

Data (or cloud) repatriation is the process of moving data, applications, and workloads from public cloud providers back to on‑premises data centers, private clouds, or alternative hosting environments. Organizations pursue repatriation to improve cost efficiency, gain tighter security and sovereignty, and better align infrastructure with long‑term business and regulatory requirements.
In practical terms, repatriation means shifting large datasets—often petabytes—from services like AWS, Azure, or GCP into local S3‑compatible storage where you own the hardware, the network, and the operating model. Because the S3 API has become the de facto standard for object storage, modern repatriation initiatives typically focus on landing this data on an on‑prem S3 platform such as Cloudian HyperStore.
Why now: the cloud hangover
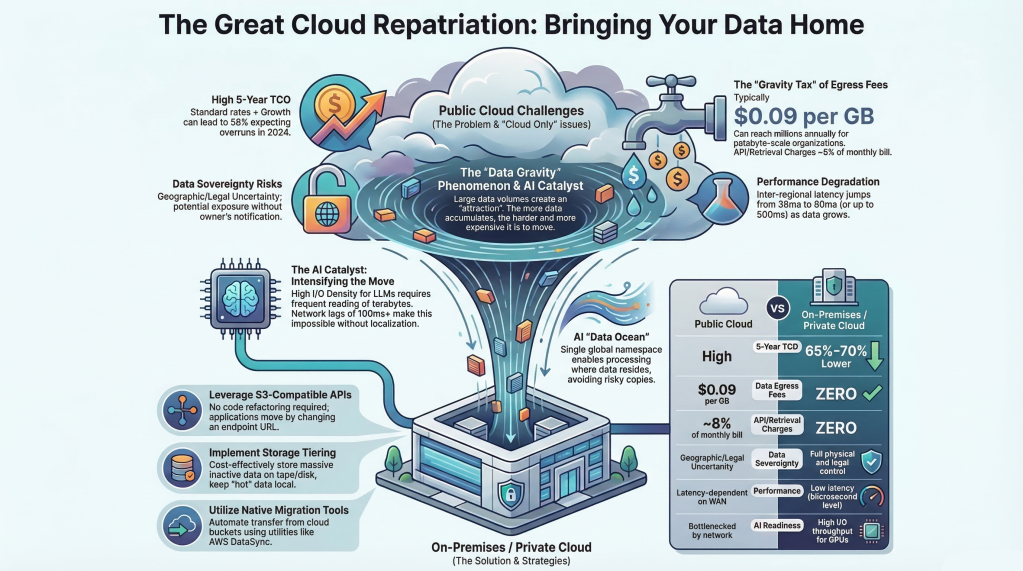
Many enterprises are experiencing a “cloud hangover”: the realization that the convenient, elastic cloud platform they adopted five to ten years ago is now a major line item and a strategic constraint. Recent studies show a large majority of IT decision makers have hit obstacles with cloud adoption, including unexpectedly high costs, data egress fees, and complexity around governance and compliance.
Key drivers of the shift include:
- Cost: Public cloud storage plus egress, API calls, and premium performance tiers often make steady‑state TCO significantly higher than on‑prem alternatives—sometimes by 60–70%.
- Governance and sovereignty: Regulations (GDPR, HIPAA, industry mandates) increasingly require strict control over where data lives and who can access it, which is harder to guarantee in multi‑tenant public clouds.
- AI data gravity: Training and inferencing at scale demand that compute sit close to massive datasets; constantly pulling data across WAN links from a public cloud into AI clusters elsewhere is both slow and expensive.
Data repatriation is a direct response to these pressures, letting organizations realign their infrastructure with economic reality and AI‑driven strategies instead of cloud provider pricing models.
Data gravity and AI: why location wins
“Data has gravity” is more than a cliché—it’s a law of motion for AI architectures. As datasets grow into multi‑petabyte and exabyte scales, applications, compute clusters, and analytics tools naturally move toward the data to minimize latency, reduce network costs, and simplify integration.
For AI workloads, this means:
- Training: Large model training and fine‑tuning need high‑bandwidth, low‑latency access to huge volumes of unstructured data—images, logs, documents, audio, video—stored as objects.
- Inference at scale: Real‑time or near‑real‑time inference requires predictable performance and often local proximity to edge or datacenter GPUs.
- Iteration: AI teams iterate quickly, repeatedly scanning and reshuffling the same data; when that data lives in a metered cloud bucket, you pay the “gravity tax” every time you access or move it.
Keeping AI data sitting in a public cloud while your GPUs and specialized infrastructure are elsewhere is like parking your car in another city and calling an Uber to fetch it every time you drive. On‑prem S3 object storage collapses this distance by co‑locating bulk data with your AI infrastructure, whether that’s in your main datacenter, colocation facility, or regional edge site.
Why Cloudian HyperStore for repatriation?
Cloudian HyperStore is an on‑prem, software‑defined S3 object storage platform designed for cloud‑scale datasets, including AI training corpora and analytics lakes. It implements the S3 API natively and fully, which means the same applications built for Amazon S3 can usually point at Cloudian with minimal or no code changes—often just an endpoint update and credential swap.
Key attributes that make Cloudian ideal as the repatriation target:
- Native S3 compatibility: Full S3 API support ensures seamless migration of data and app workloads from public clouds and other S3‑compatible platforms.
- Cloud‑scale capacity: HyperStore scales from a few nodes to hundreds, supporting petabyte to exabyte‑level deployments without disrupting applications.
- Hybrid flexibility: Policy‑based data tiering integrates on‑prem HyperStore with AWS, Azure, and GCP, enabling hybrid patterns where you can keep hot/AI data local and offload colder tiers if desired.
- Cost efficiency: On‑prem deployments can cut storage costs by as much as 65–70% relative to equivalent public cloud usage, especially when you factor out egress and premium performance tiers.
Because HyperStore looks and behaves like the S3 service you already use, it becomes a natural “landing zone” when you decide to bring your data back home, shielding your applications from complexity while you change the underlying economics.
How repatriation to Cloudian helps AI specifically
When you center AI strategy on on‑prem Cloudian HyperStore, you’re not just swapping vendors—you’re changing physics for your AI teams.
Benefits for AI data and workloads include:
- Localized data for GPUs: Co‑locate HyperStore with your GPU clusters so training and inference traffic stays on a high‑speed, low‑latency internal fabric instead of transiting WAN links to public cloud storage.
- Predictable performance: Cloudian’s scale‑out architecture delivers consistent throughput as you add nodes, which is critical for feeding parallelized AI pipelines.
- No egress surprise: Once data is repatriated, internal access to AI datasets is not metered in the same way as egress from public cloud buckets, allowing teams to experiment more freely without triggering cost explosions.
- Unified data lake: HyperStore consolidates unstructured data across backup, archive, analytics, and AI into a single S3 namespace, simplifying governance and access control.
The net effect is more training runs, bigger datasets, and faster iteration cycles at a lower and more predictable cost base—precisely what AI teams need to sustain innovation.
Why “back out of the cloud” is often the true answer
For many organizations, the question is no longer “Should we use the cloud?” but “Which workloads actually belong there?” High‑volume, high‑reuse AI datasets are uniquely ill‑suited to metered, remote storage when you own—or plan to own—local AI infrastructure.
Repatriating these datasets to Cloudian HyperStore delivers:
- Economic alignment: You trade variable, usage‑based cloud expense for a capital‑efficient, scale‑out platform you own and amortize.
- Architectural alignment: Data sits where AI compute lives, eliminating the gravity tax and unlocking higher utilization of expensive GPUs.
- Strategic alignment: You regain control over data placement, compliance posture, and vendor relationships instead of optimizing for someone else’s business model.
This isn’t about abandoning cloud innovation; it’s about recognizing that for AI data—the crown jewels of your enterprise—the right place is usually back on infrastructure architected around your needs, not your provider’s. On‑prem S3 object storage with Cloudian HyperStore gives you that foundation and turns “data repatriation” from a corrective measure into a long‑term AI strategy.