

Cloudifying Enterprise Data Analytics with VMware Tanzu Greenplum and Cloudian Object Storage
Enterprise data analytics architectures based on traditional data warehouse platforms–running on appliances and/or traditional storage infrastructure solutions–cannot keep up with the scale, speed, or efficiency required by dynamic enterprises. They can also get expensive very quickly. To gain a competitive advantage, customers are increasingly looking to the cloud model where data warehouse platforms connect directly to and analyze data sitting in an S3 data lake. This cleaner, simpler model makes business data analytics more nimble, providing greater scalability, flexibility, and cost reduction. This modern analytics architecture is termed the Data Lakehouse.
VMware Tanzu Greenplum, a massively parallel processing (MPP) data warehouse platform, seamlessly integrates with Cloudian HyperStore S3-compatible object storage to provide enterprise customers the same Data Lakehouse architectures on-premises. In this blog, we will detail how to cloudify your on-prem analytics architecture with Greenplum connecting to Cloudian HyperStore for use cases ranging from analytics and federated queries to data protection of your Greenplum environment.
The Platform Extension Framework (PXF)
Greenplum integrates into S3-compatible storage platforms like HyperStore using its Platform Extension Framework (PXF). PXF is a Greenplum database extension providing users the capability to perform parallel, high-performance data access and federated queries on related datasets stored on storage external (S3-compatible buckets, in this case) from the main Greenplum server nodes. Since these queries can be done in place, this method is a lot more efficient and less resource intensive than doing a full load of the datasets into the database.
Cloudian Hyperstore Object Storage, a distributed solution designed to ingest, store, and address massive amounts of data, is the ideal platform for the Data Lakehouse solution and a VMware-certified technology to work with Greenplum. In addition, Cloudian Hyperstore is deployed on-prem rather than in the cloud, which means the data lake is adjacent to the Greenplum cluster and directly connected via high-speed bandwidth network, so network latency and bandwidth issues are eliminated as performance bottlenecks in this solution. And since Cloudian Hyperstore is a fraction of the cost of traditional legacy systems, it becomes not only the best solution operationally but also financially, since it will generate considerable savings and cost optimization for the entire solution.
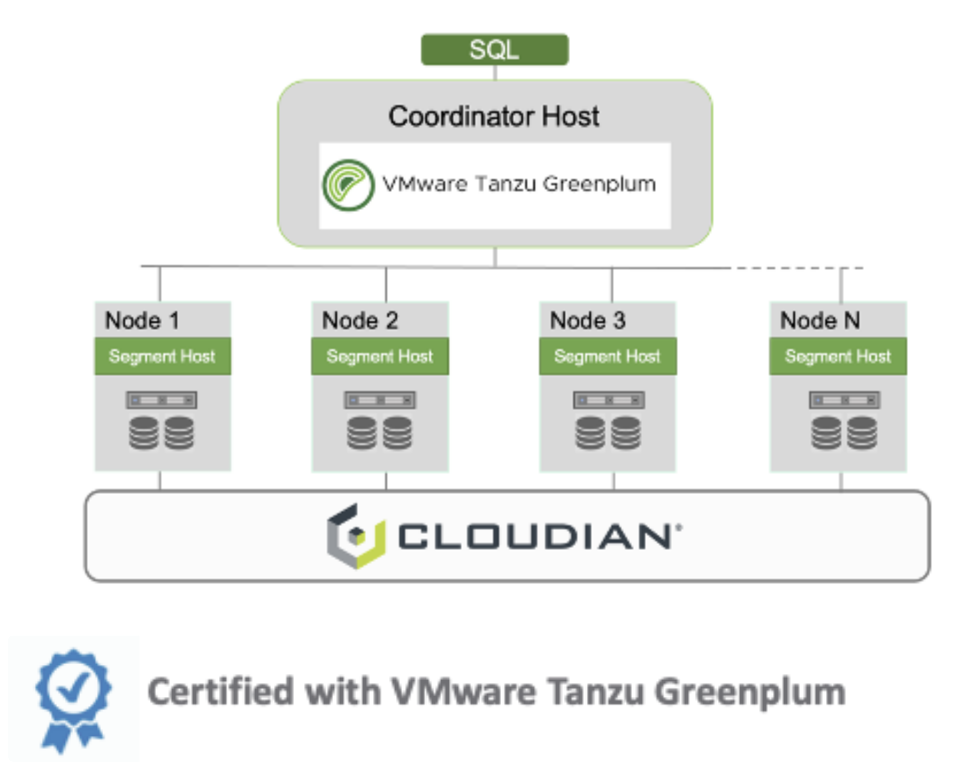
Connecting Greenplum to Cloudian HyperStore
To execute any of the use cases, we must first connect Greenplum to HyperStore. To do this, configure the cloudian-site.xml file in the PXF, with the s3 customer endpoint URL, access key, and secret key, and store the file in $PXF_HOME/servers/cloudian.

Once connected, the solution can be used for several high-value use cases.
Connecting Greenplum to Cloudian HyperStore
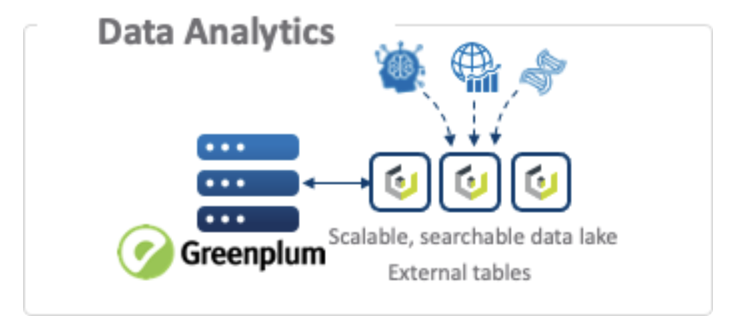
The most compelling use case for this solution is the ability to run high-performance analytics directly on data residing in the S3 data lake (Cloudian HyperStore). In this case, data is ingested from various data sources directly into one or more S3-compatible buckets. Here is how you would create external tables and insert data for analyses.
Create WRITABLE EXTERNAL TABLE “pxf_ext_tbl_cloudian_w” linked to cloudian:
- “SERVER” needs to point to the server name under the folder of $PXF_HOME/servers/
- “greenplum” is bucket name; “cloudian_test” is folder name.
- >”file1.txt” is the file which I assumed to be a text file, but in the end, it is a subfolder of “cloudian_test”

Insert data into the “pxf_ext_tbl_cloudian_w” table.

Create EXTERNAL TABLE “pxf_ext_tbl_cloudian_r” linked to cloudian, same destination.

Greenplum, using PXF, can now perform massively parallel, high-performance access and querying of that data to return the desired insights.
You can query the data from the “pxf_ext_tbl_cloudian_r” table.

The results of those queries can also be stored on S3 buckets for others to access and consume. As this access and querying takes place over high-performance networks, network bandwidth and latency have no impact on the performance of the overall solution.
Data Protection and Disaster Recovery
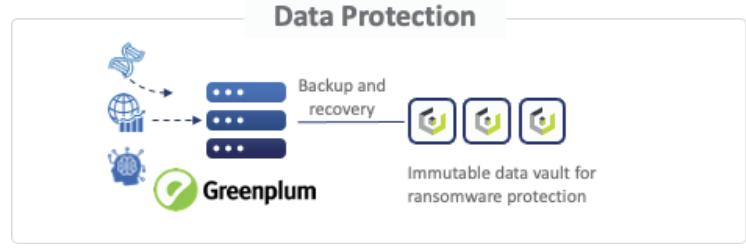
And last but not least, organizations need to protect their data against accidental data loss, corruption, ransomware, or even an entire data center failure. Greenplum offers backup and restore utilities which can leverage the Cloudian Object Store as the repository for those backups and instant access for quick recoveries. Because of the distributed nature of both the Greenplum and Cloudian Hyperstore architectures, these backup and restore processes can be run with multiple parallel threads for greater performance and efficiency and thus provide better RPO and RTO for operational recoveries.
In addition, with these functionalities combined with the capability for Cloudian Hyperstore to replicate data between data centers, organizations can now feel reassured that they will be able to quickly recover data at an alternate location in case of a disaster at the primary data center and be able to return to business as usual promptly.
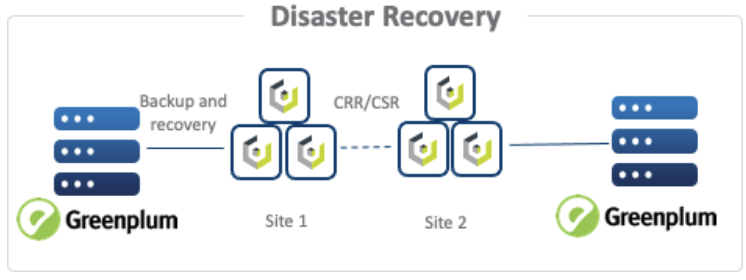
This is just another example of how the Cloudian and Greenplum technologies can integrate seamlessly together to provide customers with a superior advanced analytics platform, but also protect their data with a best-in-breed disaster recovery and business continuity solution for their data lakehouse.
To learn more about harnessing the value of Hyper Performance Analytics at scale with VMware Tanzu Greenplum and Cloudian Hyperstore, visit cloudian.com/greenplum or register here to see a demo of the solution in action on July 21st.