

Imagine having an incredibly knowledgeable assistant who has read every manual, document, and piece of technical information in your organization. One that lets you instantly find exactly what you need when you ask a question in plain English. This unlocks the 80% of enterprise knowledge currently inaccessible to AI. That’s what the Cloudian HyperScale AI Data Platform can do.
Your Organizational Knowledge, At Your Fingertips
Most people are familiar with chatbots that give generic responses without benefit of your enterprise knowledge. Or search engines that return endless lists of links to sort through. This system is fundamentally different because it applies agents, making decisions and reasoning through problems without needing step-by-step instructions from humans.
Here’s how it works in simple terms: When you ask a complex question about your company’s systems or procedures, the AI doesn’t just search for keywords. Instead, it truly understands the meaning of your question, searches through vast amounts of your company’s documents and manuals, evaluates what information is most relevant, and then crafts a comprehensive answer that directly addresses what you’re trying to accomplish.
Secure and Fully On-Prem
The system runs entirely on the Cloudian HyperScale AI Data Platform —no information ever leaves your organization or goes to the cloud. This means your proprietary knowledge stays completely secure while giving you access to AI capabilities that were previously only available through external services.
The blog details how this system works, using Cloudian enterprise knowledge (in this case, a massive technical manual) as a knowledge base. This demonstrates that the AI can process thousands of pages of complex documentation and answer sophisticated questions about it in just a few seconds. Enterprise knowledge can now be instantly – and securely — accessible and useful to everyone in an organization.
For a quick demo, click here.
HyperScale AI Data Platform Under the Hood
HyperScale AI Data Platform is an AI system capable of autonomous knowledge retrieval and natural language response generation. The solution combines Retrieval-Augmented Generation (RAG) architecture with GPU acceleration to create a self-contained, data-sovereign AI system that can intelligently query and synthesize information from an internal knowledge base.
____________________________________________________________
Key Technical Highlights
- Agentic AI Architecture: Autonomous decision-making and multi-step reasoning without human intervention
- Data Sovereignty: Complete on-prem air-gapped deployment ensures organizational data never leaves your infrastructure
- GPU-Accelerated Pipeline: Purpose-built allocation across four GPUs for optimal performance
- Scalable Vector Search: Vector database supports billion-scale semantic similarity operations
- Enterprise-Ready LLM: Llama 3.2-3B-Instruct provides instruction-following and reasoning capabilities
- Zero-Shot Knowledge: No model retraining required for new document integration
- Multi-Modal Support: Extensible architecture supports text, image, and structured data processing
____________________________________________________________
System Architecture
AI Software Components
- AI Software Framework: The software stack leverages a comprehensive suite of enterprise retrieval components.
- Vector Database: At the heart of vector operations sits a vector database engineered for billion-scale similarity search operations.
- Language Model: The system employs Llama 3.2-3B-Instruct, Meta’s instruction-tuned transformer model optimized for dialogue and reasoning tasks, featuring a 128K token context window.
- Compute Infrastructure
The compute infrastructure centers around a dedicated AI processing node equipped with four GPUs, each allocated to specific functions within the pipeline:
- GPU 1: Llama 3.2-3B-Instruct LLM inference operations
- GPU 2: Vector database operations and similarity search
- GPU 3: AI software reranking processes and relevance scoring
- GPU 4: Shared resources for embedding generation and auxiliary functions
This balanced workload distribution maximizes throughput while preventing resource contention across the processing pipeline.
Storage Infrastructure
The system utilizes a three-node Cloudian HyperStore cluster, providing distributed, S3-compatible object storage that ensures both scalability and data durability for vector embeddings and index files. This storage foundation supports the massive scale requirements of enterprise knowledge bases while maintaining the high availability necessary for production AI workloads.
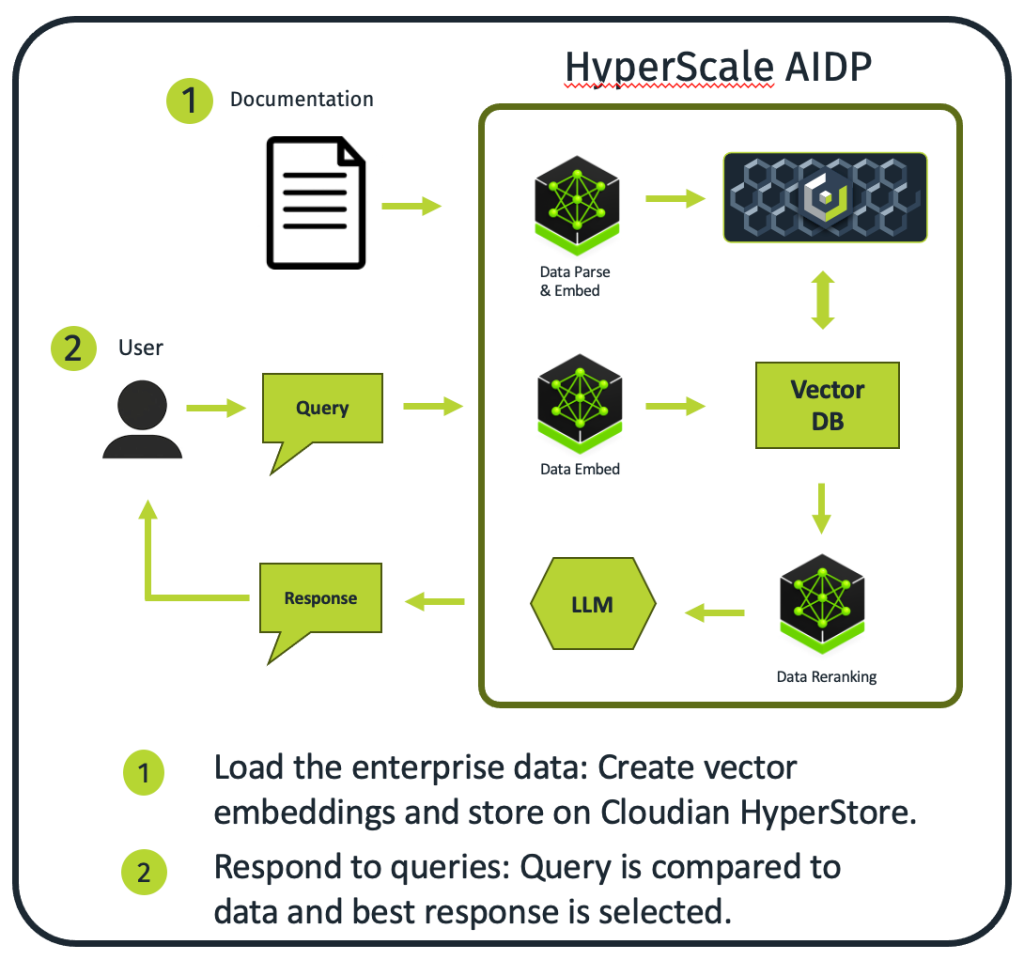
Implementation: Knowledge Base Ingestion Pipeline
The transformation of raw enterprise content into semantically searchable knowledge represents one of the most critical aspects of the agentic AI system. The document indexing process begins with the AI software components ingesting source material—in this implementation, the comprehensive Cloudian HyperStore Admin Guide spanning over 1,000 pages of technical documentation.
Processing Workflow:
- Document Parsing: Intelligent extraction and structuring of text while preserving contextual relationships and hierarchical information
- Semantic Embedding: Conversion of content chunks into 768-dimensional vectors using sophisticated transformer models
- Index Generation: Creation of optimized search structures within the vector database
- Storage Persistence: Durable storage of vectors and metadata within the HyperStore cluster
Performance Achievement: The entire ingestion pipeline completed processing of the Cloudian 1,000-page administrative guide in approximately five minutes, demonstrating the efficiency of the GPU-accelerated architecture and enabling rapid onboarding of new documentation without operational disruption.
AI Inference Workflow
Query Understanding and Analysis
The system’s capabilities emerge through its sophisticated approach to query processing, where multiple AI components work autonomously to understand user intent without predefined scripts or human oversight. When a user submits a natural language query, the system immediately begins semantic analysis, creating vector representations that can be mathematically compared against stored document vectors while autonomously determining optimal search parameters and retrieval strategies.
Autonomous Decision Making
Rather than simply returning highest-scoring similarity matches, the system employs sophisticated decision-making:
- Content Evaluation: Assessment of retrieved documents using learned relevance models
- Authority Weighting: Consideration of document credibility and source reliability
- Contextual Appropriateness: Analysis of information relevance to specific user queries
- Dynamic Resource Allocation: Automatic scaling of processing power based on query complexity
Multi-Agent Coordination
Throughout the inference process, the system maintains conversation history and user intent across multi-turn interactions while seamlessly orchestrating multiple AI components. The Llama 3.2-3B-Instruct model leverages its extensive context window to maintain awareness of extended conversations while processing large amounts of retrieved content to generate comprehensive responses.
Quality assurance mechanisms operate continuously, implementing confidence thresholds and fallback strategies to ensure reliable operation even when dealing with ambiguous or out-of-scope queries.
Enterprise Benefits
Data Sovereignty and Security
The solution addresses critical enterprise requirements through its completely air-gapped deployment model. Organizations can deploy the system entirely within their own infrastructure without external network dependencies, ensuring proprietary knowledge assets never leave organizational boundaries. This architecture supports compliance with strict regulatory requirements around data residency and access controls while providing advanced AI capabilities typically available only through cloud services.
Scalability and Operational Efficiency
From a scalability perspective, the solution demonstrates remarkable flexibility:
- Knowledge Base Agnostic: Processing capability for diverse technical documentation types
- Incremental Updates: Real-time knowledge base refresh without service interruption
- Resource Optimization: Purpose-built GPU allocation maximizing computational efficiency
- Autonomous Operation: Minimal manual intervention requirements reducing operational overhead
Cost Optimization
The efficient resource utilization and autonomous operation model provide predictable performance characteristics that enable reliable user experience planning while minimizing ongoing operational costs.
Use Case Applications
The agentic AI solution enables numerous enterprise applications across organizational functions:
- Technical Documentation Systems: Automated resolution of complex configuration questions and troubleshooting scenarios with instant access to relevant technical information.
- Customer Service Enhancement: Intelligent query resolution providing support agents with accurate technical information retrieval, reducing resolution times and improving customer satisfaction.
- Research and Development: Rapid access to organizational knowledge accelerating innovation by eliminating time spent searching for relevant information across disparate sources.
- Compliance and Training: Automated policy interpretation and guidance generation ensuring employees have access to current, accurate procedural information with contextual explanations.
- Knowledge Management: Centralized access to institutional knowledge with intelligent synthesis capabilities that can connect information across different domains and time periods.
Future Enhancements
The architecture supports future enhancements including multi-modal processing capabilities for images, diagrams, and structured data. Organizations can integrate additional knowledge sources or expand reasoning capabilities through fine-tuning or component upgrades without requiring fundamental changes.
For more information visit cloudian.com.