

What is S3 Storage?
Amazon Simple Storage Service (S3) is a massively scalable storage service based on object storage technology. It provides a very high level of durability, with high availability and high performance. Data can be accessed from anywhere via the Internet, through the Amazon Console and the powerful S3 API.
S3 storage provides the following key features:
- Buckets—data is stored in buckets. Each bucket can store an unlimited amount of unstructured data.
- Elastic scalability—S3 has no storage limit. Individual objects can be up to 5TB in size.
- Flexible data structure—each object is identified using a unique key, and you can use metadata to flexibly organize data.
- Downloading data—easily share data with anyone inside or outside your organization and enable them to download data over the Internet.
- Permissions—assign permissions at the bucket or object level to ensure only authorized users can access data.
- APIs – the S3 API, provided both as REST and SOAP interfaces, has become an industry standard and is integrated with a large number of existing tools.
This is part of an extensive series of guides about cloud storage.
In this article:
- 5 Use Cases for S3 Storage
- How Does S3 Storage Work?
- Amazon S3 Storage Classes
- Getting Started With Amazon S3
- S3 Storage Q&A
What’s New in S3 Storage?
Amazon S3 has continued to evolve beyond traditional object storage, with recent updates focused on larger objects, analytics, AI workloads, metadata discovery, and file-based access:
- One important update is the increase in the maximum individual object size from 5 TB to 50 TB. This makes S3 more practical for storing very large files such as high-resolution video, seismic datasets, AI training data, and other massive data objects without splitting them into multiple files. AWS states that 50 TB objects can be stored across all S3 storage classes and used with S3 features.
- AWS has also introduced Amazon S3 Tables, a capability designed for analytics workloads using Apache Iceberg. S3 Tables provide a way to store tabular data directly in S3, supporting data lakehouse architectures and improving performance for query-heavy analytics workloads. AWS says S3 Tables can deliver faster query performance through continual table optimization compared with unmanaged Iceberg tables.
- Another major addition is Amazon S3 Metadata, which automatically captures object metadata and makes it available in queryable, read-only tables. This helps organizations search, classify, and analyze large object stores without building custom metadata indexing systems. S3 Metadata now supports both new and existing objects, giving teams a continuously updated view of their S3 data.
- For AI and machine learning use cases, AWS has launched Amazon S3 Vectors, a new S3 bucket type optimized for storing and querying vector embeddings. This is useful for semantic search, recommendation systems, retrieval-augmented generation, and other generative AI workloads that rely on vector data. S3 Vectors provides APIs for storing, accessing, and querying vectors without provisioning separate vector database infrastructure.
- AWS has also added Amazon S3 Files, which lets applications access S3 bucket data through file system semantics. Built using Amazon EFS, S3 Files allows file-based applications, AI agents, and ML workflows to work with S3 data without duplicating or staging it in a separate file system.
S3 has also gained stronger data integrity options. AWS recently added support for five additional checksum algorithms, with integration across S3 Replication, S3 Inventory, and S3 Batch Operations. This makes it easier to audit object integrity at scale and calculate checksums for existing objects without downloading or restoring the data.
5 Use Cases for S3 Storage
1. Backup and Archival
One of the primary use cases for S3 storage is backup and archival. Organizations can leverage S3’s durability and availability to ensure the safety and longevity of their data. S3’s redundant architecture and distributed data storage make it possible to store critical data that needs to be accessed quickly and securely.
S3 also offers seamless integration with various backup and archival software. This allows businesses to automate the backup and archival processes, reducing the risk of human error and ensuring data is consistently protected. With S3’s versioning capabilities, organizations can also retain multiple versions of their files, enabling roll back to previous versions if needed.
2. Content Distribution and Hosting
By leveraging S3’s global network of edge locations, content creators can distribute their files seamlessly to end-users, reducing latency and improving user experience. S3’s integration with content delivery networks (CDNs) further enhances its content distribution capabilities, ensuring that files are delivered quickly and efficiently.
Moreover, S3 storage is highly scalable, allowing businesses to handle high traffic spikes without performance degradation. This makes it an ideal choice for hosting static websites, where content is served directly from S3 buckets. With S3’s support for custom domain names and SSL certificates, businesses can create a reliable and secure web hosting environment.
3. Disaster Recovery
With S3’s cross-region replication, businesses can automatically save their data in multiple Amazon regions, ensuring that it is protected against regional disasters. In the event of a disaster, organizations can quickly restore their data from the replicated copies stored in S3, minimizing downtime and data loss.
S3’s durability and availability also make it an excellent choice for storing backups of critical systems and databases. By regularly backing up data to S3, organizations can quickly recover their systems in the event of a failure, reducing the impact on business operations.
4. Big Data and Analytics
S3’s low-cost storage object make it suitable for storing large volumes raw data. Organizations can ingest data from various sources into S3, including log files, sensor data, and social media feeds. S3’s integration with big data processing frameworks like Apache Hadoop and Apache Spark enables businesses to process and analyze this data at scale.
Additionally, S3 supports data lake architectures, allowing organizations to store structured and unstructured data in its native format. This reduces the need for data transformation, reducing complexity and enabling faster data processing. S3 tightly integrates with Amazon’s big data analytics services like Amazon Athena and Amazon Redshift.
5. Software and Object Distribution
S3 is commonly used by organizations to distribute software packages, firmware updates, and other digital assets to users, customers, or employees. S3’s global network of edge locations ensures fast and efficient delivery of these files, regardless of the users’ location.
With S3’s support for access control policies and signed URLs, businesses can ensure that only authorized users can access their distributed files. This provides an additional layer of security and prevents unauthorized distribution or tampering of software packages.
5 Expert Tips to help you better leverage your S3 storage

Jon Toor, CMO
With over 20 years of storage industry experience in a variety of companies including Xsigo Systems and OnStor, and with an MBA in Mechanical Engineering, Jon Toor is an expert and innovator in the ever growing storage space.
Leverage object lifecycle policies for cost management: Use lifecycle policies to automatically transition data between storage classes (e.g., from S3 Standard to Glacier) as data ages. This ensures that less frequently accessed data is moved to cheaper storage tiers.
Utilize object tagging for advanced data organization: Instead of solely relying on key-based organization, use object tags to categorize and manage data. This becomes especially useful for applying fine-grained permissions, setting up automated workflows, or optimizing cost based on access patterns.
Enable default encryption for buckets: Set up default encryption on buckets to ensure that all data stored is automatically encrypted, without relying on the client to specify encryption settings on individual objects.
Implement versioning with caution: While versioning protects against accidental deletions or overwrites, it can lead to ballooning storage costs. Use lifecycle policies to delete older versions after a set time to control storage bloat.
Automate data protection with cross-region replication (CRR): Use CRR to automatically replicate data across AWS regions for disaster recovery or to reduce latency for global users. Be mindful of the associated costs, particularly if high data volumes are involved.
How Does S3 Storage Work?
Amazon S3 data is stored as objects. This approach enables highly scalable storage in the cloud. Objects can be placed on a variety of physical disk drives distributed throughout the data center. Amazon data centers use specialized hardware, software, and distributed file systems to provide true elastic scalability.
Amazon provides redundancy and version control using block storage methods. Data is automatically stored in multiple locations, distributed across multiple disks, and in some cases, multiple availability zones or regions. The Amazon S3 service periodically checks the integrity of the data by checking its control hash value. If data corruption is detected, redundant data is used to restore the object.
S3 lets you manage your data via the Amazon Console and the S3 API.
Buckets
Buckets are logical containers in which data is stored. S3 provides unlimited scalability, and there is no official limit on the amount of data and number of objects you can store in an S3 bucket. The size limit for objects stored in a bucket is 5 TB.
An S3 bucket name must be unique across all S3 users, because the bucket namespace is shared across all AWS accounts.
Keys
When you upload an object to a bucket, the object gets a unique key. The key is a string that mimics a directory hierarchy. Once you know the key, you can access the object in the bucket.
The bucket name, key, and version ID uniquely identify every object in S3. S3 provides two URL structures you can use to directly access an object:
{BUCKET-NAME}.s3.amazonaws.com/{OBJECT-KEY}
s3.amazon.aws.com/{BUCKET-NAME}/{OBJECT-KEY}
AWS Regions
Amazon has data centers in 24 geographical regions. To reduce network latency and minimize costs, store your data in the region closest to its users.
Unless you manually migrate your data, data stored in a specific AWS Region will never leave that region’s data center. AWS Regions are separated from each other to provide fault tolerance and reliability.
Each region is made up of at least three availability zones, which are separated, independent data centers. Data is replicated across availability zones to protect against outage of equipment in a specific data center, or disasters like fires, hurricanes and floods.
Related content: read our guide to object storage deployment
Amazon S3 Storage Classes
S3 provides storage tiers, also called storage classes, which can be applied at the bucket or object level. S3 also provides lifecycle policies you can use to automatically move objects between tiers, based on rules or thresholds you define.
The main storage classes are:
- Standard—for frequently accessed data
- Standard-IA—standard infrequent access
- One Zone-IA—one-zone infrequent access
- Intelligent-Tiering—automatically moves data to the most appropriate tier
Below we expand on the more commonly used classes.
Amazon S3 Standard
The S3 standard tier provides:
- Durability of 99.999999999% by replicating objects to multiple Availability Zones
- 99.99% availability backed by Service Level Agreement (SLA)
- Built-in SSL encryption for all data (both in transit and at rest)
Amazon S3 Standard-Infrequent Access
The S3 Standard-IA tier is for infrequently accessed data. It has a lower cost per GB/month, compared to the Standard tier, but charges a retrieval fee. The S3 Standard-IA tier provides:
- The same performance and latency as the Standard tier
- The same durability—99.999999999% across multiple Availability Zones
- 99.9% availability backed by SLA
S3 Storage Archive
S3 provides Glacier and Deep Archive, storage classes intended for archived data that is accessed very infrequently. Cost per GB/month is lower than S3 Standard-IA.
- S3 Glacier—data must be stored for at least 90 days and can be restored within 1-5 minutes, with expedited retrieval.
- S3 Glacier Deep Archive—data must be stored for at least 180 days, and can be retrieved within 12 hours. There is a discount on bulk data retrieval, which takes up to 48 hours.
Getting Started with Amazon S3
Here is a quick guide showing how to start saving your data to S3.
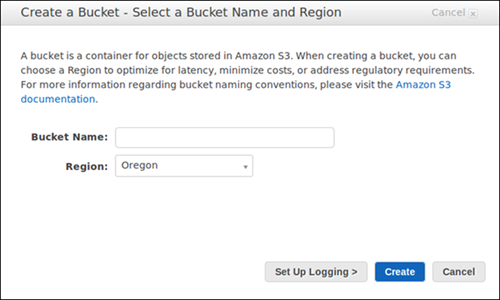
Step 1: Create S3 Bucket
To get started with Amazon S3, the first step is to create an S3 bucket. A bucket is a container for storing objects in S3. Follow these steps to create an S3 bucket:
- Log in to the AWS Management Console and navigate to the S3 service.
- Click the Create bucket button.
- Enter a unique bucket name. Bucket names must be globally unique across all AWS accounts.
- Choose the region where you want to create the bucket. The region selection is important because it affects the data transfer costs and latency.
- Configure additional settings such as versioning, logging, and tags if needed.
- Click on the Create bucket button to create your S3 bucket.
Once the bucket is created, you can start uploading objects to it.
Step 2: Upload an Object to the Bucket
Uploading objects to an S3 bucket is straightforward. You can upload files, images, videos, or any other type of data. Here’s how you can upload an object to your S3 bucket:
- Open the S3 console and navigate to your bucket.
- Click on the Upload button.
- Choose the files you want to upload from your local machine.
- Optionally, you can set permissions, metadata, and encryption options for the uploaded objects.
- Click on the Upload button to start the upload process.
You can monitor the progress of the upload and once it’s completed, your object will be available in your S3 bucket. You can then access the object using a unique URL provided by S3.
S3 Storage Q&A
How Much Data Can I Store in Amazon S3?
You can store an unlimited amount of data in Amazon S3. Other storage related limits include:
- Individual objects limited to 5TB
- Upload up to 5GB in one PUT operation
- For objects larger than 100MB Amazon recommends using Multiple Upload
How is Amazon S3 Data Organized?
Amazon S3 is an object store. Each object has a unique key that can be used to retrieve it later. You can define any string as a key, and keys can be used to create a hierarchy, for example by including a directory structure in the key. Another option is to organize objects using metadata, using S3 Object Tagging.
How Reliable is Amazon S3?
Amazon S3 provides 11 nines (99.999999999%) durability. With regard to availability, S3 guarantees:
- 99.99% availability for Standard storage class
- 99.9% availability for Standard-IA, Glacier and Deep Archive
- 99.5% availability for One Zone-IA
Meet Cloudian: S3-Compatible, Massively Scalable On-Premise Object Storage
Cloudian® HyperStore® is a massive-capacity object storage device that is fully compatible with Amazon S3. It can store up to 1.5 Petabytes in a 4U Chassis device, allowing you to store up to 18 Petabytes in a single data center rack. HyperStore comes with fully redundant power and cooling, and performance features including 1.92TB SSD drives for metadata, and 10Gb Ethernet ports for fast data transfer.
HyperStore is an object storage solution you can plug in and start using with no complex deployment. It also offers advanced data protection features, supporting use cases like compliance, healthcare data storage, disaster recovery, ransomware protection and data lifecycle management.
Learn more about Cloudian® HyperStore®.
See Additional Guides on Key Cloud Storage Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of cloud storage.
Distributed Storage
Related guides
Authored by Cloudian
- [Guide] Distributed Storage: What’s Inside Amazon S3?
- [Guide] Backup Cloud Storage: Ensuring Business Continuity
- [Guide] Unified Storage: Combining Block-Level and File-Level Storage
File Upload
Authored by Cloudinary
- [Guide] Automating File Upload and Sharing
- [Guide] AJAX File Upload – Quick Tutorial & Time Saving Tips
- [Blog] Implement Dynamism in Static Sites With Serverless Functions
- [Product] Cloudinary Assets | AI-Powered Digital Asset Management
AWS Pricing
Authored by Finout