

by Gary Ogasawara VP Engineering at Cloudian Inc
Introduction
Recently, we had a hackathon with HGST engineers to deploy and exercise Cloudian HyperStore on HGST’s open Ethernet drive architecture (link: http://www.hgst.com/science-of-storage/emerging-technologies/open-ethernet-drive-architecture). Each storage drive is a “server on a drive” including CPU, RAM, Linux OS, and a direct Ethernet connection in a standard 3.5” HDD form factor.
Putting our HyperStore software on the drive has many potential advantages including reducing the required number of standard server nodes to run our software. The obvious advantage is hardware cost, but there are other benefits like size, power and cooling consumption, and ease of maintenance (e.g., replace a drive instead of a server).
The questions we had were:
1) could the configured drive run our software at all?
2) if we could get it up and running, would the performance be sufficient for realistic use cases?
At the end of a few hours, we could answer both of these affirmatively.
The Setup
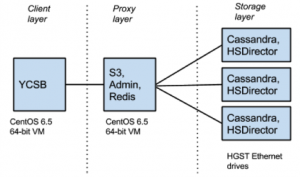 Typically HyperStore is deployed as peers where all nodes have the same functions and processes. This configuration has a lot of operational advantages to flexibly add/remove nodes and resiliently handle temporary hardware or network issues. But for a server-on-a-drive architecture, it’s useful to separate the processes into 2 layers: A proxy layer and a storage layer. This allows each layer to scale out separately. The storage layer was put on each HGST open Ethernet drive, and the proxy layer was put on a Linux VM. For sending S3 requests, we used Yahoo! Cloud Serving Benchmark (YCSB) (link:https://github.com/brianfrankcooper/YCSB) as the client layer.
Typically HyperStore is deployed as peers where all nodes have the same functions and processes. This configuration has a lot of operational advantages to flexibly add/remove nodes and resiliently handle temporary hardware or network issues. But for a server-on-a-drive architecture, it’s useful to separate the processes into 2 layers: A proxy layer and a storage layer. This allows each layer to scale out separately. The storage layer was put on each HGST open Ethernet drive, and the proxy layer was put on a Linux VM. For sending S3 requests, we used Yahoo! Cloud Serving Benchmark (YCSB) (link:https://github.com/brianfrankcooper/YCSB) as the client layer.
Though there were up to 60 drives available to use in the chassis, we focused on using 3 of them in a simple set of tests for the hackathon.
 Specs:
Specs:
- 32-bit Debian OS
- 4TB drive formatted as XFS (/dev/sda)
- 1 Gb network interface (ETH0)
Apache Cassandra (http://cassandra.apache.org/) is used to store object metadata and transaction logs. We use a forked version with some customizations.
Redis (http://redis.io/) is used for some global data like S3 bucket names.
The HSDirector process writes to a POSIX-compliant filesystem. The HSDirector process, like the other Cloudian components, is a Java server.
After building the versions using the Java compiler for the OS on the drive, doing some configuration for the smaller than usual RAM size, and setting the data directories, then the HGST Ethernet drives were up and running. Quick and easy in an open environment.
YCSB and the Cloudian processes for the proxy layer were installed on a CentOS 6.5 64-bit VM (our standard OS) each. Some networking configs with iptables and allowed ports were updated, and we were ready to run some S3 traffic.
In under 20 minutes!
The Tests
1. Run simple S3 operations.
These manual tests used a command line tool like s3cmd (http://s3tools.org/s3cmd) to create a bucket, create a set of objects in that bucket some 10 bytes and some 10MB in size, list the object contents of the bucket, retrieve the objects that were previously created, delete the objects, and finally delete the bucket.
2. YCSB to 1 drive with xfs (test1), 20 threads, 1MB object size, 120s run. Three traffic models:
100% PUT
100% GET
50% PUT, 50% GET
3. YCSB to 1 drives with ext4 (test11), 20 threads, 1MB object size, 120s run. Three traffic models;
100% PUT
100% GET
50% PUT, 50% GET
4. YCSB to 3 drives (test2, test3, test4), 40 threads, 1MB object size, 120s run.
100% PUT
YCSB by default records average latency, 95% latency, operations/second and others. These stats are written at 10 second intervals and also the total for the whole run.
On the HGST drives, dstat (http://dag.wiee.rs/home-made/dstat/) was used from the Debian OS to record CPU, disk I/O, OS paging, and network I/O.
All the above tests were completed successfully.

(Some) Analysis
Though the main purpose of this test was feasibility, we did observe some important points.
– The disk I/O in the 100% write tests was lumpy, ie., some seconds recorded high values while other seconds were 0. This is not ideal because that means we are not driving disk writes to capacity. The expected cause of this is a large amount of random writes. The Cassandra commit log, data directory, and Hyperstore data directories are on same spindle, thus requiring lots of physical disk head moving.
– 100% read traffic did not have the same lumpy disk I/O. There is not the same amount of disk I/O contention among different areas. For example, there is no reading of the Cassandra commit log. There is also possible caching in the OS pages, Cassandra, and Cloudian applications. Read throughput was very roughly double the write throughput.
– In most of the tests we were able to drive the open Ethernet drive’s CPU utilization near 100%. Generally this would indicate an opportunity to do TCP offload.
– ext4 vs. xfs. There was practically no difference in performance when comparing these two file systems. This was not surprising as these tests were short duration using a newly created file system.
Next
There remains a lot of homework, in particular, how we can slice and configure our application to best fit this type of new architecture, and we’re excited with the possibilities. We had a blast and want to thank the HGST team for their hospitality, preparedness, and technical skill. Party on the hard drive!