

Building and Protecting Data Lakehouse Projects with Cloudian and Vertica
Over the past year, Cloudian has greatly expanded its support for data analytics through new partnerships. One of those key partnerships is with Vertica, where the combination of Vertica and Cloudian HyperStore enables organizations to build and protect data lakehouses for modern data analytics applications.
This blog highlights the three main use cases we’re currently serving together:
- Starting a data lakehouse with Vertica in Eon mode and Cloudian
- Extending the data lakehouse with Vertica external tables and Cloudian
- Protecting Vertica datasets with data backup to Cloudian
Just as a reminder, Vertica is a unified analytics data warehouse platform, based on a massively scalable architecture, and Cloudian is a software-defined, limitlessly scalable, S3-compatible object storage platform for on-premises and hybrid cloud environments.
Starting a Data Lakehouse with Vertica in Eon Mode and Cloudian
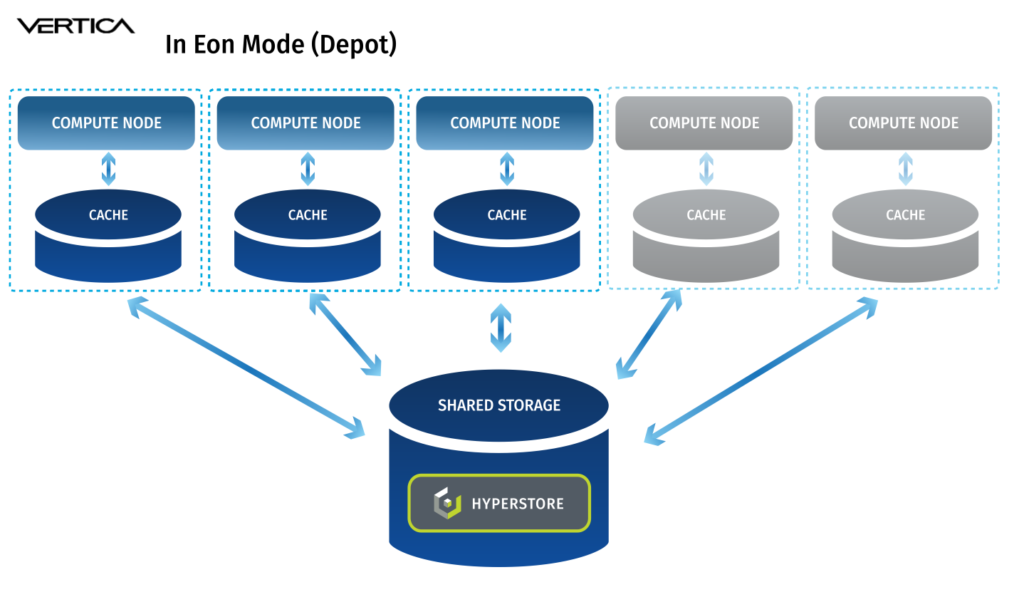 In the data analytics space, Vertica is known for performance, whether it is run in “Enterprise Mode” or “Eon Mode.” In Enterprise Mode each database node stores a portion of the dataset and performs a portion of the computation. In Eon Mode, Vertica brings its cloud architecture to on-premises deployments and decouples compute and storage. In Eon Mode, each Vertica node can access a shared communal storage space via S3 API. The advantages are: a) compute can be scaled as required without having to scale storage, meaning no more server sprawl and b) storage can be consolidated into a single platform and accessed by various data tools:
In the data analytics space, Vertica is known for performance, whether it is run in “Enterprise Mode” or “Eon Mode.” In Enterprise Mode each database node stores a portion of the dataset and performs a portion of the computation. In Eon Mode, Vertica brings its cloud architecture to on-premises deployments and decouples compute and storage. In Eon Mode, each Vertica node can access a shared communal storage space via S3 API. The advantages are: a) compute can be scaled as required without having to scale storage, meaning no more server sprawl and b) storage can be consolidated into a single platform and accessed by various data tools:
Building out Vertica communal storage on Cloudian is easy. For this exercise we are going to assume we have both a functional Vertica and Cloudian HyperStore instance that can communicate via HTTP(s):
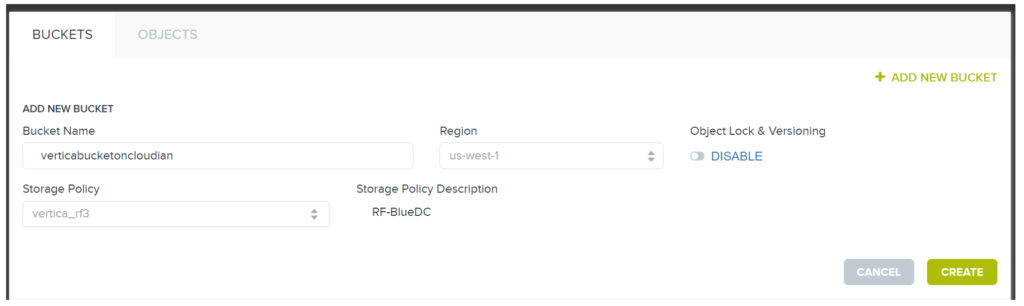
- Configure a bucket via Cloudian Management Console (CMC) on your HyperStore cluster:
-
- Let’s use the name
“verticabucketoncloudian”for this example.
- Let’s use the name
-
- Create an
auth_params.conffile:- On your Vertica node, create an
auth_params.conffile that will be accessible when you create the Vertica database instance.
auth_params.confvalues required are going to be:
awsauth = Access_Key:Secret_Key
awsendpoint = HyperstoreAddress:Port (either 443 or 80)
awsenablehttps = 0 Is required if not using HTTPs
- On your Vertica node, create an
- Create your Vertica in Eon Mode database instance:
- On your Vertica node, create the database instance. Specify the location of your
auth_params.conffile to leverage a Cloudian S3 bucket for communal storage.
admintools -t create_db -x auth_params.conf \
--communal-storage-location=s3://verticabucketoncloudian \
--depot-path=/home/dbadmin/depot --shard-count=6 \
-s vnode01,vnode02,vnode03,vnode04,vnode05,vnode06 -d verticadb -p 'YourDBAdminPasswordHere'
- On your Vertica node, create the database instance. Specify the location of your
- Success! Let’s test.
- Once the above command returns successfully, you can test the Vertica in Eon Mode instance.
- Connect to your db instance and load a dataset.
- Connect to Cloudian bucket
“verticabucketoncloudian”via CMC or S3 browser, and you will see objects in the bucket.
Extending the Data Lakehouse with Vertica External Tables and Cloudian
One of the key tenants of a successful data lakehouse initiative is the ability to access and analyze datasets that have been generated by other analytics platforms.
Prior to the data lakehouse, an ETL (Extract Transform Load) operation would have been required to move data from one analytics platform to another. Today, Vertica can analyze the data in-place by leveraging external tables, without the need for complex and expensive data moves.
 Let’s consider the following scenario… we have an ORC dataset, which was generated by an Apache Hive instance, stored on Cloudian, and we need to connect to it with Vertica. To analyze this dataset in-place, use the following Vertica syntax to connect to the ORC dataset:
Let’s consider the following scenario… we have an ORC dataset, which was generated by an Apache Hive instance, stored on Cloudian, and we need to connect to it with Vertica. To analyze this dataset in-place, use the following Vertica syntax to connect to the ORC dataset:

That is much simpler and easier than working through any data ETL.
Here are the details for the S3 parameters and configuration.
Protecting Vertica Datasets with Data Backup to Cloudian
As with all datasets, backups of data are key to protecting and preserving data. For this purpose, Vertica has its own backup and recovery tool called “vbr,” and Vertica can leverage Cloudian as a backup target.
Vertica has thoroughly documented the process, but here’s a condensed version:
- Configure connectivity and credentials for HyperStore
- HyperStore credentials are important. They are configured within the database, as a security function, and they are configured as environmental variables to allow vbr to connect.
- For the database that is going to be backed up, set the
AWSAuthcredentials (S3 credentials):
ALTER DATABASE DEFAULT SET AWSAuth = 'accesskeyid:secretaccesskey';
- For the database that is going to be backed up, set the
- Configure vbr HyperStore URL address and credentials
export VBR_COMMUNAL_STORAGE_ENDPOINT_URL=http://
export VBR_COMMUNAL_STORAGE_ACCESS_KEY_ID=
export VBR_COMMUNAL_STORAGE_SECRET_ACCESS_KEY=
export VBR_BACKUP_STORAGE_ENDPOINT_URL=http://
export VBR_BACKUP_STORAGE_ACCESS_KEY_ID=
export VBR_BACKUP_STORAGE_SECRET_ACCESS_KEY=
- Keep in mind that you can back up to the same endpoint using the same credentials as the communal storage, but to a different bucket. Or backup can be to a second endpoint with different credentials. Most users will want to back up to a different bucket to reduce associated cost.
- HyperStore credentials are important. They are configured within the database, as a security function, and they are configured as environmental variables to allow vbr to connect.
- Setting the configuration file for vbr
- There are some additional parameters that must be stored in a configuration file for Vertica to successfully backup / restore with Cloudian
- Create a file called
“eon_backup_restore.ini’in the home directory ofdbadmin
As a quick reference,/opt/vertica/share/vbr/example_configscontains examples for cloud backups
eon_backup_restore.ini
[CloudStorage]
cloud_storage_backup_path = s3://verticabackuponcloudian/fullbackup/
cloud_storage_backup_file_system_path = []:/home/dbadmin/backup_locks_dir/
cloud_storage_concurrency_backup = 10
cloud_storage_concurrency_restore = 10
[Misc]
snapshotName = EONbackup_snapshot
tempDir = /tmp/vbr
restorePointLimit = 1
[Database]
dbName =
dbPromptForPassword = True
dbUser = dbadmin
- Target initialization and performing data backup
- Vertica requires the S3 bucket to be initialized prior to use
vbr -t backup -c eon_backup_restore.ini
Initializing backup locations.
Backup locations initialized.
- Run the Vertica backup
vbr -t backup -c eon_backup_restore.ini
Enter vertica password:
Starting backup of database VMart.
Participating nodes: v_vmart_node0001, …., v_vmart_node0006.
Snapshotting database.
Snapshot complete.
Approximate bytes to copy: x of y total.
[================================================] 100%
Copying backup metadata.
Finalizing backup.
Backup complete!
- Vertica requires the S3 bucket to be initialized prior to use
I hope this tech blog post helps make your Cloudian and Vertica data lakehouse project a success.
For more information about Cloudian data lakehouse / data analytics solutions, go to S3 Data Lakehouse for Modern Data Analytics.

Henry Golas, Director of Technology, Cloudian