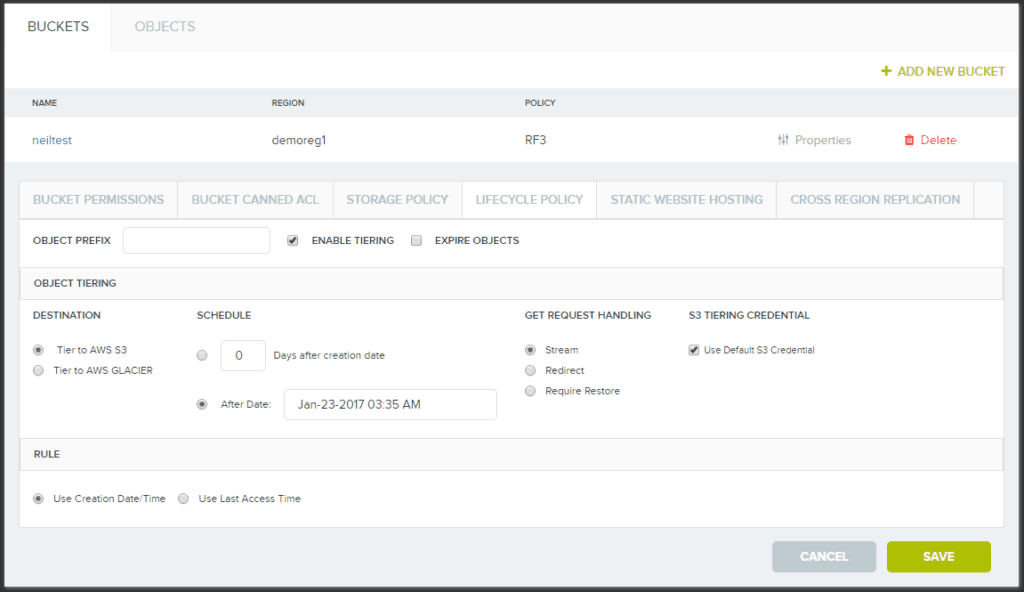
オブジェクト ストレージは 90 年代半ばから存在していますが、比較的新しく、ブロック ストレージやファイル ストレージなどの他のストレージ タイプとの違いについて混乱することがあります。
ファイルストレージとは何ですか?
ファイル ストレージはオブジェクト ストレージよりもはるかに古く、ほとんどの人がよく知っています。ファイル/データに名前を付けてフォルダーに配置したり、多くのフォルダーを作成したり、パスを設定したりできます。このように、ファイルはディレクトリとサブディレクトリに階層的に編成されます。各ファイルには、ファイル名、作成日、最終更新日などのメタデータも関連付けられています。
これはある程度までは非常にうまく機能しますが、容量が大きくなると、2 つの理由でファイル モデルが厄介になります。
まず、特定の容量を超えるとパフォーマンスが低下します。
NAS システム自体の処理能力は限られているため、プロセッサがボトルネックになります。 容量が増加するにつれて大規模なデータベース (ファイル参照テーブル) もパフォーマンスに影響します。

オブジェクトストレージとは?
オブジェクト ストレージは基本的に、メタデータ タグと一意の識別子と共にデータ自体をバンドルします。メタデータはカスタマイズ可能です。これは、各データに対して多くの識別情報を入力できることを意味します。これらのオブジェクトはフラットなアドレス空間に格納されるため、リージョン間でのデータの検索と取得が容易になります。
このフラットなアドレス空間は、スケーラビリティにも役立ちます。ノードを追加するだけで、ペタバイトを超えて拡張できます。
オブジェクトストレージとファイルストレージの違いは何ですか?
オブジェクト ストレージとファイル ストレージの基本を理解したところで、主な違いをいくつか見ていきましょう。
まず、オブジェクト ストレージには、ファイル ストレージが直面する多くの制限がありません。ファイル ストレージを倉庫と考えてください。ファイルの箱を最初にそこに置くと、十分なスペースがあります。しかし、データの需要が高まるにつれて、倉庫がいっぱいになることに気付くでしょう。一方、オブジェクト ストレージは、屋外倉庫のようなものです。無期限にデータを追加し続けることができます。限界は空の大きさです。
小さなファイルや個別のファイルを主に読み取る場合、ファイル ストレージは適切に機能します (特に、データ量が比較的少ない場合)。しかし、規模が大きくなると、「必要なファイルをどのように検索すればよいか」と考えるようになります。
オブジェクト ストレージはバレット パーキングと考えることができますが、ファイル ストレージはセルフ パーキングに似ています。車を小さな駐車場に駐車すれば、自分の車がどこにあるか正確にわかります。しかし、駐車場が何千倍も大きいと想像してみてください。車を探すのは大変です。
オブジェクト ストレージにはカスタマイズ可能なメタデータがあり、すべてのオブジェクトはフラットなアドレス空間に存在するため、車のキーを係員に渡すようなものです。車はどこかに保管され、必要なときに係員が車を持ってきてくれます。車が到着するまで時間がかかる場合がありますが、周りを気にする必要はありません。
オブジェクト ストレージ メタデータ
X 線を撮影して、メタデータが役立つ実際の例を説明しましょう。 X 線の「ファイル」には、作成日、所有者、場所、サイズなど、関連するメタデータが限られています。一方、X 線の「オブジェクト」は、さまざまなメタデータ情報を持つことができます。
そのメタデータには、患者の名前、生年月日、怪我の詳細、ファイル内の同じタグ、さらに身体のどの領域が X 線で撮影されたかなどが含まれます。これは、医師が関連情報を参照するのに非常に便利です。