

Neil Stobart, Vice President of Global System Engineering, Cloudian

Veeam 9.5 Update 4 introduced S3 connectivity capabilities with the introduction of Cloud Tier. Veeam Cloud Tier enables native S3 API connectivity to the Cloudian HyperStore object storage platform for usage as an on-premises secondary backup target, providing exabyte scalability. It also enables automatic offsite backup copies, with both on-premises and offsite backups accessible from a single namespace.
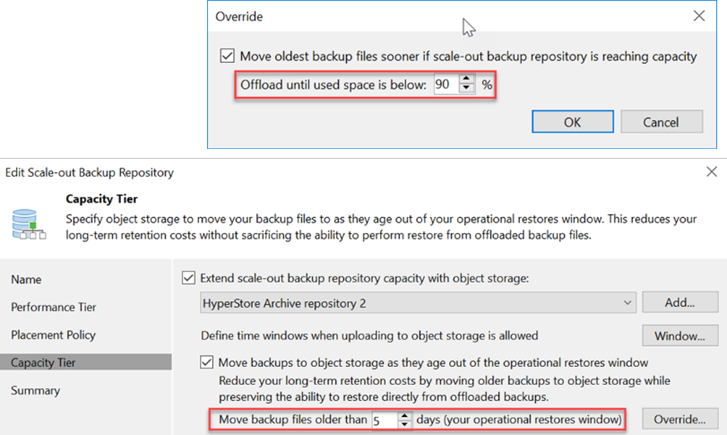
Although Veeam is, currently a block or file storage platform is required to accept and store the initial backup writes. This storage tier is where Veaam carries out its data deduplication work and creates its backup files. Veeam uses a policy-based engine to move the initial backup files from the primary repository to Cloudian planning support for direct backup to Cloudian HyperStore using the S3 API HyperStore for longer-term data retention.
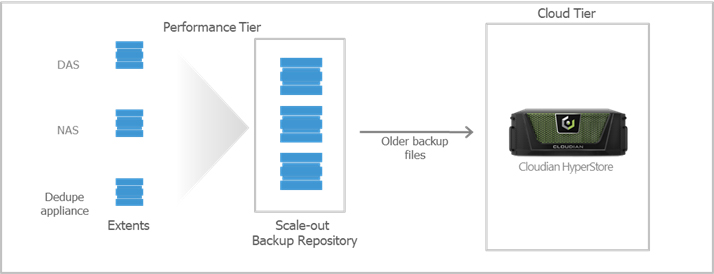
Cloudian HyperFile
In addition to HyperStore, Cloudian also provides the HyperFile NAS gateway which provides applications and users a translation layer between network file systems (NFS\SMB) and object storage (S3 restful API). HyperFile is a ZFS-based storage platform and uses a local disk cache for the initial ingestion of data, which is managed by a policy-based engine to then move the data to HyperStore for longer data retention. The HyperFile cache storage system is typically sized to meet the storage needs for short-term data retention before it is picked up and moved to HyperStore.
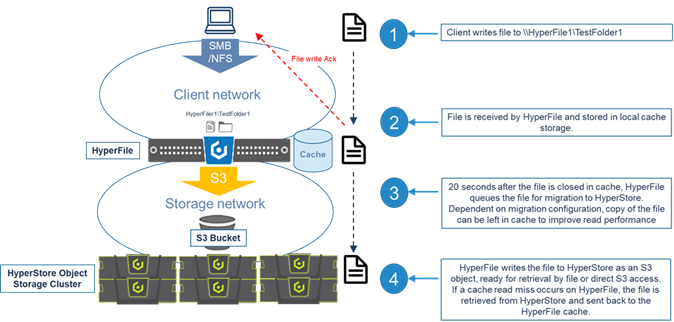
HyperFile is typically deployed when there is an application need for scale-out storage, there is an appropriate workload (larger files, lots of files) and the application does not support the S3 API natively.
In the case of Veeam backup, S3 storage is not compatible as the primary backup target and iSCSI or NFS storage is required. Cloudian tested Veeam with HyperFile\HyperStore configured in a typical deployment and found that the tiering capability between HyperFile and HyperStore did not suit the IO operations that Veeam required to reconstruct data on recoveries.
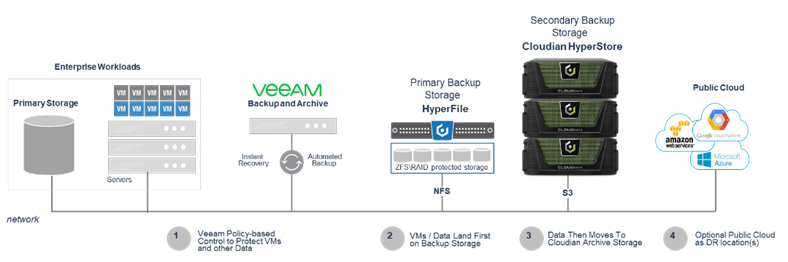
So, we got our thinking caps on and came up with an alternative solution. Use HyperFile as Veeam primary storage and let Veeam manage the tiering to HyperStore. Kinda obvious really!!
HyperFile and HyperStore Managed by Veeam
The key difference in this deployment is to size the HyperFile local disk cache to be able to meet the requirements of Veeam’s primary\secondary architecture.
For higher transactional performance, local SSDs over HDDs would be recommended, whereas, for large data files [and?] sequential workloads, 7K RPM magnetic drives could be better suited.
HyperFile formats local drives using the ZFS file system which also incorporates a volume manager. You can specify different RAID settings across different numbers of drives to optimize your cache pool for your specific workload. We recommend using:
- Write performance (Backup) optimization – vdevs created using mirrors in groups of 2 drives
- Read performance (Recovery) and cost optimization – vdevs created using either mirrors or RAIDZ2 (equivalent of RAID6) in groups of 6 (4 data, 2 parity)
Multiple ZFS vdevs can be created from the local storage devices Combining multiple vdevs allows you to build up the disk IO performance of the HyperFile instance to match your required backup and recovery window SLAs. The cache can also be extended by adding further vdevs to provide additional capacity and disk IO performance.
Using external NAS or SAN storage devices can be beneficial if surplus capacity exists on existing storage platforms in your environment, especially if you are running HyperFile in a virtual environment, where shared storage is required as standard. Consideration should be given to:
- Performance of the file share/LUN presented to HyperFile and that IOPS bandwidth available to HyperFile
- Capability of the external storage array for specific workloads and any potential external storage array cache bottlenecks
- Capacity available
- Any potential bottlenecks or contention on the network
Estimating HyperFile Capacity for Veeam Primary Backup Repository
When estimating the amount of required disk space, you should know the following:
- Total size of VMs being backed up
- Frequency of backups
- Retention period for backups
- Whether jobs use forward or reverse incremental
Also, when testing is not possible beforehand, you should make assumptions on compression and deduplication ratios, change rates, and other factors. The following figures are typical for most deployments; however, it is important to understand the specific environment to figure out possible exceptions:
- Data reduction due to compression and deduplication is usually at least 2:1; it’s common to see 3:1 or better, but you should always be conservative when estimating the required space.
- The typical daily change rate is between 2% and 5% in a mid-size or enterprise environment; this can greatly vary among servers; some servers show much higher values. If possible, run monitoring tools like Veeam ONE to have a better understanding of the real change rate values.
- Include additional space for one-off full backups.
- Include additional space for backup chain transformation (forward forever incremental, reverse incremental) – at least the size of a full backup multiplied by 1.25.
Using the numbers above, you can estimate the required disk space for your backup jobs. Remember to always leave plenty of extra headroom for future growth, additional full backups, moving VMs, and restoring VMs from long-term archive. A repository sizing tool that can be used for capacity estimation is available at http://vee.am/rps. Note that this tool is not officially supported by Veeam, and it should be used “as is,” but it’s nonetheless heavily used by Veeam Architects and regularly updated.
Capacity Sizing Examples
The examples below explain the impact of the backup method and retention policy on the estimated repository size, assuming the environment is the same in all three cases.
- Environment: 10 VMs, 100GB each, 80GB avg/used
- 2:1 estimated compression/deduplication, 5% daily change
| Example 1 – Backup: Reverse Incremental, Daily Backup, 30 Day Retention |
Example 2 – Backup: Forward Incremental, Daily Backup, 30 Day Retention, Weekly Full |
Example 3 – Backup: Forward Incremental, Daily Backup, 30 Day Retention, Monthly Full |
|
|---|---|---|---|
| Full Backup Size | 10 * 80GB (Used space) * 50% (2:1 Comp) = 400GB |
10 * 80GB (Used space) * 50% (2:1 Comp) = 400GB |
10 * 80GB (Used space) * 50% (2:1 Comp) = 400GB |
| 6 Weekly Fulls 30 Day Retention |
400GB * 3 = 1200GB | ||
| 3 Monthly Fulls 30 Day Retention |
400GB * 6 = 2400GB | ||
| Reverse Incremental Size | 10 * 80GB * 50% (2:1 Comp) * 5% (Change Rate) * 29 (reverse incremental restore points) = 580GB | 10 * 80GB * 50% * 5% * 32 = 640GB | 10 * 80GB * 50% * 5% * 60 = 1200GB |
| Spare | 500GB | ||
| Total Backup Size | 400GB + 580GB + 500 = 1480 GB | 2400GB + 640GB = 3,040GB (~3TB) | 1200GB + 1200GB = 2,400GB (~2.4TB) |
To summarize, when estimating the size of the repositories, use the following best practices:
- Be conservative when estimating compression and deduplication ratios if actual ratios and disk content are unknown.
- Use higher estimates for change rate if a significant number of servers are transactional such as Microsoft SQL and Microsoft Exchange.
- Include enough free space to take at least one and a quarter extra full backup for each transformation job.
Learn More:

This Veeam video shows how to set up a Cloudian repository in Veeam Backup and Replication Version 10.
Ransomware Protection: Immutable Data Storage

This video explains how you can lock out ransomware with the Cloudian solution.