

Build a Modern Observability Platform with Cribl and Cloudian
In our recent press release, we announced our partnership with Cribl. Cribl Stream is an observability pipeline that collects data from any source and can send and replay data to a Cloudian HyperStore S3-compatible data lake. Together, Cribl Stream and Cloudian HyperStore allow you to create a full modern observability platform. This blog covers how to set up Cloudian HyperStore for use with Cribl Stream.
An effective observability platform is more than just a monitoring tool. It builds on traditional monitoring capabilities, but provides deeper insights into the data that can help to optimize performance, ensure availability and improve the customer experience.
Cribl Stream collects the log data from many sources and stores it in Cloudian HyperStore. At the same time or later, the log data can be forwarded to solutions like Splunk or Elastic for further processing. Cribl is using Cloudian HyperStore as a large buffer for all log events it is receiving.
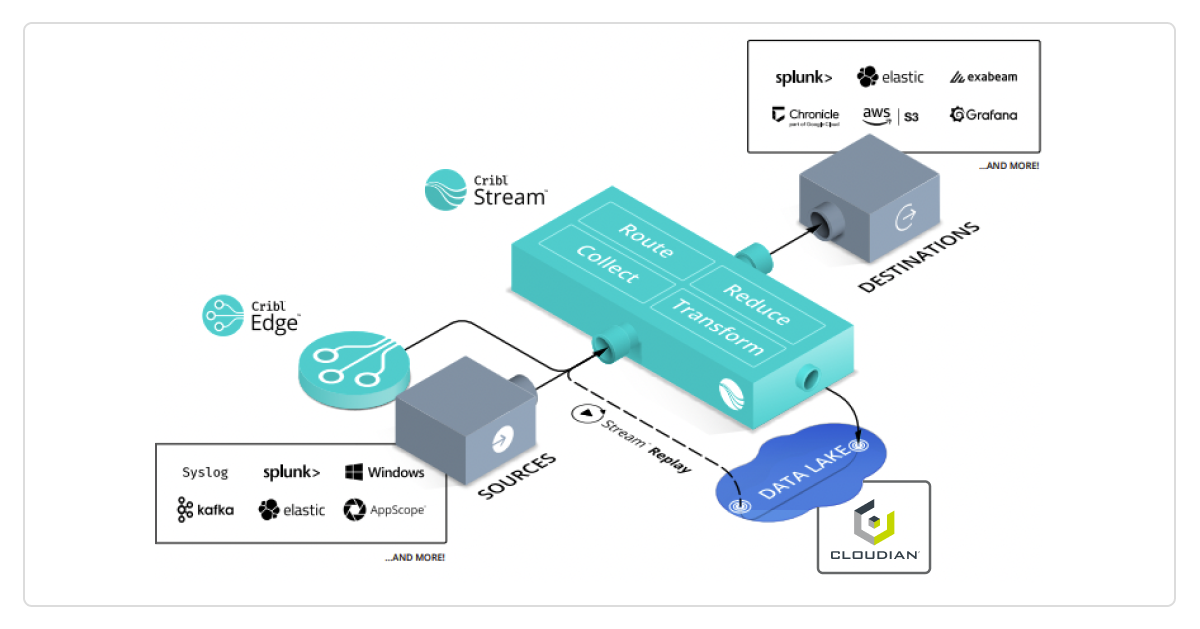
As log events can result in very small objects written to the HyperStore Cloudian system, we put together some recommendations and best practices to ensure flawless operation with Cribl and Cloudian.
Initial Setup
In order to use Cloudian HyperStore with Cribl, you need to add a new destination by using “+ Add Destination”. As an S3-compatible system, Cloudian can be connected to Cribl by using the MinIO destination.
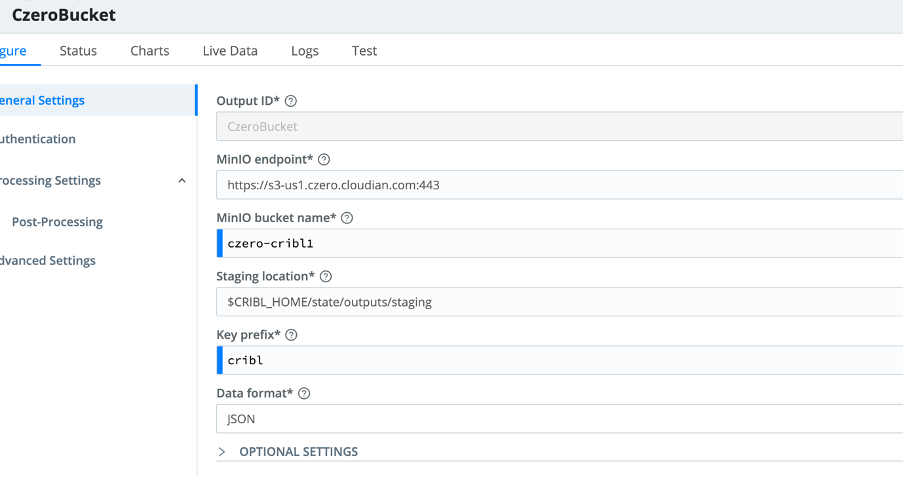
- Output ID: Enter a unique name for your Cloudian HyperStore definition.
- Endpoint: Cloudian HyperStore endpoint URL (e.g., https://s3-newyork.company.xyz:443).
- Bucket name: Name of the destination Cloudian HyperStore bucket. This value can be a constant, or a JavaScript expression that will be evaluated only at init time. E.g., referencing a Global Variable: myBucket-${C.vars.myVar}. Ensure that the bucket already exists, otherwise Cloudian HyperStore will generate “bucket does not exist” errors.
- Staging location: Filesystem location in which to locally buffer files before compressing and moving to final destination.
- Key prefix: Root directory to prepend to path before uploading.
- Data format: The output data format defaults to JSON. Raw and Parquet are also available.
Use the Authentication Method buttons to switch Authentication to “Manual.”
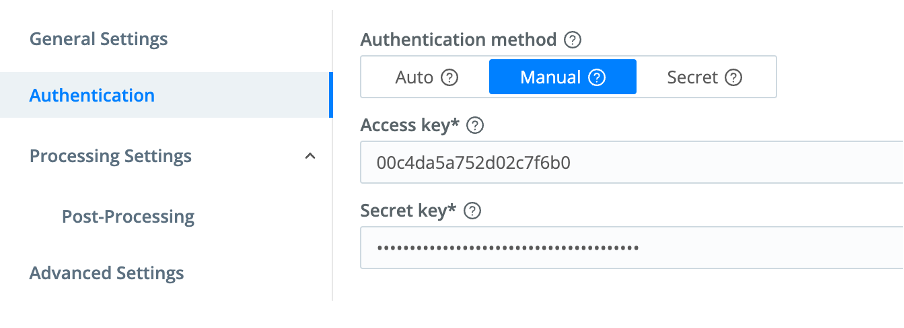
The Manual option exposes these corresponding additional fields:
- Access key: Enter your S3 access key.
- Secret key: Enter your AWS secret key.
Folder Structure and Object Size
Partitioning is used to configure in which structure data is written to a S3 bucket. To limit the number of files in each directory, partitioning expressions should specify dates down to the hour or minute.
Received events are written by every worker thread into a file. Basically, the file stays open for a defined amount of time and events are stored into the file as long as it is open. Events are collected over X minutes (“Max file open time” setting) and written to S3 after this configured time (e.g. 300 sec). Increasing the “Max file open time” value will allow to store more events in a file which will result in larger file sizes.
Partition Expressions essentially define how files are partitioned and organized as metadata from the events is added to the S3 bucket directory structure. To limit the number of files in each directory, partitioning expressions should specify dates down to the hour or minute.
Cloudian HyperStore Configuration for Cribl Stream
Cloudian HyperStore needs no special configuration for the Cribl workload. Depending on the log data importance, it might make sense to replicate the data over two or more data centers to increase availability.
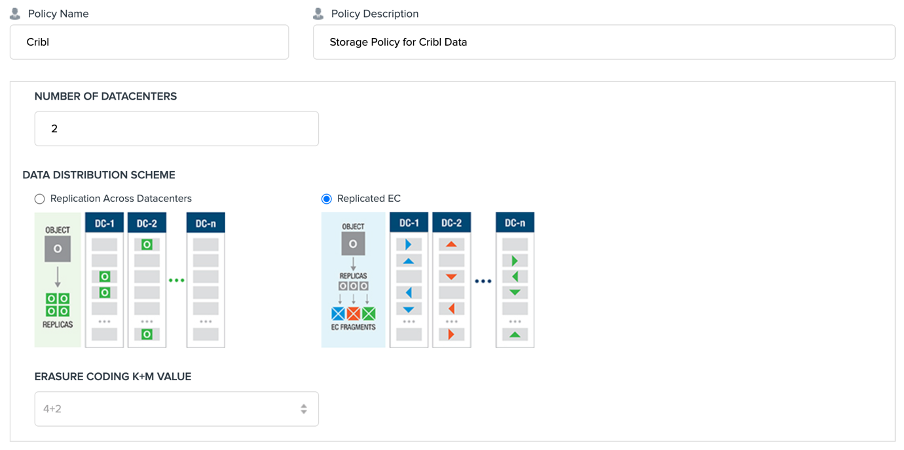
We recommend using an RF3 or Erasure Coding 4+2 protection scheme inside the storage policy. Depending on the settings, object sizes can be very small.
You can enable SSL for S3 and other services to increase security. Cribl is able to work with CA-signed and self-signed certs.
Summary of Setup and Benefits
Together, the solution built on Cribl and Cloudian lets you parse, restructure, and enrich data in flight – ensuring that you get the right data, where you want, and in the formats you need. Customers can convert their logs into metrics, reduce cost, and increase search speed.
Cloudian HyperStore is an ideal base for this as it provides a secure data lake that scales with your data. With Cloudian, when your storage requirements grow – due to more events stored or use cases added – you can simply add one or more nodes to get more storage capacity.
At the same time, Cloudian can protect data from loss due to equipment failure, encrypt data on the host level, secure it with role-based access controls, and protect data in flight with SSL.
Now you know the basics of how to build a modern observability platform with Cribl Stream and Cloudian HyperStore.
Interested in learning how actual customers use Cribl and Cloudian together? Watch this.

Sascha Uhl, Solution Architect for Strategic Alliances, Cloudian
View LinkedIn Profile