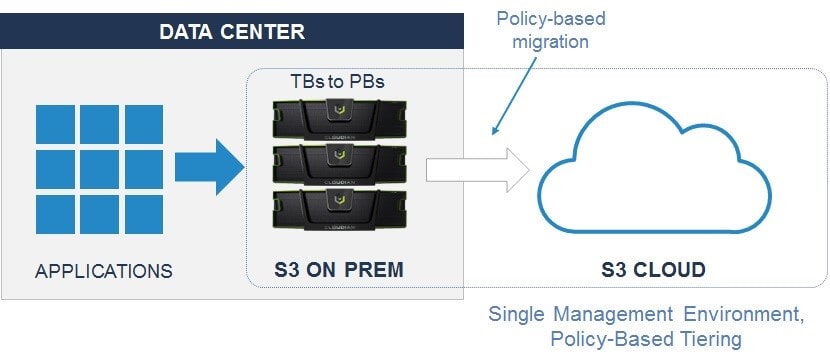
以前のブログ記事「データ階層化について知る」で説明したように、データの種類に応じて適切な処理できるよう、データストレージアーキテクチャ内でストレージを階層化をすることは大きなメリットがあります。ここでは、クラウディアンのHyperStoreがオブジェクトストレージの「自動階層化」を提供する方法について説明します。オブジェクトは、データ・ライフサイクル・ポリシーにより事前に定義されたスケジュールに基づいて、ローカルのHyperStoreストレージから移行先ストレージシステムに自動的に移動できます。

HyperStoreは、階層型データの保存先として、次のクラウドストレージプラットフォームのいずれかを移行先として利用できます。
- Amazon S3
- Amazon Glacier
- Google Cloud Platform
- S3 APIと互換性のあるクラウドサービス
- 遠隔拠点にあるCloudian HyperStore クラスタ
HyperStoreを使い、きめ細かな制御
データ・ストレージ・システムでは、制御と管理のきめ細かさが非常に重要です。データセットには、データの価値に応じて異なるSLA(サービス・レベル・アグリーメント)を適用する必要があることから、管理要件はさまざまです。
HyperStoreはバケットレベルでデータを管理する機能があります(注:「バケット」は、ブロックストレージ内のLUNやファイルシステム内のNASシステム)。 HyperStoreは、バケットレベルで以下の制御パラメータを提供します。
- データ保護 – データ複製またはイレジャーコーディング、単一または複数サイトのデータ配信から選択
- 整合性レベル – 複製方法の制御 (同期 vs 非同期)
- アクセス許諾 – データにアクセスするユーザーとグループ制御
- 災害復旧 – パブリッククラウドへのデータ複製
- 暗号化 – セキュリティ条件に合ったデータ保護
- データ圧縮 – データを保存するために使われる実容量の効率的な削減
- データサイズ閾値 – データのサイズにより保管場所を変更
- ライフサイクルポリシー – 階層化とデータ有効期限に関するデータ管理ルール
HyperStoreは、以下のイメージでライフサイクルポリシーを使いデータ階層化を管理します。
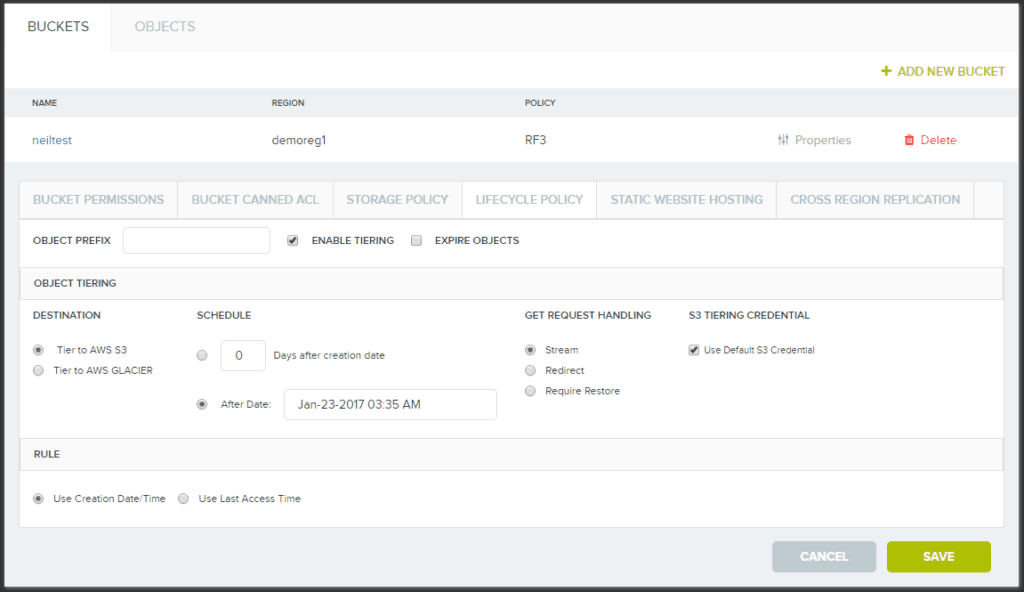
自動階層化は、バケットごとに設定可能で、各バケットはルールに基づいてライフサイクルポリシーが異なります。これらの例には、
1.ライフサイクルルールを適用するデータオブジェクト例
- バケットにある全オブジェクト
- 特定のプレフィックスで始まるオブジェクト (例: “Meetings/2015/”)
2. 階層化のスケジュール方法
- 作成後x日のオブジェクトを移動
- x日間アクセスのないオブジェクトを移動
- 固定日にオブジェクトを移動 — 例:December 31, 2016
あるデータオブジェクトが階層化の候補になると、小さなスタブをHyperStoreクラスタ内に持ちます。スタブは実際のデータオブジェクトへのポインタとして機能するため、データオブジェクトはローカルクラスタに格納されているかのように表示されます。エンドユーザーには、データアクセスの操作に変更はありませんが、オブジェクトには、データオブジェクトが移動されたことを示す特別なアイコンが表示されます。
AmazonやGoogleなどのクラウドプロバイダへの自動階層化には、関連するアカウントにアクセスするクリデンシャル(資格情報)とともにアカウントが必要です。
自動階層化後のデータアクセス
パブリッククラウドサービスに自動階層化されたオブジェクトにアクセスするには、パブリッククラウド(該当するアカウントと資格情報を使用)を介して直接アクセスするか、ローカルのHyperStoreシステム経由でオブジェクトにアクセスします。階層化されたデータを取得するには、次の3つのオプションがあります。
1.オブジェクトのリストア –ユーザーがデータファイルにアクセスすると、HyperStoreに保持されているローカルスタブファイルに転送され、ユーザー要求がデータオブジェクトの実際の場所(階層化された宛先のプラットフォーム)にリダイレクトされます。
データオブジェクトの複製は、階層型ストレージからローカルのHyperStoreバケットに復元され、一度複製されたデータオブジェクトに対してユーザー要求が実行されます。セカンダリ層に戻る前に、検索されたオブジェクトをローカルに保持する期間制限を設定できます。
このことは、比較的頻繁にデータにアクセスするときに使用するための最良の選択肢と考えており、インターネット経由による性能への影響、およびデータアクセス/検索のためにサービスプロバイダが行うアクセス時間を発生させないためです。オブジェクトの取得に十分な「キャッシュ」があることを確認するには、ローカルのHyperStoreクラスタでストレージ容量を管理する必要があります
2.オブジェクトのストリーミング – 最初にローカルのHyperStoreクラスタにデータをリストアせずに、クライアントに直接データをストリームします。ファイルが閉じられると、階層化された場所でオブジェクトに変更が加えられます。メタデータの変更は、ローカルのHyperStoreデータベースと階層化されたプラットフォームの両方で更新されます。
これは、比較的頻繁にデータにアクセスし、ローカルのHyperStoreクラスタのストレージ容量に関する懸念がある際に最適なオプションと考えられますが、データ要求がインターネットを経由するため性能は低下し、このファイルが読み込まれるたびにプロバイダにアクセスコストを課金されます。
3.ダイレクトアクセス – パブリッククラウドサービスに自動階層化されたオブジェクトには、別のアプリケーションやAWS管理コンソールなどの標準パブリッククラウドインタフェースを介して直接アクセスできます。この方法は、HyperStoreクラスタを完全にバイパスします。オブジェクトは標準S3 APIを使用してクラウドに書き込まれ、オブジェクトのメタデータのコピーが含まれているため、直接参照することができます。
このオープンにアクセス可能な方法でオブジェクトを格納すると(リッチなメタデータを同じ場所に配置)、次のような場合に便利です。
- HyperStoreクラスタが利用できない災害復旧
- 別のプラットフォームへのデータ移行を容易にする
- コンテンツ配信など、別のクラウドベースのアプリケーションからのアクセスを有効にする
- 索引付けを提供するために別のデータベースに依存することなく、データにオープンなアクセスを提供する
HyperStoreは、ハイブリッドクラウドの展開を活用するための柔軟性を提供し、パブリッククラウドまたはプライベートクラウドにデータを格納するポリシーを設定できます。