

Request a Demo
Join a 30 minute demo with a Cloudian expert.
Data analytics delivers insights, and the bigger the dataset, the more fruitful the analyses. However, storing massive amounts of data creates big challenges: cost, complexity, scalability, and data protection. To efficiently derive insight from information requires affordable, highly scalable storage that’s simple, reliable, and compatible with the tools you have.
Modernize your enterprise analytics infrastructure to a data lakehouse – the data analytics architecture of the cloud – by combining the flexibility, cost-efficiency, and scale of S3 data lakes with the data management and ACID transactions of data warehouses. Cloudian HyperStore provides a cost-effective, on-premises S3 data platform built on open standards that integrates seamlessly with the leading data warehouse platforms to bring the data lakehouse concept from the cloud to on-prem deployments for a true hybrid experience.
Get this one-pager to understand the “7 Reasons to Run Data Analytics on a Cloudian S3 Data Lakehouse.“
Modern data analytics storage architecture follows the cloud architecture. It separates the compute and storage requirements by using S3 object storage as the economical and scalable data lake for all analytic data storage needs. With this S3 data lake, you can collect and manage huge-scale datasets, perform real-time data analytics, and get insights that generate real business value.
Typically, data lakes are composed of hard disk drives due to the media’s lower cost. However, flash storage is gaining popularity due to its decreasing cost and performance gains. When flash is used, systems can be built purely on flash media or can be built using hybrid configurations of flash and disk storage.
These data lakes can store massive amounts of structured and unstructured data. To accommodate this, the storage tier is usually built with object storage with S3 API being the standard means of communication. These storage types are not restricted to specific capacities and typically volumes scale to terabyte or petabyte sizes.
When configuring and implementing data analytics storage, there are a few common challenges you might encounter. All of these challenges take different shapes when running on the public cloud vs. on-premises storage.
| Challenge | Cloud vs. On-Premises |
| Size and storage costs Data grows geometrically, requiring substantial storage space. As data sources are added, these demands increase further and need to be accounted for. When implementing data analytics storage, you need to ensure that it is capable of scaling at the same rate as your data collection. | Public cloud storage services offer simplicity and high durability. However, storage is priced per GB/month, with extra fees for data processing and network egress. Running data analytics on-premises delivers major cost savings because it eliminates these large, ongoing costs. |
| Data transfer rates When you need to transfer large volumes of data, high transfer rates are key. In data analytics environments, data scientists must be able to move data quickly from primary sources to their analysis environment. | Public cloud resources are often not well suited to this demand. On-premises, you can leverage fast LAN network connections, or even directly connect storage to the machines that store the data. |
| Security Data frequently contains sensitive data, such as personally identifiable information (PII) or financial data. This makes this data a prime target for criminals and a liability if left unprotected. Even unintentional corruption of data can have significant consequences. | To ensure your data is sufficiently protected, data storage systems need to employ encryption and access control mechanisms. Systems also need to be capable of meeting any compliance requirements in place for your data. Generally, you’ll have greater control over data security on-premises or in private clouds than on public clouds. |
| High availability Regardless of what resources are used, you need to ensure that data remains highly available. You should have measures in place to deal with infrastructure failures. You also need to ensure that you can reliably and efficiently retrieve archived data. | Public clouds have strong support for this requirement. When running on-premises, ensure your data storage solution supports clustering and replication of storage units, to provide redundancy and high durability on par with cloud storage services. |
When implementing data analytics storage solutions, there are several best practices to consider.

Define Requirements
Start by inventorying and categorizing your data. Take into account frequency of access, latency tolerance, and compliance restrictions.

Use Data Tiering
Use a storage solution that lets you move data to lower-cost data tiers when lower durability, lower performance, or less frequent access is required.

Data Protection & Disaster Recovery
Set policies for data backup and restoration and ensure storage technology meets your Recovery Time Objective (RTO) and Recovery Point Objective (RPO).

The combination of Cloudian and Snowflake addresses increasing interest from customers in running analytics applications on data in place rather than having to move that data to a public cloud, which can be costly and time–consuming. Designed from its inception to be fully S3 compatible, HyperStore can be deployed as a private cloud in an organization’s data center or as part of a hybrid cloud strategy, with data being replicated or tiered to public cloud service providers. Bring your Snowflake environment on-prem with Cloudian S3-compatible storage

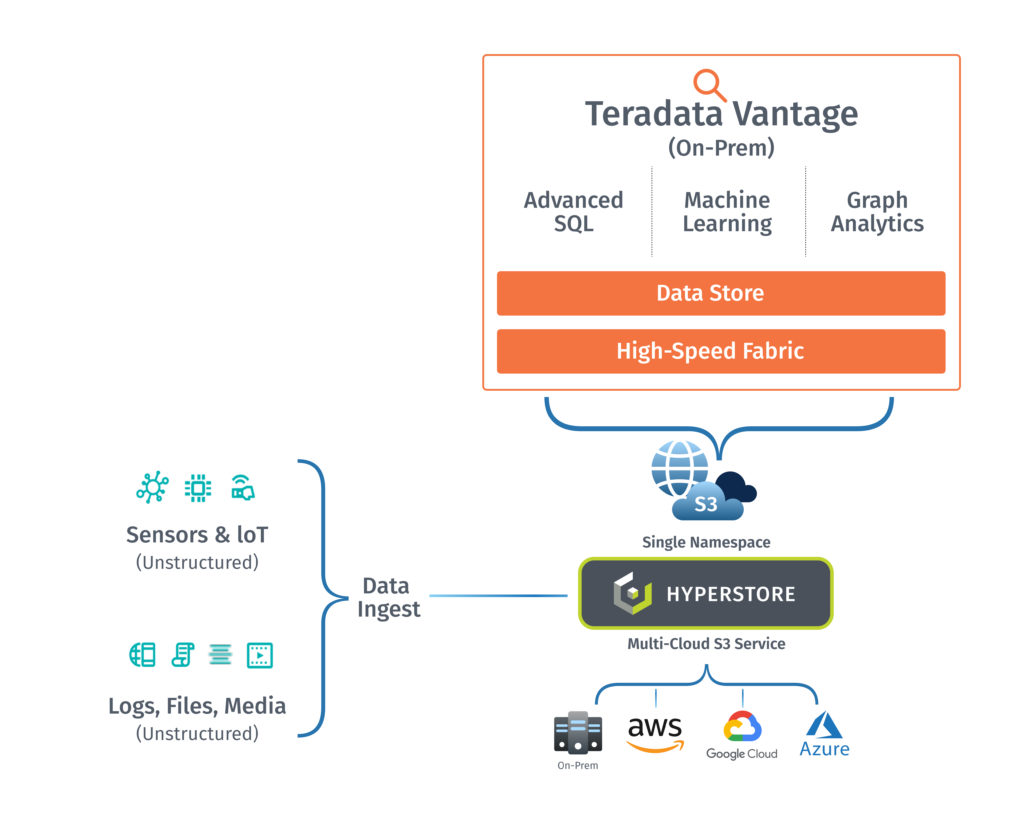
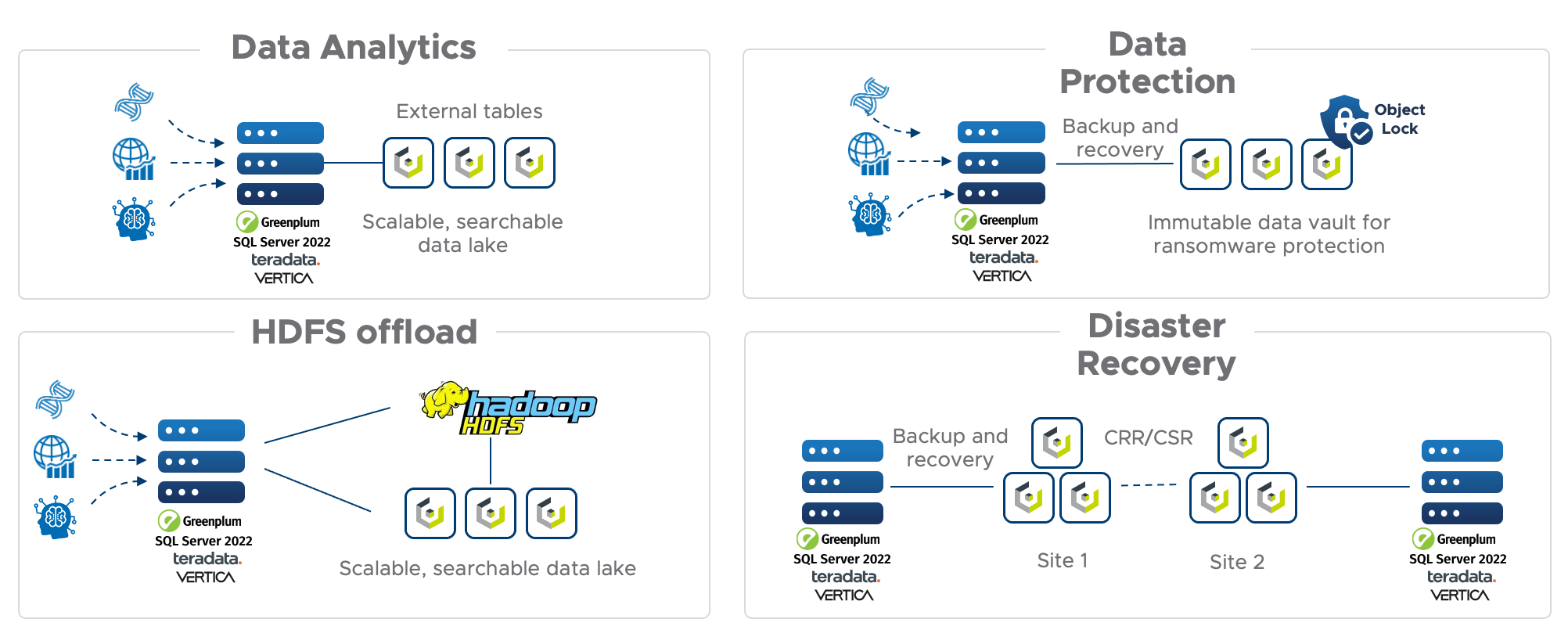
Teradata’s Vantage platform is the connected multi-cloud data platform for enterprise analytics that enables customers to use any tool, any language, and all their data to deliver answers that matter. Vantage unifies and integrates any type of data from sources within your organization and integrates directly with Cloudian’s HyperStore to store your data. With native support for S3 API, Vantage and HyperStore allow customers to connect and analyze data stored directly in a HyperStore data lakehouse, bringing the capabilities of a cloud data warehouse architecture on-prem for the speedy insights only possible with analytics-in-place.
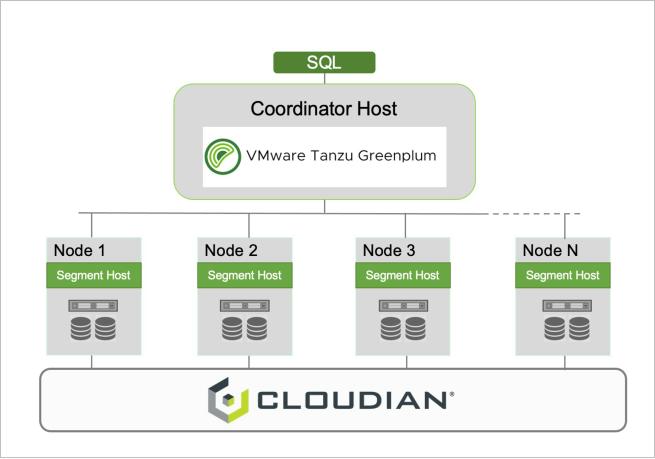
This VMware-certified solution enables new efficiencies and savings and is ideal for the creation and deployment of advanced analytics models for complex enterprise applications. Cloudify your analytics infrastructure with an affordable, manageable, and scalable solution built on open standards, with the ability to expand to petabyte and scale on-demand.


In Eon Mode, Vertica integrates with Cloudian HyperStore object storage, forming an S3 data lake to store all your data. With separation of compute and storage scale, customers can elastically and independently vary the number of compute nodes or HyperStore nodes depending on need.
Microsoft SQL Server 2022 introduces the capability to use a cloud data warehouse architecture on-premises. Cloudian HyperStore is fully validated to run SQL Server workloads for external tables ingesting data directly from S3 data lakes built on HyperStore, as well as for a solution to backup native SQL Server tables for data protection.

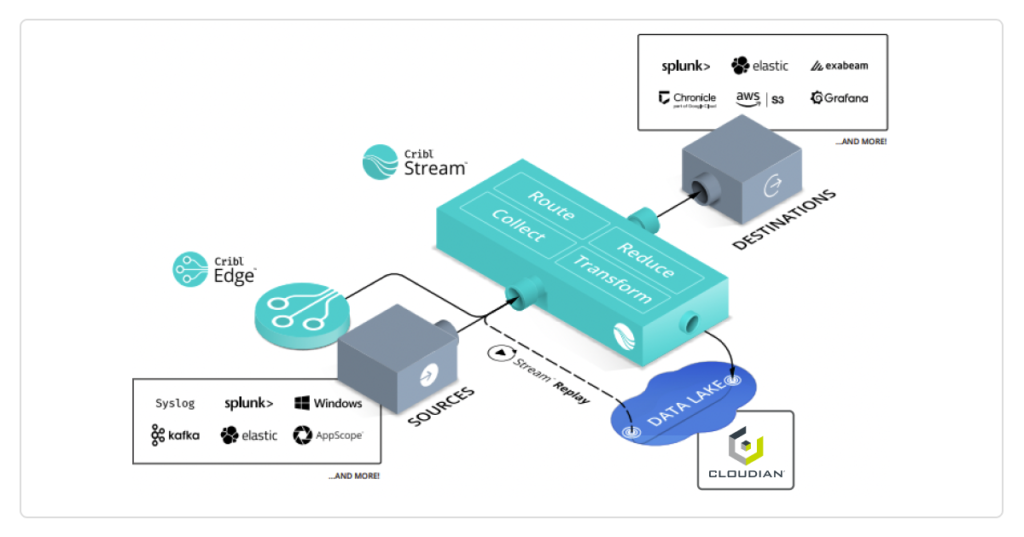

Cribl Stream is an observability pipeline that collects data from any source and can send and replay data to Cloudian HyperStore, a scale-out S3 data platform designed to manage massive amounts and varieties of data, forming a modern observability platform.
Together, the data lake solution built using Cribl and Cloudian lets you parse, restructure, and enrich data in flight, ensuring that you get the right data, where you want, and in the formats you need.
Cloudian® HyperStore® and Splunk SmartStore reduce data storage costs by 60% while increasing storage scalability. Together they provide an exabyte-scalable storage pool that is separate from your Splunk indexers.
With SmartStore, Splunk Indexers retain data only in hot buckets that contain newly indexed data. Older data resides in the warm buckets and is stored within the scalable and highly cost-effective Cloudian cluster.
SOLUTION SPOTLIGHT

Elasticsearch, the leading open-source indexing, and search platform, is used by enterprises of all sizes to index, search, and analyze their data and gain valuable insights for making data-driven business decisions. Ensuring the durability of these valuable insights and accompanying data assets has become critical to enterprises for reasons ranging from compliance and archival to continued business success.
Improve data insights, data management and data protection for more users with more data within a single platform
Combining Cloudera’s Enterprise Data Hub (EDH) with Cloudian’s petabyte scalable object-based storage platform provides a complete end-to-end approach to store and access unlimited data with multiple frameworks.
SOLUTION SPOTLIGHT