

This blog describes how to integrate Cloudian HyperStore with the Confluent platform to provide a limitlessly scalable repository for Apache Kafka workflows.
Integrating the Confluent platform with Cloudian, a distributed object storage system, provides organizations with a scalable, reliable, and cost-effective solution for handling streaming data. This integration is especially beneficial for businesses that rely on both high-volume data streams and low-cost, durable storage.
This post covers what each of these technologies brings to the table and how their integration helps streamline data management and storage processes.
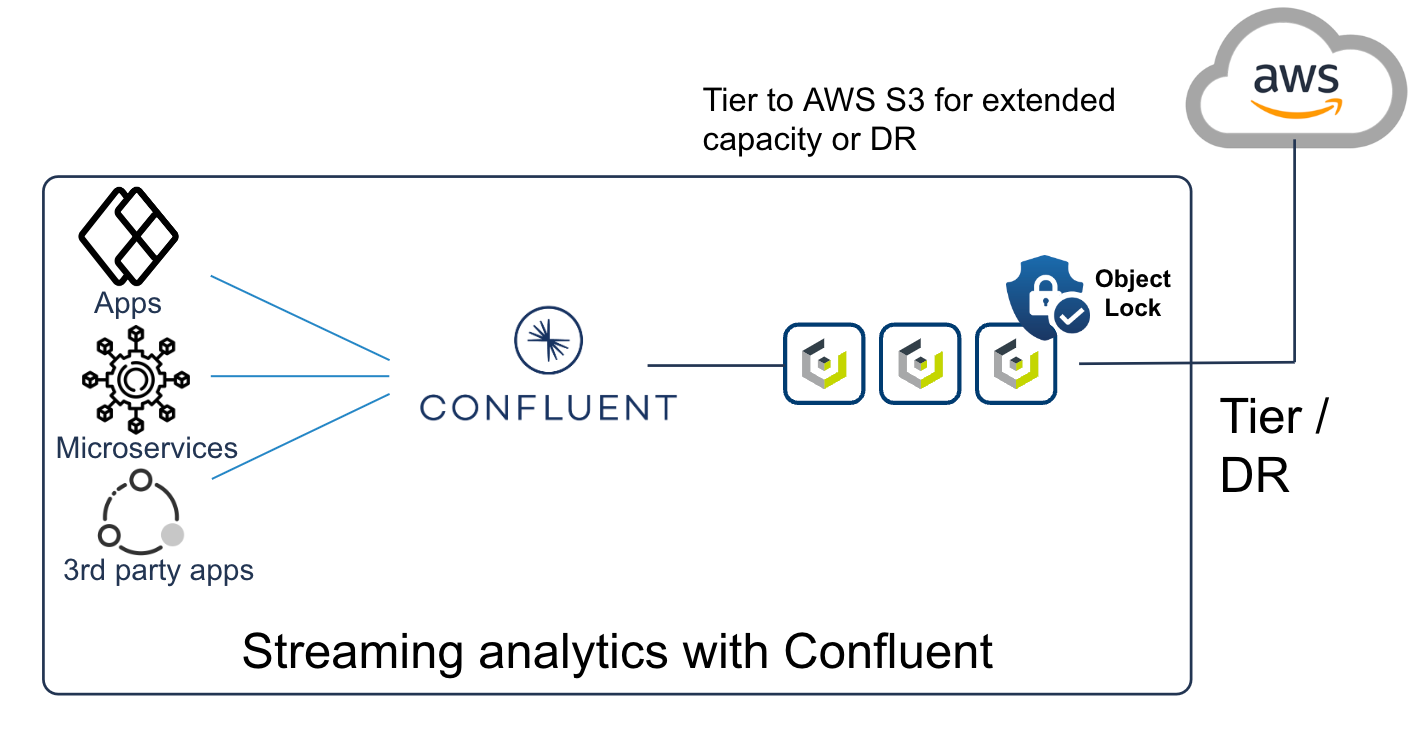
Understanding Cloudian HyperStore and Confluent Platform
Cloudian HyperStore
Cloudian HyperStore is an object storage platform built to support massive data volumes, offering S3 compatibility, scalability, and cost-effectiveness. It’s designed for environments that require high durability and low storage costs, making it an ideal backend for data archiving, big data analytics, and backup solutions. HyperStore is especially valuable for handling unstructured data at scale, with the flexibility to be deployed on-premises, in hybrid environments, or across multiple cloud regions.
Confluent Platform
Confluent Platform is an enterprise-ready distribution of Apache Kafka, offering additional features and tools that make it easier to deploy, monitor, and secure Kafka at scale. Kafka acts as a real-time streaming data pipeline and messaging system, which allows applications to publish, subscribe to, and process streams of records in real-time. Confluent Platform builds on Kafka by adding Schema Registry, connectors, security, and other enterprise-grade capabilities, making it an ideal choice for organizations looking to leverage streaming data for analytics, AI, IoT, and beyond.
Benefits of Integrating Cloudian HyperStore with Confluent Platform
Combining Confluent Platform’s data streaming and processing capabilities with Cloudian HyperStore’s storage features provides a range of benefits:
- Scalability for High-Volume Data: As data ingestion grows, the combination of Kafka’s streaming capabilities and HyperStore’s scalability ensures a robust solution for data that needs to be accessed and processed in real-time and stored indefinitely.
- Cost-Effective Storage: HyperStore provides S3-compatible storage at a fraction of the cost of public cloud providers, offering on-premises storage that helps meet regulatory and latency requirements. This is particularly valuable when dealing with massive volumes of data that need cost-effective, durable storage over time.
- Data Durability and Redundancy: Cloudian HyperStore ensures data durability through replication or erasure coding, which minimizes data loss risks. For industries with strict compliance standards, this feature is critical.
- Enhanced Data Lifecycle Management: Integration allows for better lifecycle management where aged Kafka data can automatically be moved to Cloudian HyperStore for archival storage, freeing up Kafka resources for high-priority, real-time data.
- Hybrid and Multi-Cloud Flexibility: Cloudian’s S3 compatibility enables seamless data transfers between on-premises, hybrid, and public cloud environments. This flexibility is essential for organizations seeking to avoid vendor lock-in or needing specific data residency compliance.
Steps to Integrate Cloudian HyperStore with Confluent Platform
Organizations desiring to integrate Cloudian HyperStore with Confluent Platform 6.0 and later may use the tiering functionality native to the cluster. Here’s a simplified step-by-step guide:
- Configure Cloudian HyperStore for S3 Access: Ensure that Cloudian HyperStore is configured to support the S3 API. This involves setting up the necessary permissions, access credentials, and bucket configurations.
- Configure the Confluent Platform: The tiering connector is configured in the server.properties file Configure the connector by specifying:
- The Cloudian HyperStore endpoint as the S3-compatible endpoint.
- Access credentials and bucket name.
- Options for data formatting and partitioning.
confluent.tier.enable=true
confluent.tier.backend=S3
confluent.tier.s3.bucket=kafkadata
confluent.tier.s3.region=us-west-2
confluent.tier.metadata.replication.factor=3
confluent.tier.s3.aws.endpoint.override=https://s3-west.cloudian-pnslab.com
confluent.tier.s3.cred.file.path=/root/confluent-7.7.0/etc/kafka/creds
Use Cases for Confluent Platform and Cloudian HyperStore Integration
This integration is particularly useful in scenarios where data needs to be both processed in real-time and stored cost-effectively for long-term analysis or compliance purposes. Here are some key use cases:
- Data Lakes and Big Data Analytics: Streaming data pipelines often feed into data lakes for long-term analysis. Cloudian’s storage flexibility makes it easy to integrate with analytics frameworks, enabling deeper insights over archived Kafka data.
- Compliance and Regulatory Data Archival: Certain industries, like finance and healthcare, require long-term data storage for compliance. Confluent Platform can handle the real-time streaming, while HyperStore manages the retention, providing a reliable solution that meets strict regulatory standards.
- IoT and Edge Data: For industries using IoT devices that generate massive data streams, Kafka can handle real-time data ingestion, while HyperStore provides a scalable solution for storing raw data and processed insights from those devices.
Conclusion
Integrating Confluent Platform with Cloudian HyperStore offers a powerful solution for organizations dealing with high-velocity, high-volume data. The seamless flow from Kafka’s real-time data streaming to Cloudian’s durable, scalable storage ensures that data pipelines are both efficient and cost-effective. This integration meets the demands of today’s data-driven enterprises, enabling them to leverage streaming data in real-time while preserving historical data for future analysis or compliance.
By using this setup, organizations can leverage both on-premises and cloud environments flexibly, achieving a strategic advantage in data management that scales with their needs and optimizes their costs.

Gary Mirfield, Solutions Product Manager, Cloudian