

What is AWS S3?
Amazon Simple Storage Service (S3) is a scalable object storage service provided by AWS. It allows users to store and retrieve any amount of data at any time from anywhere on the web. S3 delivers high data durability and scales to trillions of objects. The service is commonly used for data backup, content storage and distribution, and as a data lake for big data analytics.
S3 organizes data into buckets, each of which can hold an unlimited number of objects. Objects consist of data and metadata, and they are identified within a bucket by a unique key (name). Users can configure buckets for various settings including versioning, access permissions, and lifecycle policies to manage data storage.
What is the S3 API?
The S3 API is a RESTful web service interface provided by Amazon S3. It allows developers to interact programmatically with S3 storage to perform various operations on the stored data. The API supports common HTTP methods such as GET, PUT, DELETE, and POST, enabling users to upload, retrieve, delete, and manage data in their S3 buckets.
The S3 API provides a range of functionality including creating and managing buckets, uploading and downloading objects, copying objects between buckets, setting object permissions, and retrieving object metadata.
It supports simple operations for basic data management and advanced operations for fine-grained control over data and access permissions. Authentication for the API is typically handled using AWS Signature Version 4 to ensure secure access and integrity of the requests.
In this article:
- S3 API Common Request Headers
- S3 API Common Response Headers
- Amazon S3 API Common Actions
- Authenticating Requests with AWS Signature Version 4
- Amazon S3 API Code Examples
This is part of an extensive series of articles about S3 Storage.
What’s new in the S3 API?
AWS continues to expand the S3 API beyond basic object storage operations, adding new capabilities for high-performance workloads, analytics, metadata management, and data integrity. Recent updates include:
- Support for S3 Express One Zone directory buckets, which provide very low-latency access and use a specialized set of bucket and object APIs for high-performance applications.
- AWS has also introduced the RenameObject API for S3 Express One Zone, allowing objects to be renamed within the same directory bucket in a single API call without copying and deleting the object.
- Another major addition is Amazon S3 Tables, which adds API operations for managing table buckets, namespaces, and Apache Iceberg tables directly in S3. This makes S3 more useful for analytics workloads by allowing structured table data to be stored and queried using engines that support Apache Iceberg.
- AWS also provides dedicated S3 Tables API operations such as creating table buckets, creating tables, listing namespaces, managing table policies, and updating table metadata locations.
AWS has also expanded S3’s metadata and governance capabilities:
- S3 Metadata automatically captures object metadata and makes it available in queryable, read-only metadata tables that update as objects change.
- This helps users discover, audit, and analyze objects without having to scan entire buckets manually.
Recent API changes also focus on stronger data integrity:
- AWS has added more checksum options for S3, including additional algorithms such as MD5, SHA-512, XXHash3, XXHash64, and XXHash128, along with support for S3 Inventory on directory buckets.
- These improvements give developers more flexibility when validating uploads, downloads, replication, and large-scale object workflows.
S3 API Common Request Headers
An Amazon S3 request typically contains the following headers:
- Authorization—information needed to authenticate the request, depending on your signing method (see the Authenticating Requests section below)
- Content-Length—this is required for PUT operations and any other operation that loads XML, for example access control lists (ACLs) and logging. Supply the length of the message without header as defined in RFC 2616.
- Content-Type—type of resource, needed if the request content is included in the body of the message.
- Content-MD5—base64-encoded 128-bit MD5 message digest, as specified in RFC 1864. This can be used as an integrity check, to verify the data received is the same as the data sent.
- Expect—use this header when using 100-continue and including a request body. This header tells the API endpoint that if the client receives acknowledgement, it will also send the body of the request.
S3 API Common Response Headers
Here are response headers that are common to most AWS S3 responses.
| Name | Description | Data Type | Default Value |
| Content-Length | Length of response body in bytes. | String | N/A |
| Content-Type | MIME type of request content. For example: Content-Type: text/html; charset=utf-8 |
String | N/A |
| Connection | Notifies the client if server connection is currently open. Values can be open or close. | Enum | None |
| Date | Timestamp of the response from S3 responded, for example: Tue, 01 Jun 2021 14:00:00 GMT |
String | None |
| ETag | Represents a version of the object. It reflects changes to the contents of an object, not to the metadata. In some cases, the ETag can be an MD5 digest of object data. | String | N/A |
| Server | The name of the server that created the response. | String | AmazonS3 |
Amazon S3 API Common Actions
GetObject
This action is used to retrieve objects from S3. Note that you must first have READ access to an object before you can use GET. To return an object without using an authorization header, you need to grant READ access to an anonymous user.
CopyObject
This action is used to create a copy of an object currently stored in S3. Note that any copy request must be authenticated before it is authorized. You need read access to the source object as well as write access to the destination bucket.
PutObject
This action helps you add an object into your bucket. To do this, you need WRITE permissions on the bucket. However, note that Amazon S3 is designed as a distributed system. This means that when receiving multiple write requests for a single object—simultaneously—the system overwrites all objects except the last one written.
S3 does not offer object locking, but there are ways to introduce this option. You can either build object locking into your application layer or, alternatively, you can use versioning.
HeadObject
This action can retrieve metadata from your object without returning the object itself. It is highly useful if you only need the metadata of the object. Before you can use HEAD, you need to make sure you have READ access.
ListObjects
This option can return some or all—up to 1,000—of the objects inside a single bucket. To return a subset of the objects, you can use the request parameters as selection criteria. You should design your application to parse the contents of a response. The application also needs to know how to appropriately handle responses.
CreateBucket
This option can create new S3 buckets. Keep in mind this requires authenticating requests with an Access Key ID, which you receive when you register with S3. This is because the system does not allow anonymous requests to create buckets. Whoever creates a bucket becomes the owner of the bucket.
GetBucketPolicy
This action can return the policy of a certain bucket. To use this option, make sure that the service making the API call has the permission to get the specified bucket (the IAM permission is called GetBucketPolicy). Keep in mind that you can only use this action is the service making the API call belongs to the same account owner who originally created the bucket.
CreateMultipartUpload
This action can initiate a multipart upload and return an upload ID. The returned upload ID ihelps associate all components in a specific multipart upload.
UploadPart
This action can upload one part of a multipart upload. This first requires starting a multipart upload. S3 will return an upload ID for the multipart operation, which you must include in the upload part request.
See the documentation for a list of all S3 API operations.
Authenticating Requests with AWS Signature Version 4
Interactions with Amazon S3 may be either anonymous or authenticated.
Depending on how you sign your requests, AWS Signature Version 4 offers several benefits:
- Verification of requester’s identity—every request must have a signature to be authenticated. The signature is created using access keys, and a security token is also required when using temporary credentials.
- Protection of data in transit—the request signature is calculated using the request elements, to protect the request in transit. When Amazon S3 receives a request, it calculates the signature based on specified request elements, so if a request includes a component that doesn’t match the signature calculation, S3 will reject it.
- Prevention of request reuse—the signed portions of a request remain valid for 15 minutes once the request is sent. If an unauthorized user has access to a signed request, they can modify unsigned portions during this 15 minute window, and the request will still be accepted as valid. To prevent this scenario, you can use HTTPS to send requests, sign request headers and bodies, and set up AWS policies with the s3:x-amz-content-sha256 condition key so that users must sign request bodies.
Authentication data can be expressed using a variety of methods, including:
- HTTP Authorization—the HTTP Authorization header is the standard authentication method for Amazon S3 requests. It is a requirement of any Amazon S3 REST operation, with the exception of browser-based uploads that use POST requests.
- Query strings—the parameters in a query string can be used to express a URL request. The query parameters provide the necessary request information, including authentication data. This is sometimes called a presigned URL, because the URL contains the request signature, and it is useful for embedding clickable links in HTML, which remain valid for up to a week.
- Browser-based uploads—you can use HTTP POST requests to perform browser-based uploads to Amazon S3. A POST request allows you to directly upload content from your browser.
See the documentation for more details about S3 authentication.
Amazon S3 API Code Examples
Here are a few examples showing how to work with the API in two common programming languages—Java and Python. In addition to these languages, S3 provides SDKs for C++, Go, JavaScript, .NET, Node.js, PHP, and Ruby.
AWS SDK for Java
The code below was provided as part of the AWS Java SDK documentation.
To create a bucket, use the createBucket method in the AmazonS3 client. The method returns the new bucket, or an exception if the bucket exists. See the code example below.
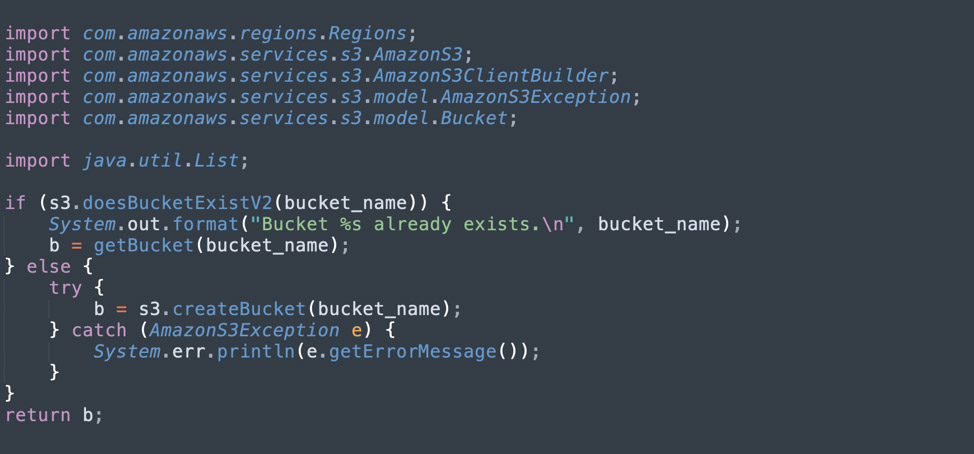
To list buckets, use the listBucket method, which returns a list of buckets. See the code example below.

AWS SDK for Python
The following examples were provided as part of the Boto3 documentation. The methods below are provided as part of the S3 Client, Bucket, and Object classes.
To upload files, use one of these methods.
- Use upload_file method, which accepts three parameters: file name, bucket name, and object name. This method is suitable for large files, because it can split them into smaller parts and upload different parts in parallel.
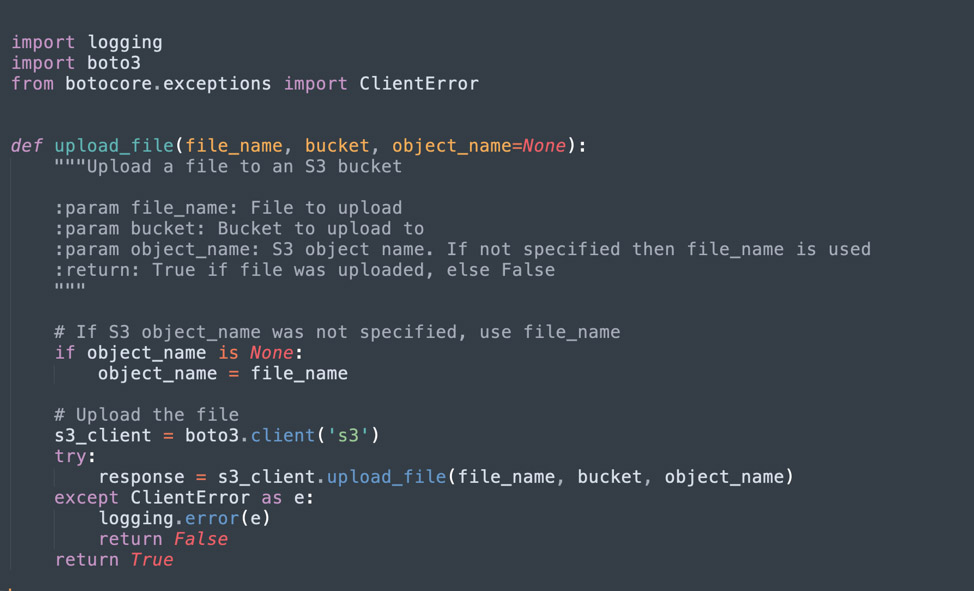
- The upload_fileobj method, which accepts a file object in binary format (not text format).

To download files, use the parallel methods to the ones shown above:
- Use the download_file method, passing the name of the bucket, name of the object to download, and local file name to save to. This is suitable for large files.

- Use the download_fileobj method, to download a writable object, provided in binary mode.

Tutorial: Setting Up Amazon S3 REST API Integration
Step 1: Create an AWS Account
Create an AWS account and verify your account to get it ready for API integration.
Step 2: Declare IAM Permissions for the API
The next step involves setting up IAM (Identity Access Management) permissions. We will start by creating a new role called APIGatewayS3Role.
Click Create Role and select AWS service under Trusted entity type. Under Service or use case, select API Gateway.
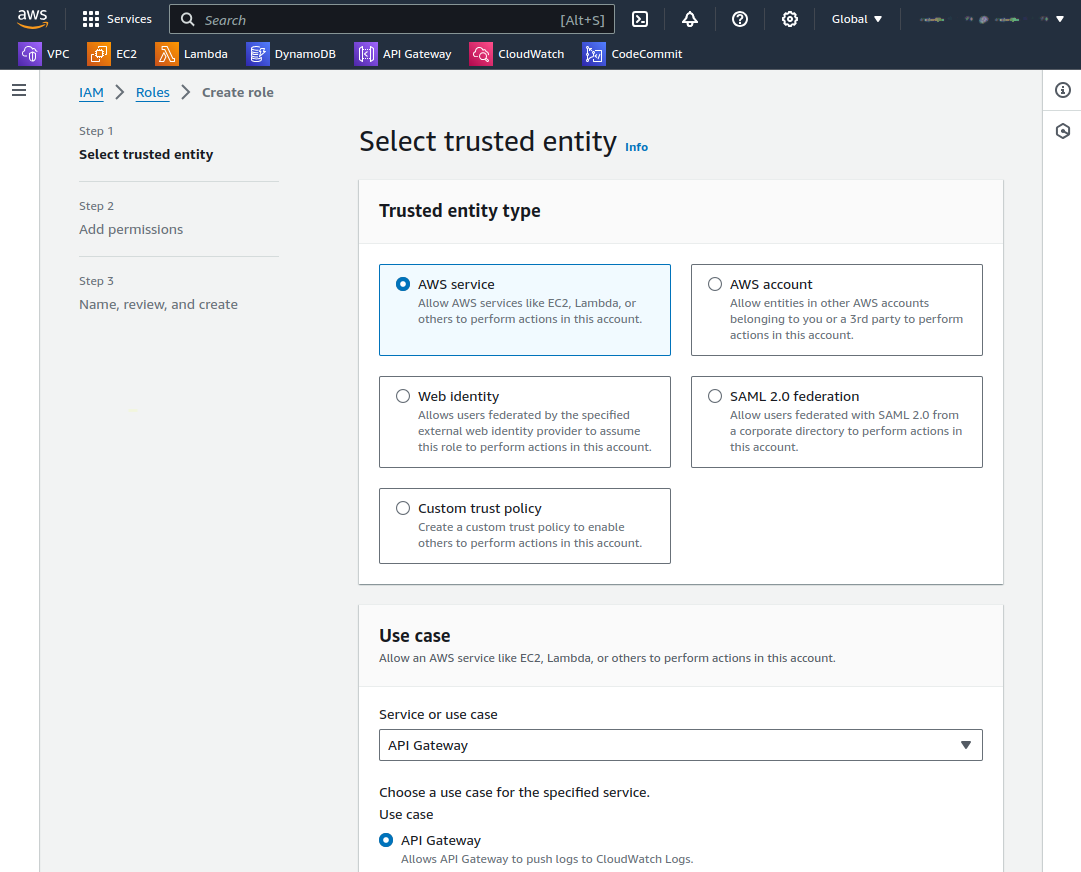
Click Next. Under Role name, enter APIGatewayS3APIRole, then click Create role.
Now search for the new role, as shown in the following screenshot:
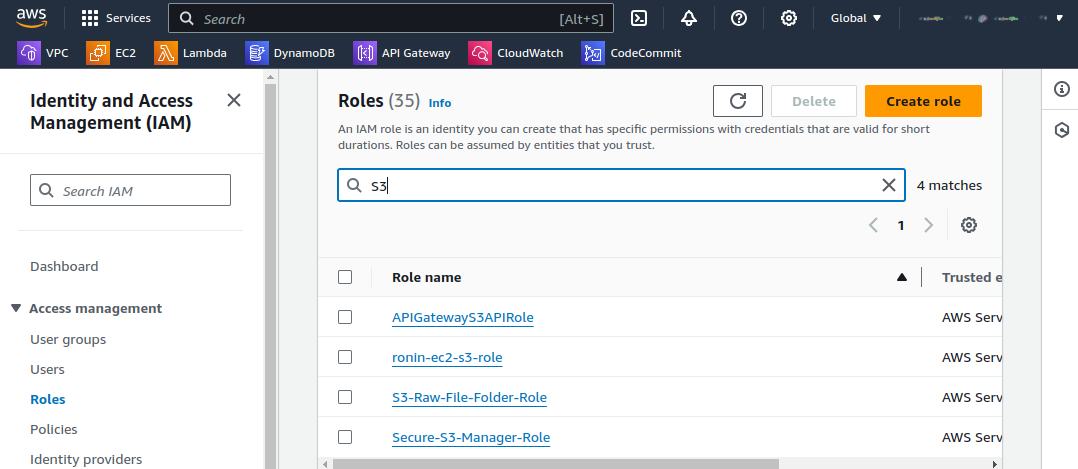
Select the newly created role and browse to the Add permissions tab. Choose Attach policies from the dropdown list. In the search bar, type AmazonS3FullAccess and choose Add permissions.
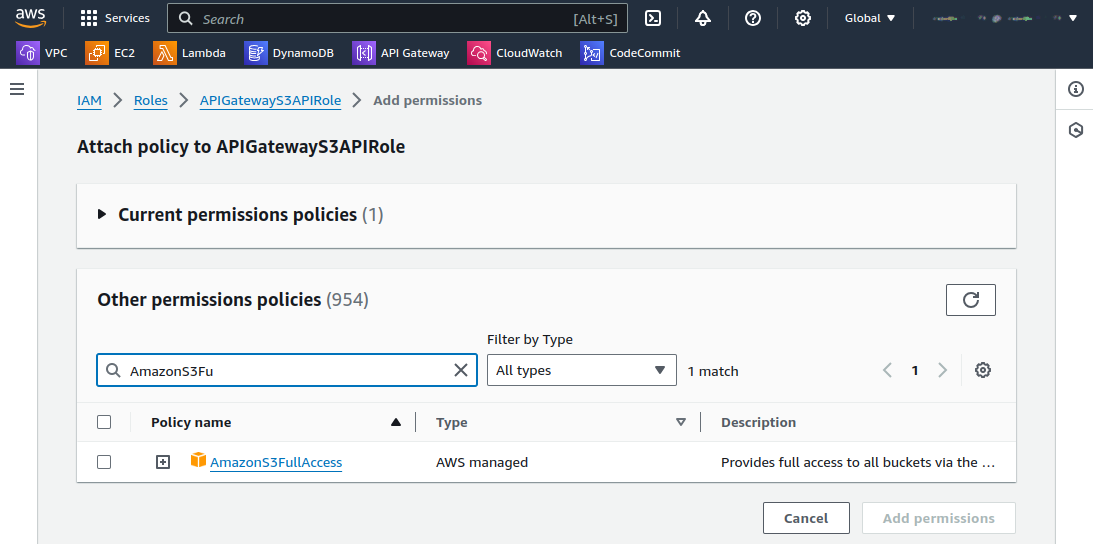
You should see the message: Policy was successfully attached to role.
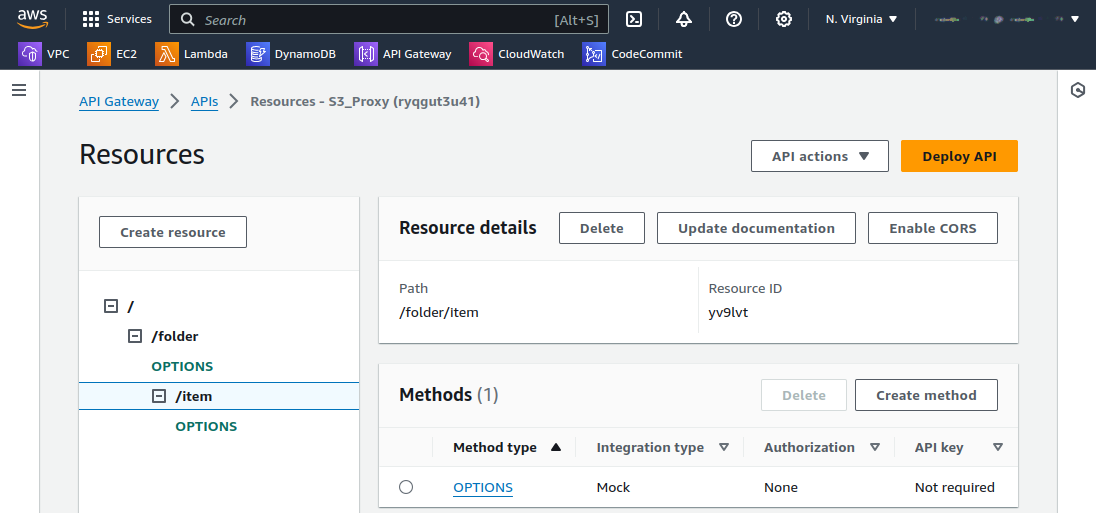
Step 3: Create and Establish API Resources
Use the API Gateway console to create a new REST API. Specify the resources for the relevant Amazon S3 bucket and object. In the console, create an API and then create a child resource called “Folder” with its resource path. Next, create an Item child resource with its respective path
Step 4: Create and Initialize API Method
Create and configure the API method to invoke S3 actions. In the Resources panel, select Actions > Create Method > GET. Define the resource path (e.g., s3-host-name/bucket/key) and select Use path override as the action type.
Include the IAM role ARN in the Execution role field. Save the configuration. Ensure IAM control is enabled for the GET method, and declare necessary response types using the Method Response box. Set up response header mappings for the GET method.
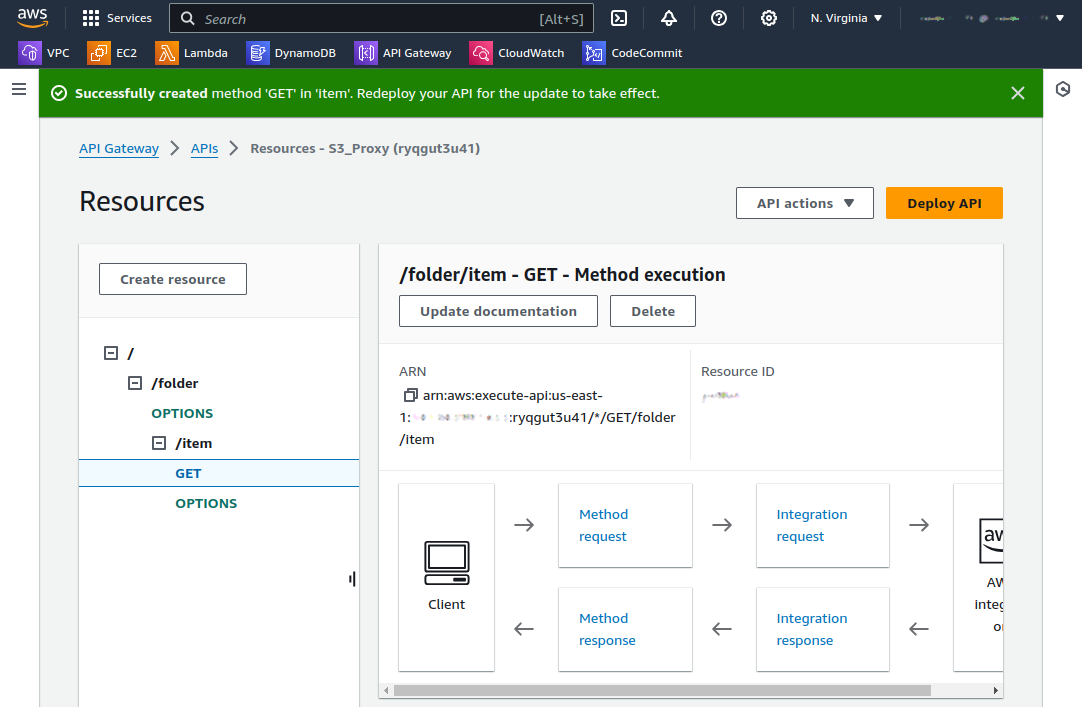
Step 5: Expose API Method’s Access to S3 Bucket
Expose GET, PUT, and DELETE methods. Use Method Request and Integration Request to map folders to the bucket. Ensure you set the message content type to application/xml
To test, provide the location constraint within the request payload:
<CreateBucketConfiguration xmlns=”http://s3.amazonaws.com/doc/2006-03-01/”>
<LocationConstraint>{region}</LocationConstraint>
</CreateBucketConfiguration>
Step 6: Render API Methods to Access an Object in S3 Bucket
Expose the PUT Object, GET Object, DELETE Object, and HEAD Object operations. This allows the API to access objects within the S3 bucket. Implement this with an additional “item” parameter.
Step 7: Call API via REST API Client
After deploying the API, use a REST API client like Postman to call the API. Authorize the client by creating security credentials (keys). Add a bucket (e.g., apig-demo-5) to the S3 account in a specified region.
For a PUT request, use the following URL:
https://api-id.execute-api.aws-region.amazonaws.com/stage/folder-name
Set the Content-Type header to application/xml and send the following body:
<CreateBucketConfiguration>
<LocationConstraint>{region}</LocationConstraint>
</CreateBucketConfiguration>
If everything is working properly, you should receive a 200 OK status.
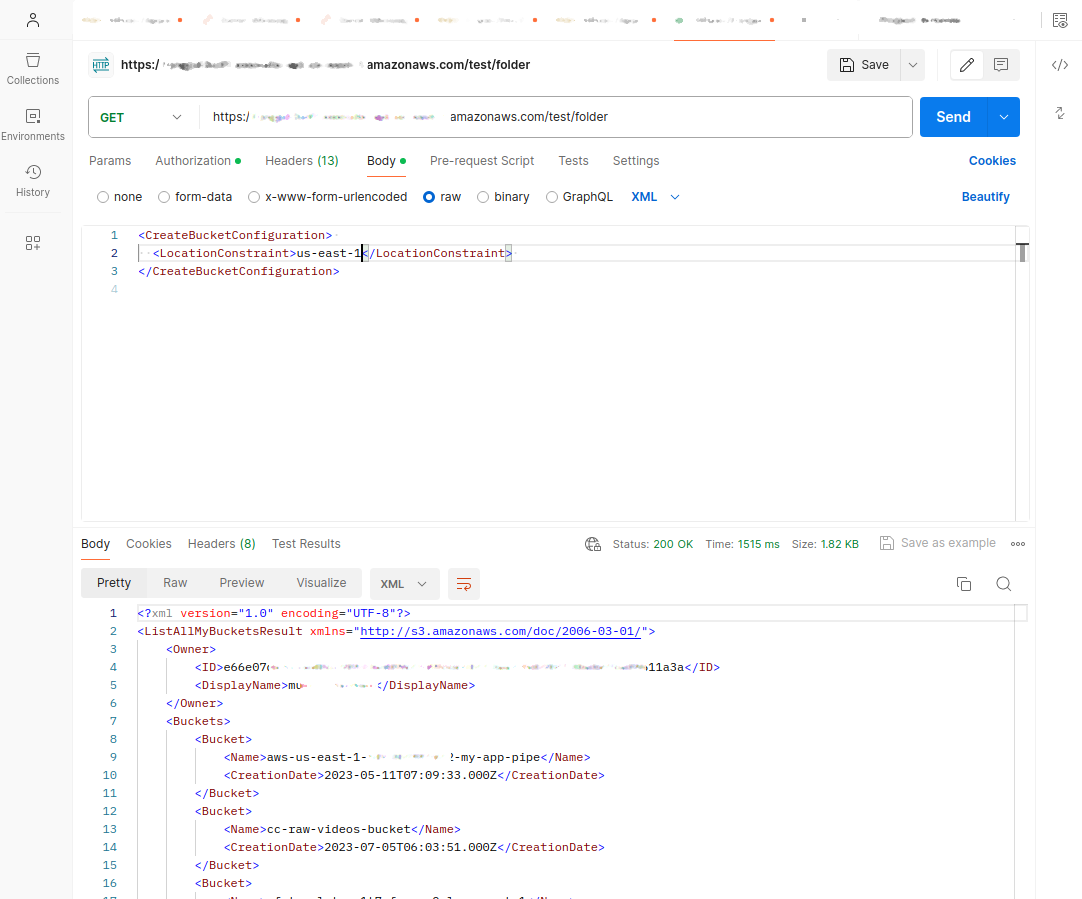
To add a file, use a PUT request like this:
PUT /S3/apig-demo-5/Readme.txt HTTP/1.1
Host: 9gn28ca086.execute-api.{region}.amazonaws.com
Content-Type: application/xml
X-Amz-Date: 20161015T062647Z
Authorization: AWS4-HMAC-SHA256 Credential=access-key-id/20161015/{region}/execute-api/aws4_request, SignedHeaders=content-length;content-type;host;x-amz-date, Signature=ccadb877bdb0d395ca38cc47e18a0d76bb5eaf17007d11e40bf6fb63d28c705b
Cache-Control: no-cache
Postman-Token: 6135d315-9cc4-8af8-1757-90871d00847e
<file contents>
To fetch a file’s content use a GET request like this:
GET /S3/apig-demo-5/Readme.txt HTTP/1.1
Host: 9gn28ca086.execute-api.{region}.amazonaws.com
Content-Type: application/xml
X-Amz-Date: 20161015T063759Z
Authorization: AWS4-HMAC-SHA256 Credential=access-key-id/20161015/{region}/execute-api/aws4_request, SignedHeaders=content-type;host;x-amz-date, Signature=ba09b72b585acf0e578e6ad02555c00e24b420b59025bc7bb8d3f7aed1471339
Cache-Control: no-cache
Postman-Token: d60fcb59-d335-52f7-0025-5bd96928098a
List items in an S3 bucket:
GET /S3/apig-demo-5 HTTP/1.1
Host: 9gn28ca086.execute-api.{region}.amazonaws.com
Content-Type: application/xml
X-Amz-Date: 20161015T064324Z
Authorization: AWS4-HMAC-SHA256 Credential=access-key-id/20161015/{region}/execute-api/aws4_request, SignedHeaders=content-type;host;x-amz-date, Signature=4ac9bd4574a14e01568134fd16814534d9951649d3a22b3b0db9f1f5cd4dd0ac
Cache-Control: no-cache
Postman-Token: 9c43020a-966f-61e1-81af-4c49ad8d1392
Successful responses will return a 200 OK status with the appropriate XML payload.
How Cloudian Provides S3-Compatible On-Premise Object Storage
Cloudian® HyperStore® is a massive-capacity object storage device that is fully compatible with the Amazon S3 API. It can store up to 1.5 Petabytes in a 4U Chassis device, allowing you to store up to 18 Petabytes in a single data center rack. HyperStore comes with fully redundant power and cooling, and performance features including 1.92TB SSD drives for metadata, and 10Gb Ethernet ports for fast data transfer.
HyperStore is an object storage solution you can plug in and start using with no complex deployment. It also offers advanced data protection features, supporting use cases like compliance, healthcare data storage, disaster recovery, ransomware protection and data lifecycle management.
Cloudian not only supports the basic S3 API commands but also the following advanced object storage APIs. As shown in the table, some of these features are unique to S3 and not supported by other cloud providers.
| Amazon S3 API Feature | Azure | Google Cloud | OpenStack Swift |
| Object versioning | No | Yes | Yes |
| Object ACL | No | Yes | No |
| Bucket Lifecycle Expiry | No | Yes | Yes |
| Multi-object delete | No | Yes | Yes |
| Server-side encryption | No | Yes | Yes |
| Server-side encryption with customer keys | No | No | No |
| Cross-region replication | Yes | No | Yes |
| Website | No | No | No |
| Bucket logging | No | No | No |
| POST object | No | No | No |
In addition to supporting all these APIs out of the box, Cloudian has taken four other measures to make its storage solution S3 object storage enterprise-ready:
- Software or Appliance, not a service: Cloudian’s software-only package includes a Puppet-based installer with a wizard-style interface. It runs on commodity software (CentOS/RedHat) and commodity hardware. The appliances come in a few fixed models ranging from 1U (24TB) to the FL3000 series of PB-scale in 8U form.
- APIs for all functions: Configuration, Multi-Tenancy (User/Tenant provisioning), Quality of Service (QoS), Reporting, and S3 Extensions including compression, metadata
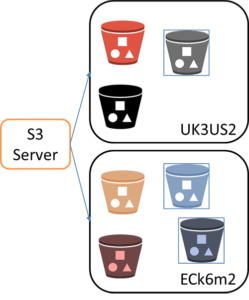
- Per-bucket protection policies: For example, a “UK3US2” policy can be defined as UK DC with 3 replicas and US DC with 2 replicas. Another example is a “ECk6m2” policy as DC1 with Erasure Coding with 6 data and 2 coding fragments. As buckets are created they can be assigned a policy.
- Operations and maintenance tools: Can be used to install, monitor, and manage the S3-compatible storage. In addition to the installer, a single pane web-based Cloudian Management Console (CMC) enables system administration from the perspective of the system operator, a tenant/group administrator, and a regular user. It’s used to provision groups and users, view reports, manage and monitor the cluster.
- Integration with other enterprise systems: NFS/CIFS file interface, OpenStack, CloudPlatform, tiering to any S3 system (public or private), Active Directory, and LDAP.
Amazon S3 API compatibility ensures full portability of already working applications. Using Cloudian’s HyperStore platform instead of AWS, enterprise data can be brought on-premise for better data security and manageability at lower cost.
For Storage as a Service (STaaS) providers, S3 API compatibility, backed by a full guarantee, provides the same benefits of a fully controlled storage platform, and opens up a large range of compatible applications.
If you would like a technical overview, see our webinar: S3 Technical Deep Dive.
Learn more about Cloudian® HyperStore®.