data
- Benefits of Splunk for big data
- What is Splunk analytics for Hadoop
- What is Splunk ODBC driver
- What is Splunk DB Connect
This is part of a series of articles about Splunk Architecture.
Splunk Solutions for Big Data
Splunk is a tool you can use to derive value from your big data. It enables you to incorporate insights from a variety of tools, allowing you to collect, search, index, analyze, and visualize your data from a central location. Splunk supports extracting and organizing real-time insights from big data regardless of source.
Splunk includes several add-ons to help you get more from your data, including:
- Splunk Analytics for Hadoop – enables you to access data stored in Hadoop clusters from virtual indexes. It includes features for processing, reporting, and visualizing data, and for creating reports for combined Hadoop and Splunk data.
- Open Database Connectivity (ODBC) driver – enables you to connect Splunk Enterprise with third-party tools, such as Tableau or Excel.
- DB Connect – enables you to integrate databases with Splunk. DB Connect includes support for a wide variety of databases, including MySQL, Oracle, PostgreSQL, SAP SQL Anywhere, and DB2/Linux.
Read more in our guide to the anatomy of a splunk data model.
Benefits of Splunk for Big Data
Using Splunk can provide you with numerous benefits. Below are some of the most common.
- Enterprise-scale big data—enables you to collect and process hundreds of TBs of data per day. This includes data from multiple datacenters, cloud regions, and infrastructures. It provides data resilience and accommodates any scale environment.
- Insights across real-time and historical data – supports archiving data in Hadoop, enabling you to meet auditing and compliance needs. You can join this data with data currently stored in Hadoop to ensure full dataset access. Once moved, you can query data from a unified dashboard. This unification enables you to visualize and analyze data in real-time or retrospectively.
- Add context and extend with relational data—enables you to integrate data from your data warehouses and relational databases for greater operational and business intelligence. You can accomplish this integration using DB Connect. After integration, you can output data to the software of your choice using the Splunk ODBC driver.
What is Splunk Analytics for Hadoop?
Hadoop is a framework that allows you to process large data sets using cluster computing. It enables you to store significant quantities of unstructured, poly-structured, and structured data. However, you need additional tools to help you extract value from that data.
You can use Splunk Analytics for Hadoop to perform this extraction. Using the Splunk Search Processing Language you can analyze data from Hadoop and NoSQL data stores.
Read more in our guide to Splunk data analytics.
How Does Splunk Return Reports on Hadoop Data?
To return reports on Hadoop data, Splunk performs the following process:
- Reports start when you initiate a report-generated Splunk search on a virtual index.
- Splunk Analytics for Hadoop responds to this search by spawning an External Results Provider (ERP) process. ERP processes carry out searches on Hadoop data.
- Once a process is created Splunk Analytics for Hadoop passes search information to ERP in a JSON format.
- ERP analyzes the search request, according to the information provided, and identifies what data needs to be processed. It then generates Hadoop tasks and creates a MapReduce job to process the request.
- After making sure that your environment is up to date, the MapReduce job performs a search and consumes the result. This result is stored in your Hadoop Distributed File System (HDFS).
- Since the ERP process continuously polls your HDFS, it can gather results when ready. The ERP search process then generates reports from the search results. Reports are updated in real-time as data is added.
What is the Splunk ODBC Driver?
Splunk ODBC driver enables you to connect your existing analytics tools to Splunk. With it, you can retrieve data from Splunk Enterprise and further analyze it using nearly whatever tool you’d like. The image below shows how this process works.

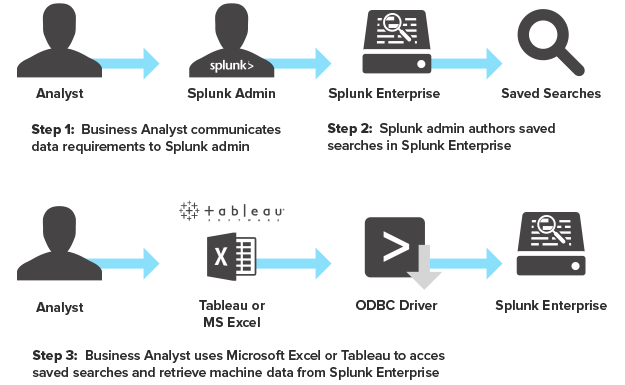
Source: Splunk
There are several benefits to using the Splunk ODBC driver, including:
- Role-Based Access – controls are provided by Splunk, enabling you to achieve secure data storage;
- Machine Data Isolation – you can use saved Splunk searches to ensure that only the data you want to share is accessible.
- Machine Data Integrity – Splunk ensures that data access is read-only when accessed from external sources. This ensures that data isn’t tampered with or inadvertently deleted.
What is Splunk DB Connect?
Splunk DB connect enables you to create a two-way connection between your relational databases and Splunk. This creates additional data inputs for Splunk Enterprise, allowing you to consume data from more sources. It also enables you to write data from Splunk back to your database.nbsp;
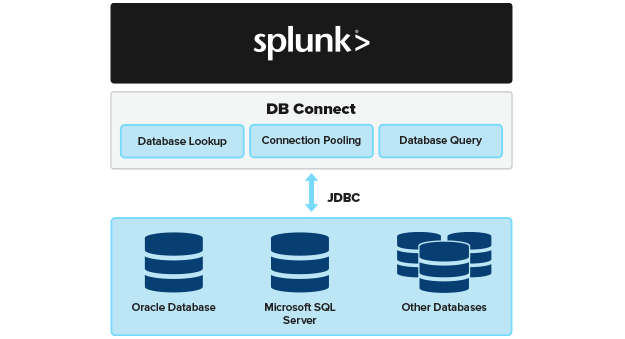

Using DB Connect, you can import tables, rows, and columns of data from your databases. Once imported, you can analyze and visualize your data from Splunk the same as you can for native Splunk data.
Splunk DB Connect enables you to:
- Quickly export data from a database to Splunk
- Perform spontaneous lookups from data warehouses or state tables within Splunk
- Index structured database data in streams or batches
- Write Splunk data into databases in streams or batches
- Preview data and validate settings before indexing
- Scale, distribute, and monitor database read-write jobs
- Control which databases users can access
Reduce Splunk TCO by 60% and Increase Storage Scalability with Cloudian HyperStore
Splunk’s new SmartStore feature enables you to use remote object stores, like Cloudian HyperStore, to store indexed data.
Splunk SmartStore and Cloudian HyperStore create an on-prem storage pool, which is separate from Splunk indexers, and is scalable for huge data stores that reach exabytes. Here’s what you get when you combine Splunk and Cloudian:
- Control—Growth is modular, and you can independently scale resources according to present needs.
- Security—Cloudian HyperStore supports AES-256 server-side encryption for data at rest and SSL for data in transit (HTTPS). Cloudian also protects your data with fine-grained storage policies, secure shell, integrated firewall and RBAC/IAM access controls.
- Multi-tenancy—Cloudian HyperStore is a multi-tenant storage system that isolates storage using local and remote authentication methods. Admins can leverage granular access control and audit logging to manage the operation, and even control quality of service (QoS).
You can find more information about the cooperation between Splunk and Cloudian here.