

The Edge Needs a Streaming Feature Store
The next wave of digital transformation is a synthesis of on-premise and cloud workloads where the same compute and storage cloud services are also available on-premise, in particular at the “edge” — near or at the location where the data is generated. For this edge-cloud synthesis to work, the cloud services — specifically programming APIs — must be available at the edge without requiring cloud access. For example, popular AWS services such as S3 for data storage and Lambda for serverless computing also need to work at the edge independently of the cloud.
Some APIs are more useful to have at the edge due to the specific nature of the edge where raw data is generated and real-time decisions are needed. A “feature store” that rapidly stores data in the form of records composed of multiple features is an example of API functionality that is needed at the edge. There are various descriptions of a feature store (e.g., AI Wiki), but it’s essentially a shared data store for multiple records of features and used for analysis and machine learning. For example, the records can be used to train and validate a deep learning model. Once the records are in the feature store, they can be archived and queried by different teams for tasks like machine learning, data exploration, and other analysis such as summarization.
SageMaker Feature Store provides feature store functionality for the AWS cloud, but users also want the same capabilities at the edge to ingest raw data and use it to make real-time decisions without needing to make a round-trip to the cloud.
Another property of edge data is that it is often continuously generated as a stream of data. Ingesting the data stream can be done with a feature store API, and then users can transform the continuous data stream into metadata usable for analysis. Streaming software like Apache Flink can first partition and window the streaming data, then apply transformations including aggregation functions (e.g., average), filtering, and map functions.
Cloudian Streaming Feature Store (SFS)
Cloudian has developed the Streaming Feature Store (SFS) that implements the SageMaker Feature Store API, adds data stream processing functionality with Flink, and is deployed as Kubernetes-managed software at the edge.
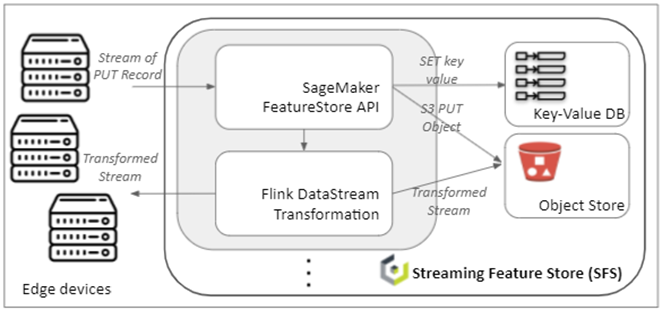
Feature Store API
The SageMaker FeatureStore API has two parts: Feature Group API and Record API. The Feature Group API manages feature groups that are logical groupings of features. Each feature is defined by a name (String) and a type (String, Integral, Fractional) — e.g., “name:Age, type:Integral”. Each feature group must define a feature that is the unique identifier for the feature group and a feature that is the event time of the feature group used to determine the time ordering of the records. The Record API is a REST API for PUT/GET/DELETE record where a record is a single instance of a feature group.
Example Feature Group “TemperatureSensor”:
| FeatureName | FeatureType | Notes |
| sensor_id | String | Unique identifier |
| val | String | |
| time | String | Event time |
Example Record:
| FeatureName | ValueAsString |
| sensor_id | sensor324 |
| val | 28.4 |
| time | 2022-10-29T09:38:41Z |
As depicted in Figure 1, SFS has both a key-value database system and an object store. These two types of storage systems are used to implement the online store and offline store of the SageMaker FeatureStore.
The online store is a low-latency store for real-time lookup of records, storing the latest (by event time) feature group data record. The low-latency for queries makes it applicable for real-time analysis. For example, if there is a point-of-sale device that is processing a credit card transaction, real-time analysis using a trained deep learning model is performed to predict whether the transaction is fraudulent or not. This type of decision-making must be done in real-time. Having the fraud-or-not decision be delayed makes it unusable at the point-of-sale.
The offline store is a high-capacity S3 object store where all data is versioned, thereby making the data available for point-in-time queries. As record data streams in, the older records for the same unique identifier are automatically migrated from the online store to the offline store. The records are stored in Parquet format for space-efficient as well as performant columnar storage. The offline store is implemented using an S3 API compatible object store, Cloudian’s HyperStore. This provides a horizontally scalable system with the full power of the S3 API. By configuration of the S3 endpoint and credentials, any fully S3-compatible object store can be used.
Stream Processing
As mentioned earlier, a feature store for edge applications needs to operate with continuously streaming data like sensors emitting readings, surveillance cameras with live video, and manufacturing processes detecting bad components. To make it a “streaming” feature store, it must have the capability to analyze continuous streams of data.
Stream processing within SFS is done using Flink’s DataStream API. As new records are added via the PUT record API, a data stream transformation (e.g., filtering, defining windows, aggregating) is optionally executed with the transformed data written to a data sink that could be either an S3 bucket, a file, or another Feature Group. By writing the transformed data to a Feature Group, multiple transformations can be chained together in a pipeline. For example, raw transaction data can be aggregated into a 10-minute summary statistics Feature Group which can then be fed into a 24-hour summary statistics Feature Group.
Windows are used to split the data stream into groups of finite size which can then be processed. Flink defines multiple window types, but currently SFS implements only the SlidingProcessingTimeWindows that has size and slide parameters used to create sliding windows of fixed size (e.g., 1 minute) every slide period (e.g., 10 seconds). Below is an example of a Feature Group to hold aggregated data collected for each sliding window.
Example Feature Group “AggregatedTemp60”:
| FeatureName | FeatureType | Notes |
| key | String | Unique identifier |
| start | String | Event time |
| count | String | The number of records in the window |
| max | String | The max value in the window |
| min | String | The min value in the window |
| sum | String | The sum value of values in the window |
| duration | String | The time duration of the window |
Infrastructure to Enable the Edge
I have attempted to show how a streaming feature store is a useful component for edge applications where streaming data can be rapidly ingested and then analyzed in order to make real-time decisions. SFS is a part of Cloudian’s HyperStore Analytics Platform (HAP), a Kubernetes-managed infrastructure for compute and storage at the edge. Using built-in Kubernetes functions, flexible and dynamic Pod scheduling is based on available resources (CPU/GPU/RAM/Disk). Other HAP components include an S3-compatible object store, a scalable, distributed S3 SELECT processor, and an S3 Object Lambda processor.