

What Is Object Storage?
Object storage is a data storage architecture that stores and manages unstructured data in units called objects. Objects can be any size or format, and can include data, metadata, and a unique identifier.
Unlike other storage systems, object storage is not organized into folders or a hierarchical path, so objects can be reached through multiple paths. In object storage, objects are stored in a flat data environment and can be accessed through multiple paths, rather than being organized into folders.
Objects can store photos, videos, emails, audio files, network logs, or any other type of structured or unstructured data. All of the major public cloud services, including Amazon, Google and Microsoft, employ object storage as their primary storage.
This is part of an extensive series of guides about data security.
In this article:
- Object Storage Definition
- Object Storage Architecture: How Does It Work?
- Object Storage Benefits
- Object Storage Use Cases
- Selecting the Best Object-Based Storage Solution
Object Storage Definition
Object storage is a technology that manages data as objects. All data is stored in one large repository which may be distributed across multiple physical storage devices, instead of being divided into files or folders.
It is easier to understand object-based storage when you compare it to more traditional forms of storage – file and block storage.
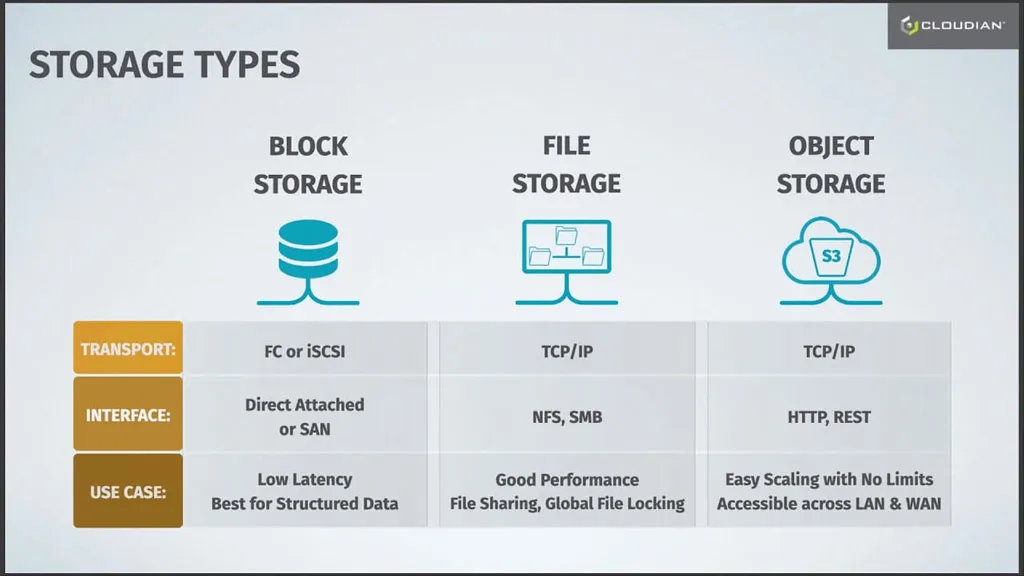
File Storage
File storage stores data in folders. This method, also known as hierarchical storage, simulates how paper documents are stored. When data needs to be accessed, a computer system must look for it using its path in the folder structure.
File storage uses TCP/IP as its transport, and devices typically use the NFS protocol in Linux and SMB in Windows.
Block Storage
Block storage splits a file into separate data blocks, and stores each of these blocks as a separate data unit. Each block has an address, and so the storage system can find data without needing a path to a folder. This also allows data to be split into smaller pieces and stored in a distributed manner. Whenever a file is accessed, the storage system software assembles the file from the required blocks.
Block storage uses FC or iSCSI for transport, and devices operate as direct attached storage or via a storage area network (SAN).
Object Storage
In object storage systems, data blocks that make up a file or “object”, together with its metadata, are all kept together. Extra metadata is added to each object, which makes it possible to access data with no hierarchy. All objects are placed in a unified address space. In order to find an object, users provide a unique ID.
Object-based storage uses TCP/IP as its transport, and devices communicate using HTTP and REST APIs.
Metadata is an important part of object storage technology. Metadata is determined by the user, and allows flexible analysis and retrieval of the data in a storage pool, based on its function and characteristics.
The main advantage of object storage is that you can group devices into large storage pools, and distribute those pools across multiple locations. This not only allows unlimited scale, but also improves resilience and high availability of the data.
Object Storage Architecture: How Does It Work?
Anatomy of an Object
Object storage is fundamentally different from traditional file and block storage in the way it handles data. In an object storage system, each piece of data is stored as an object, which can include data, metadata, and a unique identifier, known as an object ID. This ID allows the system to locate and retrieve the object without relying on hierarchical file structures or block mappings, enabling faster and more efficient data access.
Objects can be any size or format, and can store photos, videos, emails, audio files, network logs, or any other type of structured or unstructured data.
Data Storage Layer: Flat Data Environment
The data storage layer is where the actual data objects are stored. Object storage is not organized into folders or a hierarchical path, so objects can be reached through multiple paths. Objects are stored in a flat data environment and can be accessed through multiple paths.
In an object storage system, data is typically distributed across multiple storage nodes to ensure high performance, durability, and redundancy. Each storage node typically contains a combination of hard disk drives (HDDs) and solid-state drives (SSDs) to provide the optimal balance between capacity, performance, and cost. Data objects are automatically replicated across multiple nodes, ensuring that data remains available and protected even in the event of hardware failures or other disruptions.
Metadata Index
The metadata index is a critical component of object storage architecture, as it maintains a record of each object’s unique identifier, along with other relevant metadata, such as access controls, creation date, and size. This information is stored separately from the actual data, allowing the system to quickly and efficiently locate and retrieve objects based on their metadata attributes. The metadata index is designed to be highly scalable, enabling it to support millions or even billions of objects within a single object storage system.
API Layer
The API layer is responsible for providing access to the object storage system, allowing users and applications to store, retrieve, and manage data objects. Most object storage systems support a variety of standardized APIs, such as the Simple Storage Service (S3) API from Amazon Web Services (AWS), the OpenStack Swift API, and the Cloud Data Management Interface (CDMI). These APIs enable developers to easily integrate object storage into their applications, regardless of the underlying storage technology or vendor.
5 Expert Tips to help you better optimize your object storage care

Jon Toor, CMO
With over 20 years of storage industry experience in a variety of companies including Xsigo Systems and OnStor, and with an MBA in Mechanical Engineering, Jon Toor is an expert and innovator in the ever growing storage space.
Leverage lifecycle policies to manage storage costs: Implement object lifecycle management to automatically transition objects between storage classes based on their age or access patterns. This can help you reduce storage costs by moving infrequently accessed data to colder storage tiers.
Optimize metadata for faster search and analytics: Invest time in designing your object metadata schema. Adding meaningful, searchable metadata can dramatically enhance retrieval speed and enable powerful analytics without needing to process the entire object.
Use erasure coding for efficient data protection: While replication is common, erasure coding provides more efficient storage utilization, especially in environments with large datasets. It offers high durability while using less storage space than simple replication.
Enable versioning for data integrity and compliance: Activate object versioning to protect against accidental overwrites or deletions. This is critical for compliance in industries where data integrity is required over long retention periods.
Implement policy-driven data tiering: Automate data movement between hot, warm, and cold storage using policy-based rules. This approach allows you to maximize cost efficiency by aligning storage costs with data value and access frequency.
Object Storage Benefits
Exabyte Scalable
Unlike file or block storage, object storage services enable scalability that goes beyond exabytes. While file storage can hold many millions of files, you will eventually hit a ceiling. With unstructured data growing at 50+% per year, more and more users are hitting those limits, or they expect to in the future.
Scale Out Architecture
Object storage makes it easy to start small and grow. In enterprise storage, a simple scaling model is golden. And scale-out storage is about as simple as it gets: you simply add another node to the cluster and that capacity gets folded into the available pool.
HyperStore is an S3-compatible storage system. HyperFile is a connector that allows files to be stored on HyperStore.
Customizable Metadata
While file systems have metadata, the information is limited and basic (date/time created, date/time updated, owner, etc.). Object storage allows users to customize and add as many metadata tags as they need to easily locate the object later. For example, an X-ray could have information about the patient’s age and height, the type of injury, etc.
High Sequential Throughput Performance
Early object storage systems did not prioritize performance, but that’s now changed. Now, object stores can provide high sequential throughput performance, which makes them great for streaming large files. Also, object storage services help eliminate networking limitations. Files can be streamed in parallel over multiple pipes, boosting usable bandwidth.
Flexible Data Protection Options
To safeguard against data loss, most traditional storage options utilize fixed RAID groups (groups of hard drives joined together), sometimes in combination with data replication. The problem is, these solutions generally lead to one-size-fits-all data protection. You can not vary the protection level to suit different data types.
Object storage solutions employ a flexible tool called erasure coding that is similar to old-fashioned RAID in some ways, but is far more flexible. Data is striped across multiple drives or nodes as needed to achieve the needed protection for that data type. Between erasure coding and configurable replication, data protection is both more robust and more efficient.
Support for the S3 API
Back when object storage solutions were launched, the interfaces were proprietary. Few application developers wrote to these interfaces. Then Amazon created the Simple Storage Service, or “S3”. They also created a new interface, called the “S3 API”. The S3 API interface has since become a de-facto standard for object storage data transfer.
The existence of a de facto standard changed the game. Now, S3-compatible application developers have a stable and growing market for their applications. And service providers and S3-compatible storage vendors such as Cloudian have a growing user set deploying those applications. The combination sets the stage for rapid market growth.
Lower Total Cost of Ownership (TCO)
Cost is always a factor in storage. And object storage services offer the most compelling story, both in hardware/software costs and in management expenses. By allowing you to start small and scale, this technology minimizes waste, both in the form of extra headcount and unused space. Additionally object storage systems are inherently easy to manage. With limitless capacity within a single namespace, configurable data protection, geo replication, and policy-based tiering to the cloud, it’s a powerful tool for large-scale data management.
To learn more about Cloudian’s fully native S3-compatible storage in your data center, and how it can cut down your TCO, check out our free trial. Or visit cloudian.com for more information.
Object Storage Use Cases
There are numerous use cases for object storage, thanks to its scalability, flexibility, and ease of use. Some of the most common use cases include:
Backup and archiving
Object storage is an excellent choice for storing backup and archive data, thanks to its durability, scalability, and cost-effectiveness. The ability to store custom metadata with each object allows organizations to easily manage retention policies and ensure compliance with relevant regulations.
Big data analytics
The horizontal scalability and programmability of object storage make it a natural choice for storing and processing large volumes of unstructured data in big data analytics platforms. Custom metadata schemes can be used to enrich the data and enable more advanced analytics capabilities.
Media storage and delivery
Object storage is a popular choice for storing and delivering media files, such as images, video, and audio. Its scalability and performance make it well-suited to handling large volumes of media files, while its support for various data formats and access methods enables seamless integration with content delivery networks and other media delivery solutions.
Internet of Things (IoT)
As the number of connected IoT devices continues to grow, so too does the amount of data they generate. Object storage is well-suited to handle the storage and management of this data, thanks to its scalability, flexibility, and support for unstructured data formats.
How to Choose an Object-Based Storage Solution
When choosing an object storage solution, there are several factors to consider. Some of the most important factors include:
- Scalability: One of the primary strengths of object storage is its ability to scale horizontally, so it’s essential to choose a platform that can grow with your organization’s data needs. Look for a solution that can easily accommodate massive amounts of data without sacrificing performance or manageability.
- Data durability and protection: Ensuring the integrity and availability of your data is critical, so look for an object storage platform that offers robust data protection features, such as erasure coding, replication, or versioning. Additionally, consider the platform’s durability guarantees – how likely is it that your data will be lost or corrupted?
- Cost: Cost is always a consideration when choosing a storage solution, and object storage is no exception. Be sure to evaluate the total cost of ownership (TCO) of the platform, including factors such as hardware, software, maintenance, and support costs. Additionally, if you’re considering a cloud-based solution, be sure to factor in the costs of data transfer and storage.
- Performance: While object storage is not typically designed for high-performance, low-latency workloads, it’s still important to choose a platform that can deliver acceptable performance for your organization’s specific use cases. Consider factors such as throughput, latency, and data transfer speed when evaluating performance.
- Integration and compatibility: The ability to integrate the object storage platform with your existing infrastructure and applications is essential. Look for a solution that supports industry-standard APIs and protocols, as well as compatibility with your organization’s preferred development languages and tools.
See Additional Guides on Key Data Security Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of data security.
Data Lake
Authored by Cloudian
- [Guide] What Is a Data Lake? Architecture and Deployment
- [Guide] Data Lakehouse: Is It the Right Choice for You?
- [Whitepaper] Object Storage: Customer Insights and Best Practices
- [Product] HyperStore Object Storage
Veeam
Authored by Cloudian
- [Guide] Veeam: Solutions, Use Cases, and Implementation Steps
- [Guide] Veeam Backup: 5 Key Solutions, Features and Capabilities
- [Whitepaper] TCO Report: Cloudian HyperStore File
- [Product] HyperStore Object Storage
PCI Compliance
Authored by Exabeam