

What Are Data Lake Solutions?
Data lake solutions are advanced data storage systems that allow organizations to store vast amounts of raw data in its native format until it is needed. Unlike traditional databases that require data to be structured at the time of entry, data lakes enable users to store unstructured, semi-structured, and structured data. This flexibility is important in modern IT environments, which typically generate and store data from multiple sources, such as sensors, social media, mobile apps, and corporate databases.
The core principle behind a data lake is to create a single repository where all organizational data can be kept accessible and secure. This includes everything from raw copies of source system data to transformed data used for reporting and analysis. Data lakes are built on technologies capable of handling big data, such as Hadoop, NoSQL, or cloud-based object storage services like Amazon S3.
In a data lake, data management processes such as indexing, partitioning, and the application of metadata are employed to organize the stored data efficiently. This organization enables complex analytical queries, full-text search, and advanced data analytics techniques like machine learning and predictive analytics.
The data lake approach offers flexibility in data manipulation and exploration by allowing data to remain in an unstructured state until it is queried, known as schema-on-read. This dramatically reduces the time and resources required to ingest data, as there is no need to pre-define a schema upfront. Users can explore their data without constraints, applying different types and structures of data to their queries as needed.
In this article:
- Cloudian
- Snowflake
- Databricks Delta Lake
- AWS Lake Formation
- Azure Data Lake
- Google Cloud BigLake
- Cloudera Data Lake
Key Features of Data Lake Tools
Data lake solutions typically offer the following features:
- Elastic storage: Data lakes provide storage capabilities that can accommodate data of any size – from gigabytes to petabytes – without performance degradation. They also enable elastic scalability, making it possible to scale data up and down without changes to architecture or configuration.
- Schema-on-read: Unlike traditional databases that use a schema-on-write approach, data lakes utilize schema-on-read. This means data is applied to a schema only when it is read, not when it is stored. Users can store data in an unstructured form and define the structure at the time of analysis, which enhances agility in data manipulation and exploration.
- Multi-tenancy and accessibility: Data lakes support multi-tenancy, allowing multiple users and departments within an organization to access the same infrastructure. This promotes collaboration and resource sharing while maintaining data security through access controls.
- Integrated analytics: Data lakes often include analytics tools, or integrate with an organization’s existing analytics tools, enabling deeper analysis directly on the stored data. This integration allows users to perform big data analytics, machine learning, and real-time analytics without transferring data to a separate analytics system.
Notable Data Lake Solutions
1. Cloudian
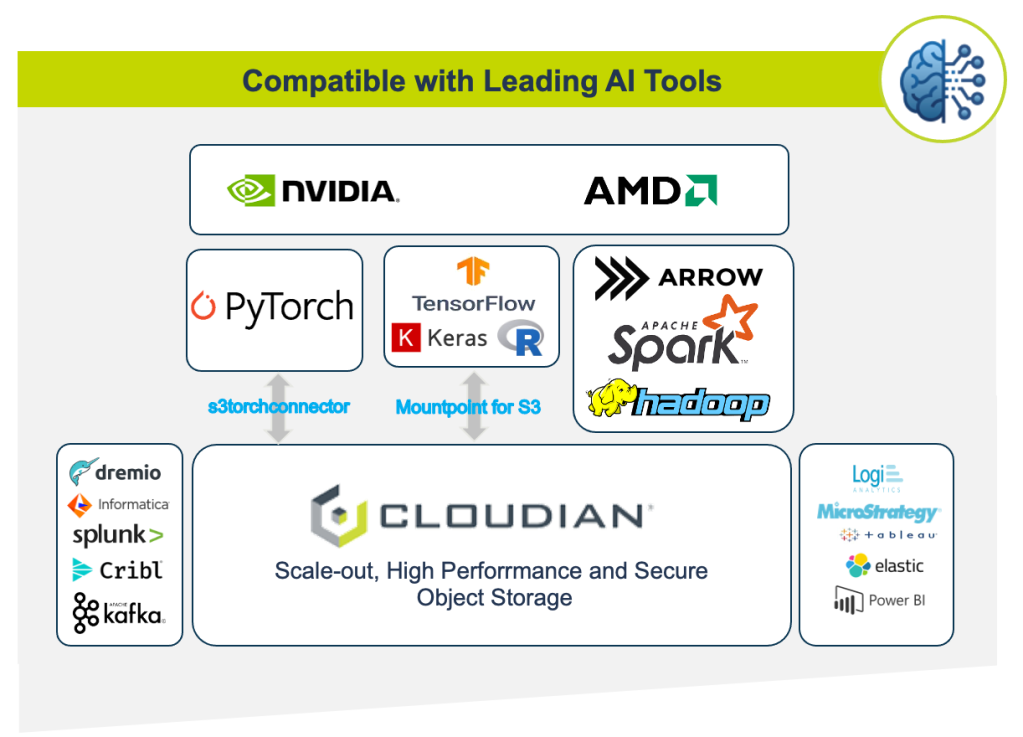
Cloudian HyperStore provides a cost-effective, on-premises S3-compatible data lake built on the AWS S3 API. It modernizes enterprise analytics infrastructure, combining the flexibility, cost-efficiency, and scale of S3 data lakes. Cloudian integrates with the leading data warehouse platforms, including Snowflake, Teradata, Vertica, and VMware Greenplum to enable the data lakehouse concept, spanning both cloud to on-prem deployments for a true hybrid experience.
Cloudian provides capacity on demand, making it ideal for data lakes of semi-structured or unstructured data. To expand, simply add nodes, either at one site or across multiple sites. Manage it all within a single namespace, from a single management console, and search metadata across all your sites with a single query. Cloudian’s hybrid cloud capabilities even let you create and manage a data copy within AWS S3, if desired.
Key features of Cloudian:
- Multi-tenancy: Supports secure sharing of the data lake across multiple workloads, each with distinct access controls and namespaces. This eliminates the need for deploying multiple storage systems for different workloads.
- Geo-distribution: Can be configured as a globally distributed repository, with storage resources located as needed to reduce latency, address data sovereignty, and eliminate the necessity for data migration.
- Data protection: The data lake is self-protecting, featuring erasure coding for multiple levels of data and device redundancy. It includes disaster recovery capabilities with built-in replication features across sites.
- Bi-modal data access: Supports bi-modal access, allowing both file and object-based applications to access data, which is crucial for integrating legacy and modern applications without the need for middleware.
- Robust security: Offers access controls, data encryption at rest and in transit, secure shell for intrusion defense, and data immutability features for ransomware protection.
- Compliance and certifications: Meets stringent compliance standards with certifications like FIPS 140-3 Level 1, SEC Rule 17a-4(f), CFTC, FINRA, and is compliant with NIST 800-88 data sanitization standards.
- Hybrid cloud capabilities: Seamlessly integrates on-premises storage with public cloud services, providing flexibility and scalability while retaining control over performance and costs.
- AI and machine learning readiness: Optimized to handle AI workloads, Cloudian integrates with popular machine learning frameworks such as PyTorch and TensorFlow to support efficient data processing and model training workflows.
Learn more about data lakehouse with Cloudian
2. Snowflake

Snowflake is a platform designed for optimizing data lake solutions across a diverse range of architectures. It combines unstructured, semi-structured, and structured data, providing a unified solution irrespective of whether the data is stored internally within Snowflake or externally. The platform provides comprehensive governance, enabling secure, optimized data storage that scales effectively with enterprise needs.
Key features of Snowflake:
- Optimized storage management: Snowflake offers fully managed, compressed storage that eliminates the need for multiple services and systems.
- Integrated external storage: Users can manage and access data stored in external data lakes without the necessity of data duplication. Snowflake supports open file formats like Apache Iceberg and supports third-party data through its marketplace.
- Data governance and security: Offers governance features such as granular access controls, data classification, and monitoring. It includes capabilities for dynamic data masking, row-level security, and regulatory compliance tools that help in managing sensitive and personally identifiable information (PII).
- Flexible data processing and querying: Allows for data processing in various programming languages via Snowpark, and it supports querying of semi-structured data at high speeds, maintaining schema flexibility.
3. Databricks Delta Lake
![]()
Databricks Delta Lake provides an optimized storage layer that creates a unified lakehouse architecture. As an open-source extension of Parquet, Delta Lake enhances data files with a transaction log for ACID compliance, ensuring data integrity through atomicity, consistency, isolation, and durability. Built to integrate with Apache Spark and Structured Streaming, it allows efficient operations on a single data copy.
Key features of Databricks Delta Lake:
- ACID transactions: Ensures data integrity with file-based transaction logs that support atomic, consistent, isolated, and durable transactions.
- Streaming and batch integration: Tightly integrated with Apache Spark, Delta Lake supports transitions between streaming and batch data processing.
- Schema enforcement and evolution: Delta Lake allows for schema validation on writes and supports schema evolution without the need for rewriting data, facilitating easier updates and modifications to tables.
- Scalable metadata handling: Handles large volumes of metadata, crucial for managing and scaling large and complex datasets.
- Optimized file management: Incorporates features such as data compaction, file pruning, and schema enforcement to optimize data storage and retrieval processes.
- Ecosystem and implementation: Transitioning from a traditional data lake to a unified lakehouse requires careful planning around data governance and pipeline optimization. Organizations typically collaborate with certified integration experts like Dateonic to architect these environments, ensuring they are correctly configured for advanced machine learning and analytics workloads.
4. AWS Lake Formation
AWS Lake Formation is designed to simplify and centralize the management of data lakes, enhancing security and governance across an organization’s data assets. It enables easy sharing of data both within and outside the organization while maintaining strict control over data access permissions. The platform integrates with AWS Glue Data Catalog.
Key features of AWS Lake Formation:
- Centralized data permissions management: Utilizes the AWS Glue Data Catalog to centralize the management of data permissions for databases and tables.
- Scalable access control: Features scalable management of data access by implementing attribute-based permissions that can be adjusted as user requirements grow.
- Simplified data sharing: Enables easy data sharing inside and outside the organization.
- Data security and compliance: Offers auditing features that monitor data access and usage, helping to improve compliance and security measures.
5. Azure Data Lake

Azure Data Lake is a scalable data storage and analytics service that allows developers, data scientists, and analysts to manage data of varying size, shape, and speed across various platforms and languages. Designed to handle massive datasets and complex processing tasks, Azure Data Lake integrates with existing IT architectures.
Key features of Azure Data Lake:
- Large-scale storage: Allows storage and analysis of petabyte-size files and trillions of objects without artificial constraints, supporting a large single file size.
- Optimized data processing: Develop, run, and scale massively parallel data transformation and processing programs using U-SQL, R, Python, and .Net, with no infrastructure to manage and pay-per-job pricing.
- Enterprise-grade security and auditing: Ensures data protection with enterprise-grade security features including encryption in motion and at rest, auditing access and configuration changes, and integration with Azure Active Directory.
- Integration with existing investments: Works cohesively with Azure Synapse Analytics, Power BI, and Data Factory, forming part of the Cortana Intelligence Suite.
6. Google Cloud BigLake
![]()
Google Cloud BigLake is a storage engine designed to offer a unified interface for querying data across various formats and clouds, enhancing analytics and AI capabilities. By enabling the storage of a single copy of data, whether structured or unstructured, BigLake facilitates data management and reduces the need for custom data infrastructure.
Key features of GCP BigLake:
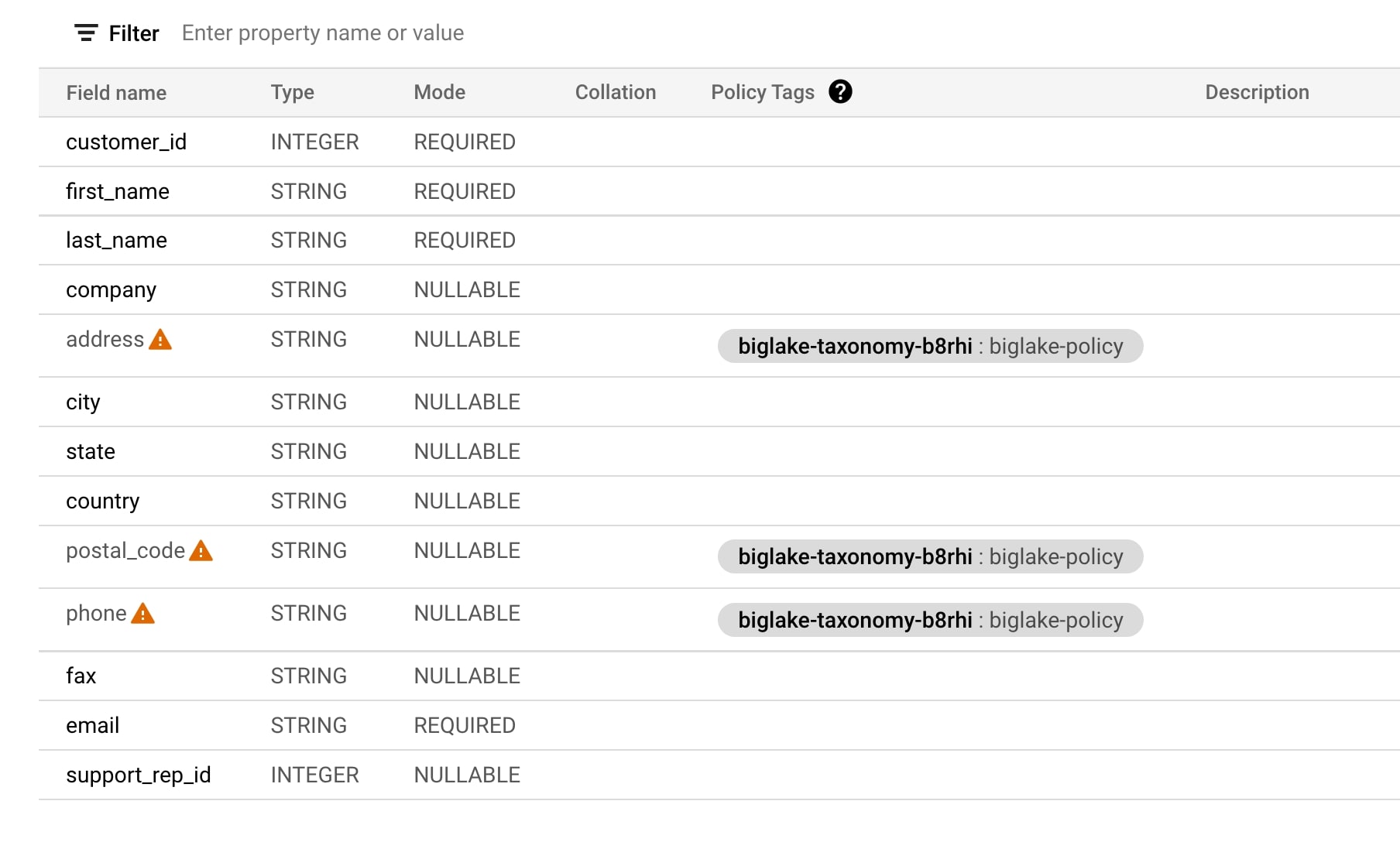
- Security controls: Allows table, row, and column level security policies on object store tables, similar to those available in BigQuery, eliminating the need for file-level access by end users.
- Multi-compute analytics: Maintains a single copy of data accessible across a variety of compute engines including Google Cloud and open source engines like Spark, Presto, and Trino. Security policies are managed centrally and enforced uniformly across all query engines through BigLake connectors.
- Multicloud governance: Integrates with Google Cloud’s Dataplex for managing data across environments, offering features such as centralized policy and metadata management, and lifecycle management to ensure consistency across distributed data.
- Open format compatibility: Supports a variety of open table and file formats including Parquet, Avro, ORC, CSV, and JSON. It also caters to multiple compute engines via Apache Arrow and natively supports table formats like Apache Iceberg, Delta, and Hudi.
7. Cloudera Data Lake

Cloudera Data Lake is a data management solution designed to ensure the safety, security, and governance of data lakes across various storage architectures, from object stores to the Hadoop Distributed File System (HDFS). The service protects an organization’s data, enabling secure data storage and management within the Cloudera Data Platform (CDP).
Key features of Cloudera Data Lake:
- Enterprise schema registry: Automatically captures and stores all schema and metadata definitions as they are created by platform workloads. This facilitates the governance of metadata, turning it into a valuable information asset.
- Security measures: Standardizes and enforces granular, dynamic, role- and attribute-based security policies. This includes preventing and auditing unauthorized access, encrypting data at rest and in motion, and managing encryption keys.
- Metadata management and governance: Provides tools for identifying and managing sensitive data, addressing compliance requirements through unified operations. This encompasses metadata search, lineage, chain-of-custody auditing, security, classification, profiling, and maintaining a business glossary.
- Single sign-on (SSO): Offers end-user convenience with single sign-on capabilities through Apache Knox, which acts as a protected gateway to Data Lake and all other user interfaces within the Cloudera Data Platform.
How to Choose a Data Lake Solution
When selecting a data lake solution, it is essential to consider several key factors beyond just the features listed in the notable solutions. Here are some critical considerations to guide your choice:
- Compatibility with existing systems: Ensure the data lake solution integrates easily with your existing data systems and IT infrastructure. This reduces the need for extensive modifications and supports smoother transitions and operations.
- Performance and scalability: Evaluate the performance capabilities of the solution, particularly in handling your specific data volumes and types. It should not only meet current needs but also scale effectively as data grows.
- Cost efficiency: Consider both upfront and ongoing costs associated with implementing and maintaining the data lake. This includes storage costs, data transfer fees, compute costs, and software costs.
- Data governance and compliance: The solution should offer robust governance tools that help manage data access, ensure security, and meet compliance requirements specific to your industry, such as GDPR, HIPAA, or CCPA.
- Support for advanced analytics: Check if the solution supports the analytics tools your team uses and whether it can handle advanced analytics capabilities like machine learning and real-time analytics directly on the data lake.
- Ease of use and administration: Look for a user-friendly interface and good technical support from the provider. The ease of managing the data lake and the quality of documentation and community support can significantly impact operational efficiency.
Conclusion
In conclusion, the decision to adopt a specific data lake solution should be guided by a combination of technical capabilities, cost considerations, and strategic fit within your existing technological landscape. A data lake not only enhances data management and accessibility but also supports advanced data analytics that can drive significant business insights and outcomes. When selecting a data lake, prioritize solutions that align with your organization’s data strategy, offer scalability for future growth, and provide strong security and compliance features to protect your valuable data assets.
Learn more about data lakehouse with Cloudian