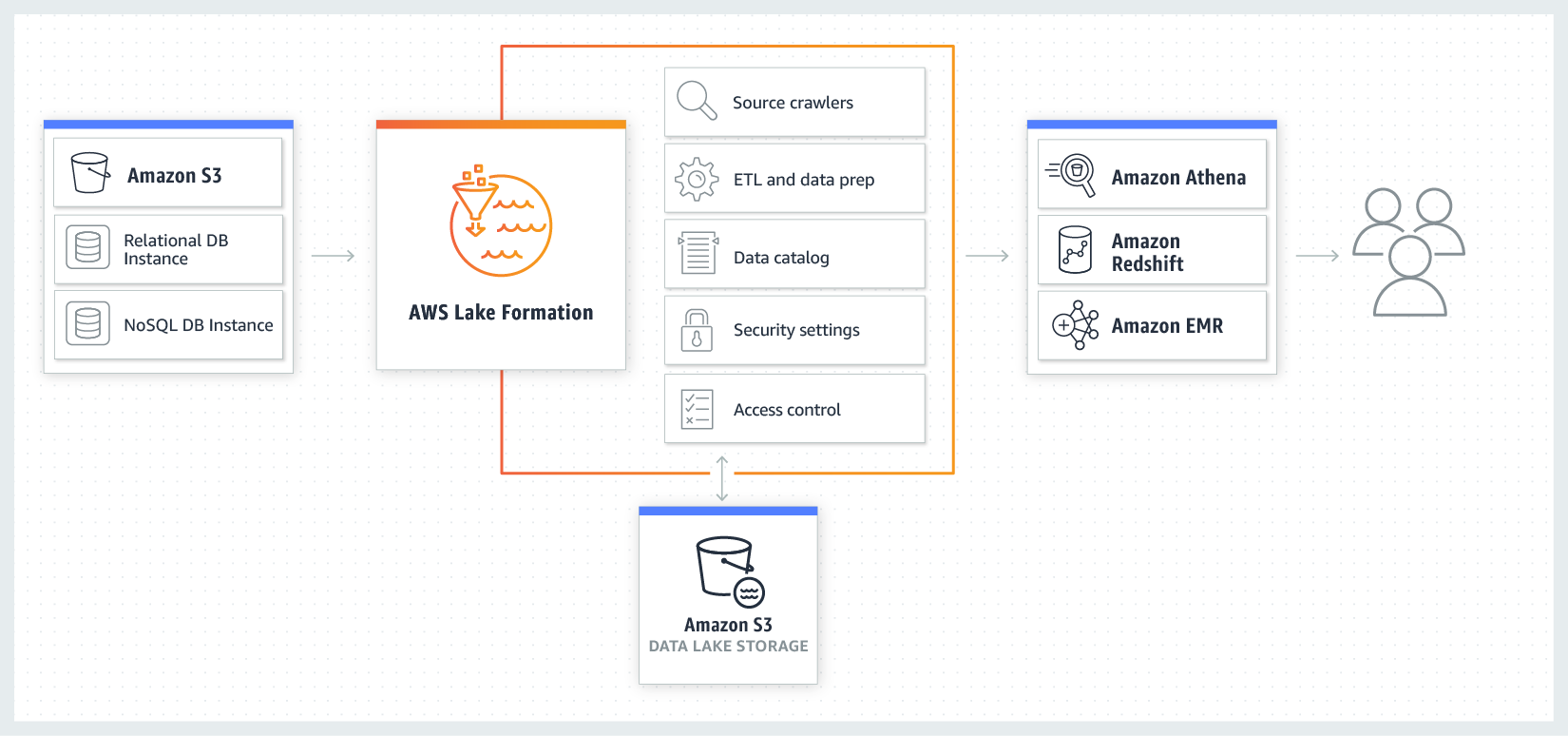
4 AWS Data Lake Best Practices
Use the following best practices to make the most of your S3 data lake.
1. Store Data in the Raw Format
Configure your data lake to store all raw data in the original format before transforming, cleaning, or processing the data. Storing data in raw formats allows data scientists and analysts to use the data in various ways, make novel queries, and create new enterprise data use cases.
Amazon S3 offers cost-effective and scalable on-demand scalability data storage, allowing you to retain your organization’s data in the cloud for a long time. The data you capture and store today may be useful in several months or years when addressing new problems or asking new questions.
Storing all data in the source format ensures that no details get lost. The AWS data lake thus becomes your single source of truth for all ingested raw data.
2. Optimize Costs with Storage Classes
Amazon S3 offers several cloud storage classes to help you optimize costs for specific data use cases based on the expected frequency of access. For example, you may choose the Amazon S3 Standard class for a data ingestion bucket where you send raw data from on-premise and cloud applications. On the other hand, you can use cheaper options to store less frequently accessed data.
Leverage S3 Intelligent Tiering to reduce costs by automatically switching between different storage tiers based on frequent or infrequent access requirements or archiving use cases. This option best stores processed data with changing or unpredictable access requirements.
The most cost-effective storage option is Amazon S3 Glacier, which provides a deep archive to store historical data and reduce the cost of retaining data for auditing and compliance purposes.
3. Govern Data Storage with Lifecycle Policies
A data lifecycle policy allows DevOps teams to manage data flows in the data lake throughout the lifecycle of a data asset. For example, a data lifecycle policy might determine what happens to an object entering S3. Other policies might specify when to transfer data to a more cost-effective storage class, such as an archive or delete objects that are no longer useful.
While Intelligent Tiering helps triage the objects in the AWS data lake to optimal storage classes, it is a service based on pre-configured policies which might not meet your specific business requirements. S3 data lifecycle management lets you create and apply customized lifecycle configurations to groups of objects, allowing you to control data transfer, storage, and deletion.
4. Leverage Object Tags
Amazon S3 allows you to easily tag objects to categorize and mark your data. An object tag contains a key-value pair—the key has up to 128 characters and the value up to 256 characters. Typically, the key defines the object’s specific attribute while the value component assigns the attribute’s value.
You can assign up to 10 tags to each object in an AWS data lake (each tag must be unique). Multiple objects can share a tag. There are many reasons to tag objects in S3. Object tagging lets you replicate data across multiple regions, locate and analyze all objects that share a given tag, implement data lifecycle policies to objects that share a tag, or give users access permissions to specific groups of objects in the data lake.
Related Articles: Data Warehouse vs Data Lake and Data Lakehouse.