




Request a Demo
Join a 30 minute demo with a Cloudian expert.


Cloudian S3-compatible object storage offers a fast, secure, cost-effective backup target for your data protection solution:
The most security certifications of any on-prem object storage.
S3 Object Lock provides government-certified data immutability.
Modular scalability without disruption.
Achieve your RPO/RTO targets with fast on-prem backup and restore.
Save up to 70% over public cloud or traditional storage.
With the most advanced S3 compatibility of any independent object storage, you can store data from almost any backup provider with Cloudian.




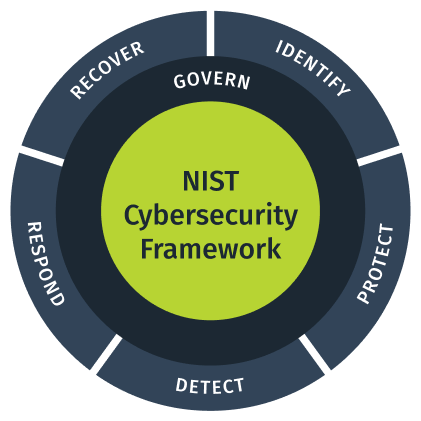
Cloudian HyperStore enhances cybersecurity for unstructured data storage by aligning with the NIST Cybersecurity Framework. It addresses sophisticated cyber threats through the framework’s core functions: Identify, Protect, Detect, Respond, Recover, and Govern.
The solution offers advanced monitoring, immutable storage with S3 Object Lock, automated threat detection, and rapid response mechanisms. With robust governance and compliance features, HyperStore provides enterprises with a proactive, multi-layered defense against evolving threats, reinforcing its leadership in secure storage solutions.

Why Go Direct-to-Cloudian

Simplify Backup, Lower Cost & Boost Ransomware Protection with Veeam v12 & Cloudian

Cloudian S3 Object Lock makes your data unchangeable so it cannot be encrypted by ransomware. HyperStore is also hardened with HyperStore Shell (HSH) and RootDisable, which secure the solution at the system level, disabling root access to make the solution impregnable.
Integrated with data protection from Veeam or Commvault, the combination gives you the only on-prem ransomware solution that is tamperproof down to the system level with data immutability that’s SEC17a-4 certified.
Enterprises are increasingly deploying Kubernetes-managed, containerized applications in full production, making it essential to protect these applications and their data. Through the new integration of Cloudian HyperStore with Kasten by Veeam, organizations can now have the same secure, scalable, enterprise-grade backup for their containerized apps as they already rely on for their traditional workloads.
As a Kasten backup target, HyperStore provides modern, cloud-native storage with complete S3 compatibility, limitless scalability, and ransomware protection—on-premises for superior RPO/RTO or in a hybrid cloud—all at up to 70% less cost than traditional or public cloud storage.


Microsoft Office 365 offers geo-redundancy, which protects your data from site or device failure. But it does not replace backup. With geo-redundancy alone, you have limited recovery options if your data is accidentally deleted or maliciously attacked.
Protect your Office 365 data with Cloudian HyperStore and Veeam VBO v4. Veeam’s native support for the S3 API ensures seamless integration and trouble-free operation.
Solution Brief
Protect your application data on VMware vSAN with Cloudian HyperStore providing a fast, on-premises, scalable backup target and ease of management.
The inability to access data, management complexity, lack of real-time data visibility, and increasing overall costs involved in maintaining and expanding aging tape libraries are prompting many businesses to explore other options.
This insider’s guide touches upon various aspects of modernizing your data center, starting with moving away from legacy, tape-based storage to other ransomware-safe alternatives like on-prem cloud storage, and the considerations and steps involved in such a move.

60% or more of data on Tier 1 storage is either dormant or rarely used.
Object storage can dramatically reduce Tier 1 storage costs with zero impact on user data access.
Cloudian HyperStore is a truly distributed storage platform that offers customers unmatched data resiliency (up to 14 9s) with the use of flexible replication factor and/or erasure coding data protection schemes.
Deployments can be distributed across multiple cross-region data centers and multiple public and private clouds, which makes the solution ideal for disaster recovery.
Go Hybrid Cloud
Cloudian HyperStore works much like (and with) Amazon Outpost, for much less cost.
Disaster Recovery
Replicate to Cloudian at a remote site or to any public cloud.
1 On-premises Backup Target
Back up data to an on-prem Cloudian storage cluster for fast RPO/RTO. Your data remains with your data center, behind your firewall. For DR purposes, you can also replicate the data to a second Cloudian cluster at a remote site using the integrated data management tools. There is no additional software to license or manage.
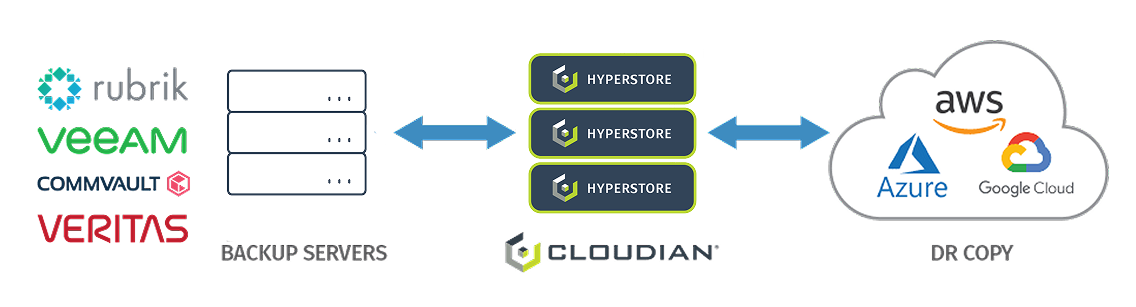
2 Hybrid Cloud
In a hybrid cloud configuration, you can back up data to a local Cloudian cluster, then use integrated tools to replicate that data to the cloud for DR purposes. This combines the immediate access of local storage with the off-site convenience of cloud. You get fast RPO/RTO without the cost and risk of relying on WAN connectivity for restore.
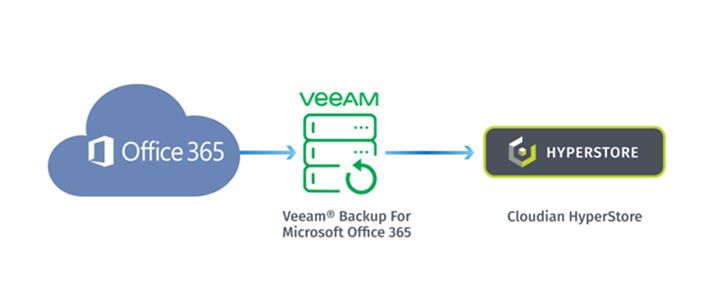
Microsoft Office 365 offers geo-redundancy, which protects your data from site or device failure. But it does not replace backup. With geo-redundancy alone, you have limited recovery options if your data is accidentally deleted or maliciously attacked.
Veeam Backup for Microsoft Office 365 (VBO) paired with Cloudian HyperStore provides a cost-effective solution to protect your Office 365 data from accidental deletion, rogue employees, and malware. From VBO, Office 365 backups are stored directly to Cloudian, providing a fast, on-premises disk-based data protection solution.
SOLUTION BENEFITS INCLUDE:

WHITEPAPER
Cloudian HyperStore Multi-Cloud Technical Guide
Learn how Cloudian HyperStore® can help overcome the challenges of moving to public and multi-cloud environments.
Learn More
EBOOK
The Object Storage Buyer’s Guide
This comprehensive eBook details how hyperscale object storage can help you reap the maximum ROI from your storage investment.
Learn More
DEMO
AWS Local Zones and Cloudian HyperStore
This comprehensive eBook details how hyperscale object storage can help you reap the maximum ROI from your storage investment.
Learn More
WEBINAR
Ransomware and Cyber Insurance: A C-Suite Convo
This comprehensive eBook details how hyperscale object storage can help you reap the maximum ROI from your storage investment.
Learn More
CASE STUDY
Leading Swiss Financial Institution to Retain and Analyze More Big Data
This comprehensive eBook details how hyperscale object storage can help you reap the maximum ROI from your storage investment.
Learn More