データ階層化について知る
あらゆるデータは、アクセスの頻度、セキュリティに対するニーズ、コストといった要因のせいで、同じものはありません。そのため、データストレージアーキテクチャでは、さまざまな要件に対応するために異なるストレージ層を提供する必要があります。ストレージ層は、ディスク・ドライブ・タイプ、RAID構成というように、ストレージ・サブシステムによって異なるため、異なるIPプロファイルとコストに影響があります。
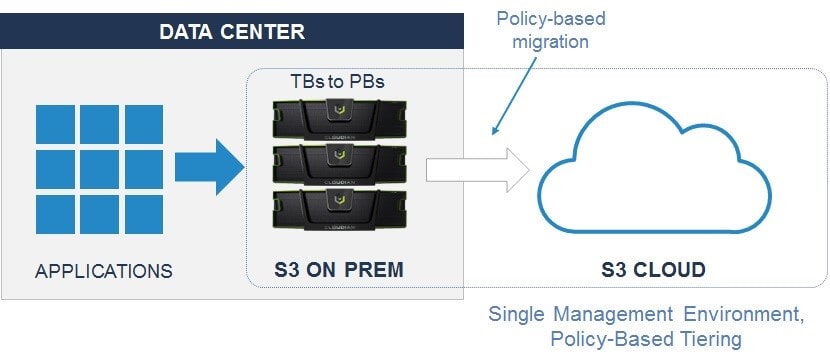
データ階層化は異なるストレージ階層間でのデータの移動を可能にすることです。これにより、適切なデータが適切なストレージ技術にあることを担保できます。現代のストレージアーキテクチャでは、このデータ移動はエンドユーザアプリケーションには見えず、ストレージポリシーにより制御され、自動化されるのが一般的です。典型的なデータ階層の例は、以下のとおりです。
- フラッシュストレージ – 高価値、高性能要件、通常はデータセットは小さく、コストはサービスレベルアグリーメント(SLA)で要求される性能に比較し重要度が低い
- 伝統的なSAN/NASアレイ – 中程度の価値、中程度の性能と中程度のコスト感
- オブジェクトストレージ – 大きなデータセットでアクセス頻度が低い、コストが重要な考慮要件
- パブリッククラウド – アクセスのない長期間アーカイブデータ
通常、OLTPデータベース、CRM、電子メールシステム、仮想マシンなどのアプリケーション/データソースに属する構造化データセットは、上記のようにデータ層1および2に格納されます。構造化されていないデータは、一般的に、パフォーマンスは重要ではなく、管理および購入決定においてコストがより重要な要素となる非常に大きなデータセットであるため、第3層および第4層に移行します。
パブリッククラウドへのデータ階層化における課題
パブリッククラウドサービスは、特に非構造化データの魅力的なデータ階層化ソリューションになっていますが、パブリッククラウドの使用において考慮すべき点があります。
- 性能 – 公衆ネットワークからのアクセスは、パブリッククラウドにデータを読み書きする際のボトルネックとなります(クラウドサービスが提供するSLAによる)。特にバックアップデータの場合、バックアップとリカバリのウィンドウは非常に重要です。最もアクセス頻度の高いバックアップセットはオンサイトに保持し、古いバックアップデータのみをクラウドにアーカイブすることを検討する価値があります
- セキュリティ – 特定のデータの種類や業界では、データをクラウドに格納してはならないという規定があります。クラウドに送信されるデータを制御できることが重要です
- アクセスパターン – 頻繁に再読み込みされるデータは、パブリッククラウドサービス事業者により、追加のネットワーク利用料を課される可能性があります。データダウンロードに関連するコストを管理するには、データの利用方法を理解することが不可欠です
- コスト – データを読む際に伴うネットワーク費用と同じく、大量のデータをクラウドに格納することは、特に社内のクラウドストレージの経済性と比較して経済的に見合わないことがあります。評価を行う必要があります
バランスのとれたデータ階層戦略にハイブリッドクラウドを使う
非構造化データの場合、データ管理に対するハイブリッドなアプローチは、オートメーション・エンジン、データ分類、およびデータのきめ細かな制御にとっての鍵となります
ハイブリッドクラウドのアプローチでは、オンプレミスストレージ側で制御しながらパブリッククラウドに任意のデータをプッシュすることができます。あらゆるデータストレージシステムにとって、異なるデータセットが異なる管理要件を持ち、データの価値に応じて異なるSLAを適用する必要があるため、制御と管理の粒度は非常に重要です。
Cloudian HyperStoreは、このブログの前半にリストしたデータ層3と4を簡単に移動できる柔軟性を提供するソリューションです。データセンターからコントロールしセキュリティを確保できるだけでなく、Amazon S3 / Glacier、Google Cloud Platform、S3 API接続を提供する他のクラウドサービスなど、さまざまな宛先クラウドストレージプラットフォームにHyperStoreを統合することができます。