Amit Rawlani, Director of Solutions & Alliances, Cloudian
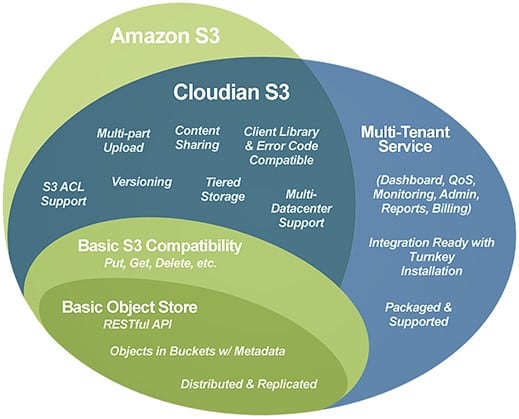
In late 2018, Splunk introduced a feature called SmartStore, which offers enhanced storage management functionality. SmartStore allows you to move warm data buckets to S3-compatible object stores such as Cloudian HyperStore, the industry’s most S3-compatible on-prem object storage platform. Moving the data from expensive indexer storage achieves many benefits, including:
- Decoupling of storage and compute layers for independent scaling of those resources to best serve workload demands
- Elastic scaling of compute on-demand for search and indexing workloads
- Growing storage independently to accommodate retention requirements
- Cost savings with more flexible storage options
However, migrating existing Splunk indexes to SmartStore is a one-time occurrence. It is also an intensive activity with no undo button. Based on extensive internal testing and validation efforts, the Cloudian team has developed best practices for ensuring smooth deployment of Splunk SmartStore with Cloudian HyperStore. These range from provisioning all the way to safeguards to consider during the migration process itself. Listed below is a summary of the best practices guidelines.
Provisioning
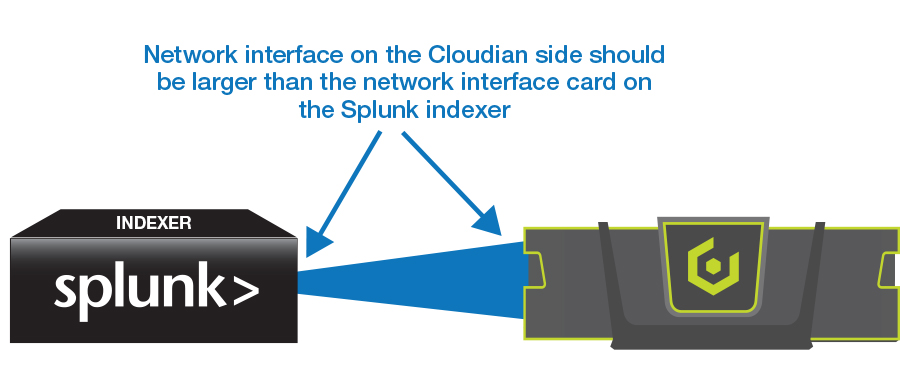
For correct operations, the recommended deployment is HyperStore nodes with a network interface larger than the network interfaces on the Splunk Indexers.
Tuning Splunk SmartStore
Concurrent upload setting should be 8 threads (default value)
Concurrent download setting should be 18 threads (max tested is 24 threads)
For high ingest rates bucket size should be set to 10GB (setting = Auto_high)
Tuning Cloudian HyperStore
Consistency setting should be kept as Quorum. Anything else will have a performance impact
Link MTU should be set to 1500 to ensure optimal performance
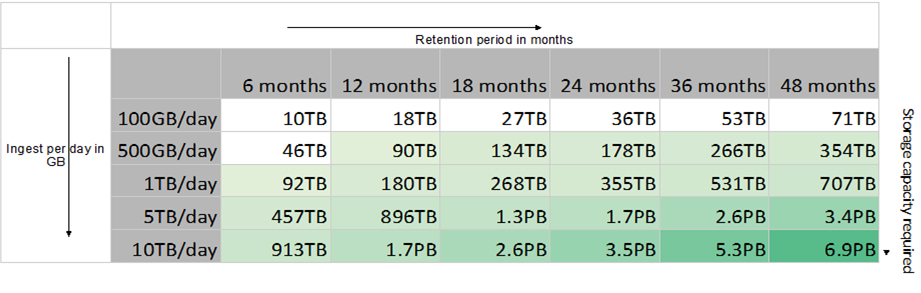
Storage Sizing
Storage sizing guidelines should be followed. These will vary based on the compression ratios, metadata size and indexer volume sizing. Below is one specific guideline.
Cache Sizing
Undoubtedly the most important decision for appropriate SmartStore operations. Following parameters need to be considered while sizing SmartStore cache.
- Daily Ingestion Rate (I)
- Search time span for majority of your searches
- Cache Retention (C) = 1 day / 10 days/ 30 days or more
- Available disk space (D) on your indexers (assuming homogeneous disk space)
- Replication Factor (R) =2
- Min required cache size: [I*R + (C-1)*I]
- Min required indexers = Min required cache size / D
- Also factor in ingestion throughput requirements (~300GB/day/indexer) to determine the number of indexers
Based on the above parameters, the table below gives a framework on how to get the recommended SmartStore cache sizing.
| 1TB/Day 7-Day Cache |
1TB/Day 10-Day Cache |
1TB/Day 30-Day Cache |
10TB/Day 10-Day Cache |
10TB/Day 30-Day Cache |
|
|---|---|---|---|---|---|
| Ingest/Day (GB) | 1,000 | 1,000 | 1,000 | 10,000 | 10,000 |
| Storage/Indexer (GB) | 2,000 | 2,000 | 2,000 | 2,000 | 2,000 |
| Cache Retention | 7 | 10 | 30 | 10 | 30 |
| Replication Factor | 2 | 2 | 2 | 2 | 2 |
| Min Required Cache (GB) | 8,000 | 11,000 | 31,000 | 110,000 | 310,000 |
| Min Required #Indexers | 4 | 6 | 16 | 55 | 155 |
Migration to SmartStore
As mentioned, the migration to SmartStore is a one-way street. For existing indexes following steps are recommended for a smooth migration
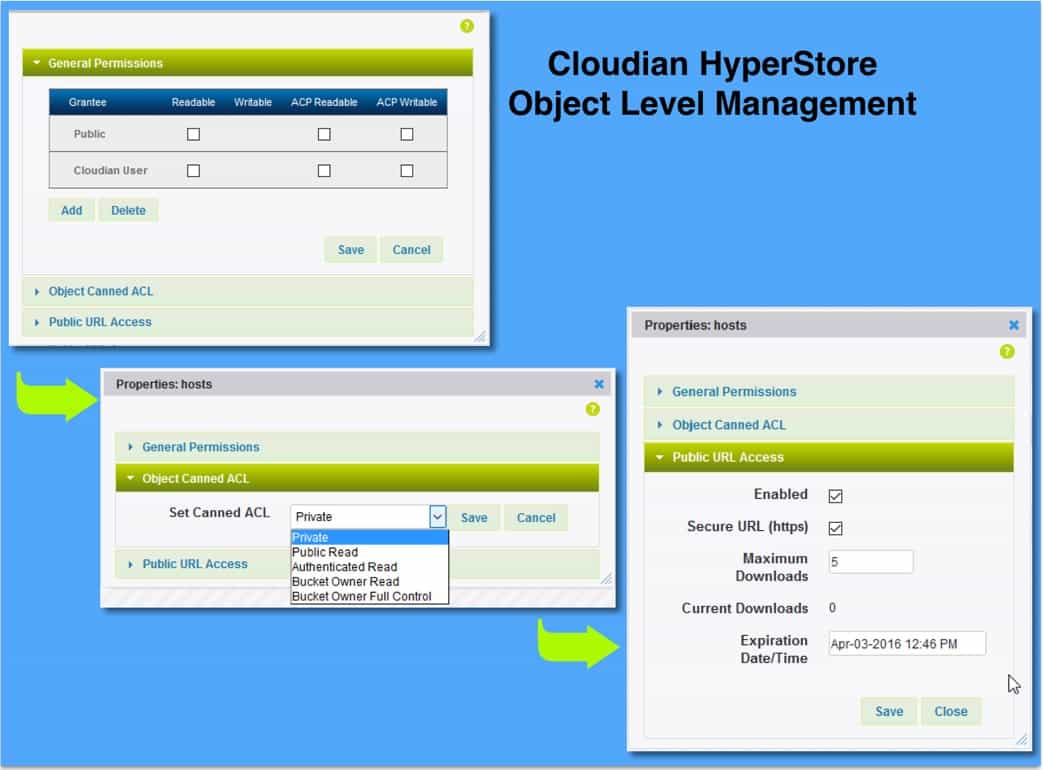
- Setup SmartStore target S3 bucket on HyperStore.
- Upload a file to the S3 bucket via CMC or S3 client.
- Set up the Volumes on Splunk Indexers without setting RemotePath for Indexes.
- Push the changes with the new Splunk Volume to the Splunk Index cluster.
- Use the Splunk RFS command to validate each Indexer is able to connect to the volume.
/opt/splunk/bin/splunk cmd splunkd rfs — ls –starts-with volume:NewVolume
- Once all Indexers report back connectivity Migrations can begin.
- Set RemotePath for one Index at a time. This allows for the ability to manage Index migrations more easily. This also limits the work of each indexer as it tries to move all Warm buckets for every index at once.
For more information on how to deploy Splunk SmartStore with Cloudian HyperStore, see the detailed deployment guide here.
 But in order to serve and protect your data for the always on, always available IoT world, what requirements should we take into account before deploying any data protection or storage solution? If you are a data protection geek, you’ll most likely see some of your requirements being listed on the right. If you are a data protection solutions provider, you guys definitely rock! Data protection solutions such as Commvault, NetBackup, Rubrik, Veeam, etc. are likely the solutions you have in-house to protect your corporate data centers and your mobile devices. These are software-defined and they are designed to be highly available for on-premise or in-the-cloud data protection.
But in order to serve and protect your data for the always on, always available IoT world, what requirements should we take into account before deploying any data protection or storage solution? If you are a data protection geek, you’ll most likely see some of your requirements being listed on the right. If you are a data protection solutions provider, you guys definitely rock! Data protection solutions such as Commvault, NetBackup, Rubrik, Veeam, etc. are likely the solutions you have in-house to protect your corporate data centers and your mobile devices. These are software-defined and they are designed to be highly available for on-premise or in-the-cloud data protection.