

Velero is open-source software to backup and restore Kubernetes cluster resources. Cloudian HyperStore is S3-compatible object storage software with an elastic, scalable architecture. Velero uses the object storage as the storage target of the backup data, writing data for new backups and reading data to restore a backup. Using the AWS S3 plugin with no changes, Velero can use HyperStore as the object storage layer. In contrast to using AWS S3, HyperStore can be deployed on-premise or on public clouds, in many cases offering cost savings and operational flexibility. In the following sections, we provide a simple how-to example of using Velero (both v1.2.0 and v1.3.1 were tested) with HyperStore v7.2.
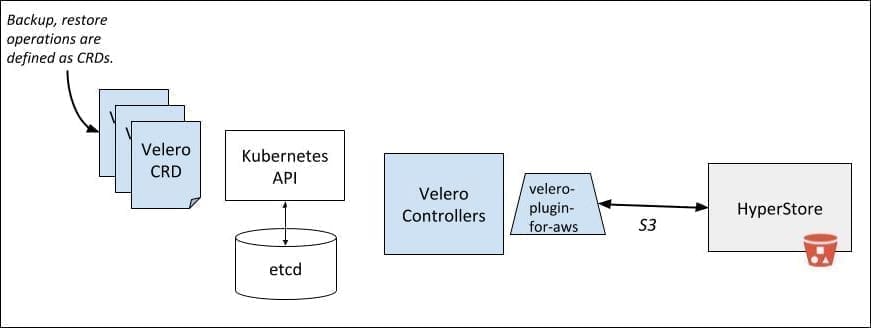
Setup
1. The following steps are prerequisites to using Velero and HyperStore for backup/restore.
HyperStore installed using the included installation wizard on top of CentOS. HyperStore can run on VMs, bare-metal, or Cloudian appliances, and a free trial is available. Typically, HyperStore is installed on multiple nodes and multiple data centers. Once installed, S3 requests can be sent to any node. In our example, we will send the S3 requests to the HyperStore node at 10.10.3.102.
2. Kubernetes installed. We used minikube v1.7.2 on CentOS 8 (instructions) with Kubernetes v1.17.2.
![]()
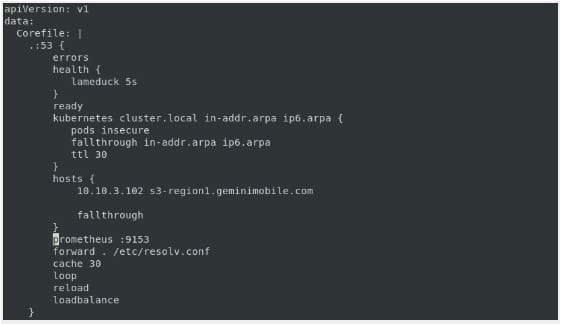
3. A DNS server on the cluster with the IP address of the S3 server and the S3 URL set in the ConfigMap.
![]()
Add the following code after the block of kubernetes cluster.local in-addr.arpa ip6.arpa
For example, in the below 10.10.3.102 is the HyperStore IPADDR and s3-region1.geminimobile.com is the S3 URL.
4. Create an S3 bucket in Hyperstore where the Velero data is stored. The bucket name is configurable, and we’ll use the name “velero”. There are multiple S3 tools that can be used to do S3 operations. In this case, we are using the AWS Command Line Interface v2.


Velero Installation
Now that HyperStore and Kubernetes are configured, Velero can be installed and configured.
1. Install Velero using the “Basic Install” instructions:
![]()
2. Create a Velero-specific credentials file (credentials-velero) in thevelero directory (e.g., ~/opt/velero-v1.3.1-linux-amd64/)

The HyperStore access key and secret key can be retrieved using the Cloudian Management Console (CMC) menus: User -> Security Credentials -> S3 Access Credentials.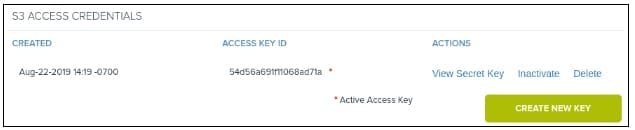
3. Then run the Velero “install” command using the AWS S3 plugin.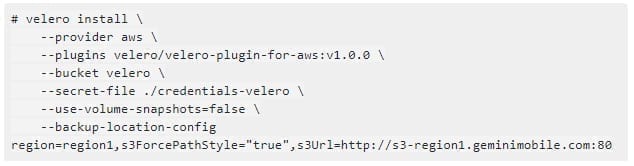
Options:
– provider. “aws” is used for HyperStore.
– plugins. “velero-plugin-for-aws” is designed for AWS S3, but works fine for HyperStore.
– bucket. This is the name of the bucket previously created in HyperStore where backups will be stored.
– secret-file. The file path of the AWS credentials (access key, secret key) created earlier.
– use-volume-snapshots. The default is true, so need to set false in order to not trigger the persistent volume snapshots.
– backup-location-config. Key-value pairs that are specific to the AWS plugin.
Test Backup and Restore
The Velero tarball includes a useful examples/nginx-app directory to do a basic test of the backup and restore procedure.
1. Deploy the example nginx application.![]()
2. Confirm that both the velero and nginx-example deployments are successfully created: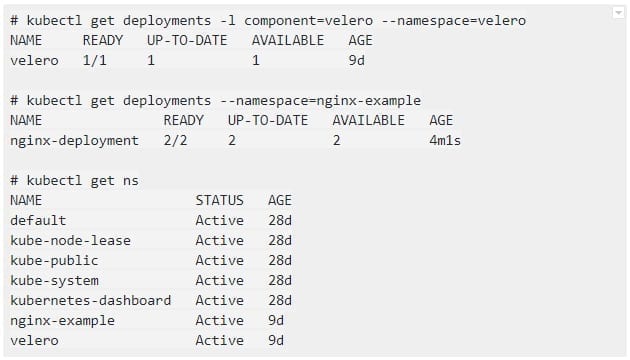
3. Create a backup for any object that matches the app=nginx label selector:
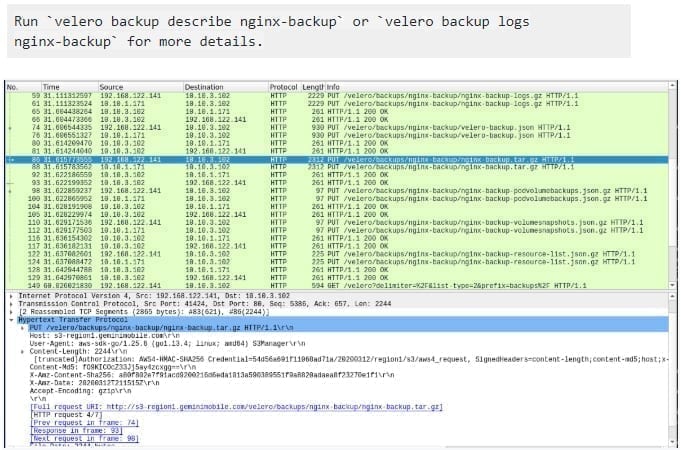
The above figure shows a wireshark view of the S3 PUT requests that are writing backup data to HyperStore.
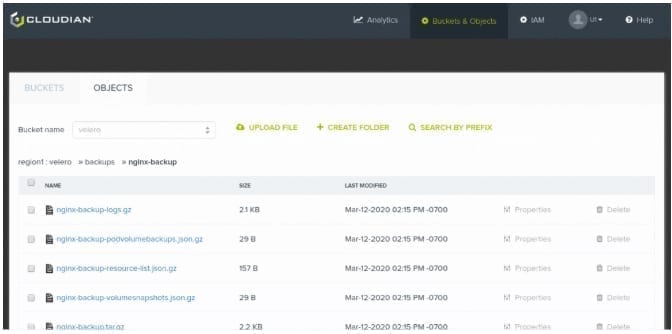
After running this command, a folder named backups with the backup data is in the Hyperstore velero bucket.
Also, you can use the Velero CLI to view the backups.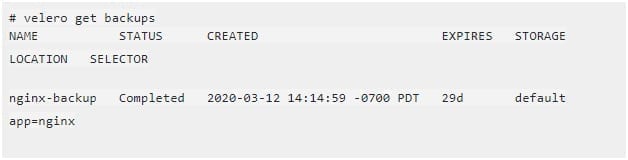
4. To test a restore from a backup, we first delete the existing nginx-example namespace: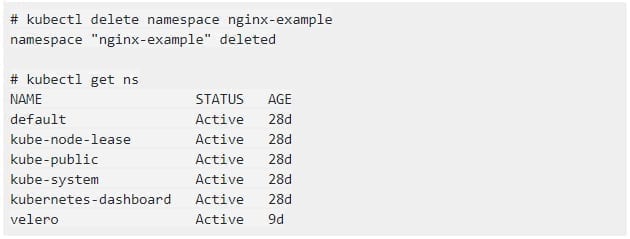
and then restore from the previously created backup: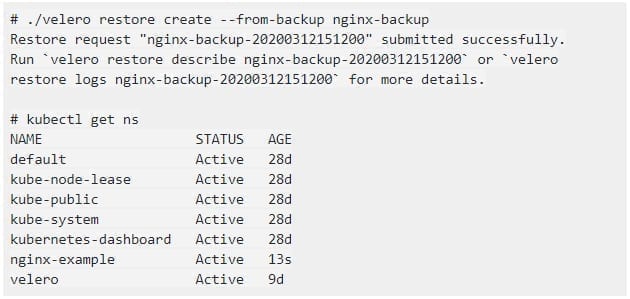
Use Cases
The primary use cases with the combination of Velero and HyperStore are the same as using any object storage, namely, to backup and restore data and also to migrate data from one Kubernetes cluster to a different Kubernetes cluster at a different location. In addition, some different use cases result from HyperStore being able to run as on-premises software; for example, being on-premises is important if data must be maintained as private and secure. We are also investigating combining Velero with additional HyperStore S3 features like access control by bucket- or IAM policies, Object Lock, encryption, and lifecycle management such as tiering objects to another storage system and the automatic deletion of old objects.