


At Cloudian, we often tell customers that the secret to maximum performance is parallelism or multi-threading. The reality is that a single TCP stream to an S3 object storage system cannot take full advantage of the available bandwidth between the client and the Hyperstore cluster. While a Hyperstore cluster is capable of efficiently handling a large number of simultaneous uploads, a single upload on its own is far from optimal. In some workflows, it is possible to send multiple objects simultaneously; however, in many instances, users still need a way to optimize the performance of a single file upload or outgoing data stream.
We recently had the opportunity to work with a customer that had just this type of problem. They needed to read from a tape device and write directly to Hyperstore without any intervening files. To meet this challenge, we had to create a new way to read data from a single incoming stream and send it to Hyperstore with multiple parallel streams. Maximum performance was critical in this case. If tape drives are not able to operate at their streaming rates then they can suffer from the “shoe-shining” effect. Shoe shining exists when the tape media cartridge is stopped and restarted rapidly moving it back and forth causing wear to the heads of the tape drive, and can negatively affect the readable portion of the tape thus contributing to data loss over time. To avoid this problem, we had to be sure that we could write data to Hyperstore as fast or faster than the incoming data from the tape drive.
The S3 API supports an upload mechanism called multi-part-upload or MPU that allows a single stream of data to be broken into multiple parts that are uploaded in parallel. Once uploaded, all of the parts are then reassembled on the receiving side to create a new object that gets distributed and stored with the associated data protection policies and schemes.
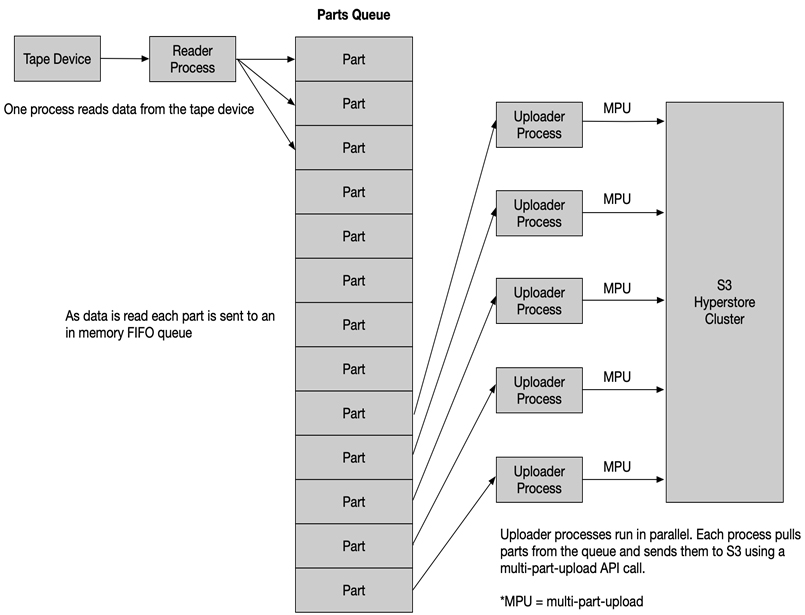
To bring this all together as a solution, we created a software tool, written in Python, that spawns multiple subprocesses and an in-memory queue. A single process reads data or “parts” of the data from the tape device, and then it is placed into the in-memory FIFO queue. This process continues independently reading all of the parts until the entire data stream has been consumed.
The parent process also spawns multiple uploader processes. These processes pull parts from the in-memory queue and send them to the S3 API on the Hyperstore cluster as an MPU session. Because multiple uploads happen simultaneously and in parallel, then it dramatically increases the aggregate or total throughput of the transfer. The MPU session is completed once all of the parts have been uploaded. At this time, the object is then reassembled and becomes available on the Hyperstore cluster.
By using this method in our lab, we saw increases of 10-15x the performance of a single upload stream. With a single VM pushing a single set of data to a 6-node cluster, we measured write performance results of over 600MB/sec — which far exceeded the customer stated requirements. Through this exercise, we now have an efficient and effective way to read streaming data from a tape device into a distributed HyperStore cluster. And, with some further planned optimizations, we expect to realize even better performance in the future.
