

We all know we are in the era of big data. What we’re still trying to get our hands around is the astonishing rate of growth of this data. Consider these sample statistics: Genomics data is growing faster than almost all other data creators, including astronomical data, and will need 40EB of storage capacity by 2025 to hold it all. As the number of internet of things devices reaches 24B by 2025, they are expected to require almost 100EB of storage capacity. A one-hour 8K High Definition (HD) video file will occupy 7.29TB of storage space, compared to today’s paltry 742GB with 4K HD resolution.
There has to be a way to get a handle on this explosive data growth. According to IDC, the world’s data will grow from about 29 zettabytes (ZB) in 2018 to 175 ZB by 2025, a growth rate of 66% per year. 45-90% of data becomes “cold” within weeks of its creation. Yet, most organizations continue to treat all this data the same. This cold, not-in-active-use data is still stored on expensive primary storage, and then backed up and replicated multiple times. Organizations without visibility into their data often aren’t aware of what or how much of their data has gone cold or what the fully-loaded costs of storing all this means, leading to over-provisioning of storage.
Making matters worse, even with 300% growth of storage capacity expected in the next 6 years, IT budgets are staying flat. Linearly adding more storage while datasets grow exponentially isn’t practical or economical; to borrow from an idiom I grew up with, it’s like “starting to dig a well after your crops start shriveling in a drought”: there’s no catching up. It is better to proactively understand, differentiate and separate the data that needs to be backed up.
It is important to know what makes up this data, who owns it, how useful it still is, when it was last accessed and what it is costing businesses to store, replicate and back it all up. Fortunately, 80% of this data is unstructured, making it ideal for storing as objects such as with our partner Cloudian’s HyperStore object storage platform. Object Storage has several advantages over traditional file-based structures – but more on that later.
There is no need to store AND replicate ALL data, multiple times, on high performance, expensive storage. With the ability to identify hot vs cold data, you can make smarter and far less costly storage infrastructure decisions.
This is what Komprise does best. It’s simple software (-only, no hardware) solution installs quickly as a virtual appliance, sniffing out shares and drives and, within 15 minutes, showing you analytics on your data. This includes whose data, how old, in which format, where is it stored, how much you would save (based on your own cost model) by offloading it to less expensive storage, how fast is it growing, and more. There is just one admin console that shows all this in one simple view. Figure 1 shows a true representation.
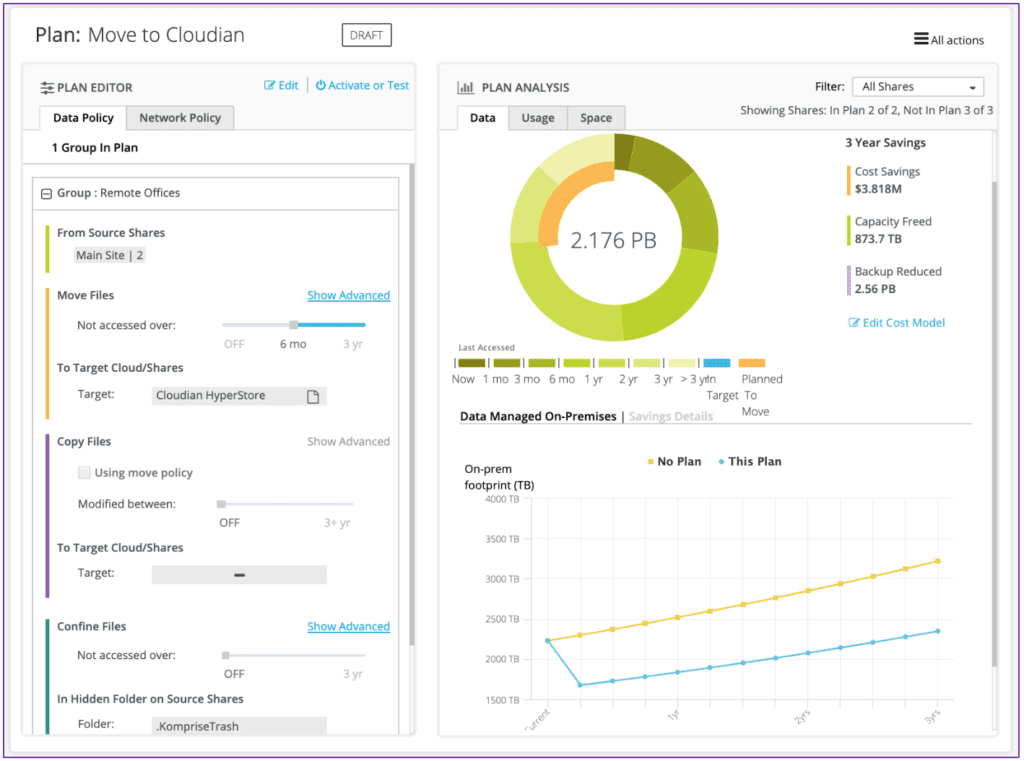
Figure 1: Insights into hot and cold data with cost and growth trends
Komprise works without using any agents, proprietary links or interfaces, and works seamlessly across any data sources that use NFS, SMB/CIFS, or S3 object/cloud storage. When it moves data, it doesn’t leave behind stubs, brittle pointers to moved files, which can leave the moved data orphaned if deleted. Moved data remains transparent and visible to users and applications that needs it; for the viewer or user, nothing appears to have changed. Files can be accessed directly from the target: users don’t have to use a Komprise tool to view or recall their files – in fact, Komprise prevents even Komprise lock-in.
Perhaps the best option available to copy, archive or migrate data to, is Object Storage. Komprise works especially closely with Cloudian, a leader in affordable, scalable, cloud-ready Object Storage, with the industry’s highest S3-compatible storage. We have a proven solution together with many joint customers.
Object storage uses a flat structure instead of the more traditional file-based hierarchy. This makes it ideal for holding unstructured data because of its unlimited scalability: Cloudian object storage can easily scale to petabytes without restrictions, and it does this non-disruptively with zero downtime. Unlike the limitations of files, each object is identified by its own details like metadata and ID number, making data search, retrieval and analytics much faster as it foregoes having to sift through traditional file structures and hierarchies. Because it scales out much easier than other storage environments, it’s less costly to store all the data. As an S3-compliant on-prem object storage, Cloudian also provides optional tiering and replication to public clouds thus helping “stitch” the cloud on to the premises.
Figure 2 below illustrates how Komprise and Cloudian are helping customers identify all their data across all storage, learn what’s hot versus cold, understand what’s it costing them, and transparently move it to efficient, cost-effective Cloudian products.
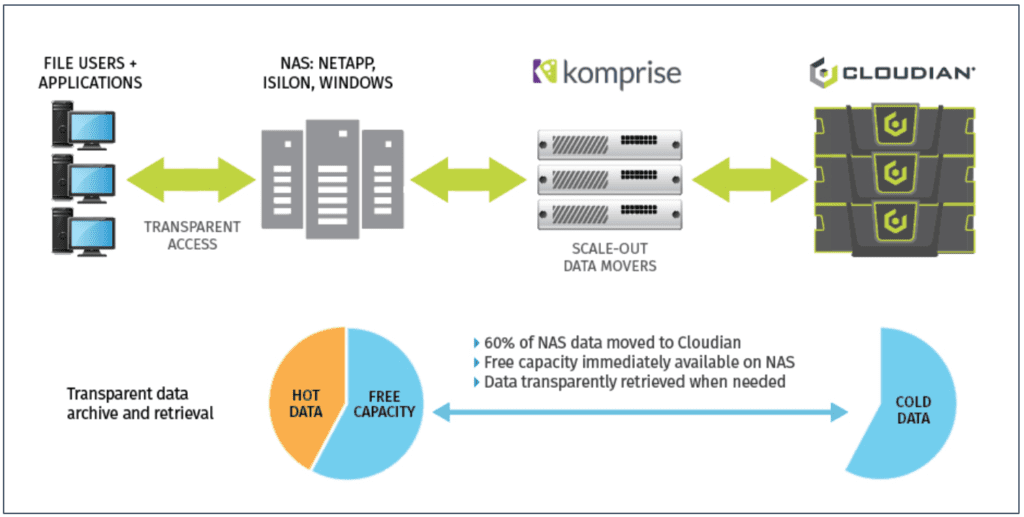
Figure 2: The Komprise + Cloudian Solution
To summarize, Komprise and Cloudian are great choices for organizations needing to get a handle on their data growth challenges. They provide fast, cost-effective, highly efficient solutions without scaling limits. They help keep users productive and focused, ensuring they can easily access the data they need, regardless of where it is located and without causing any disruption. It’s a partnership that works – our customers say so!
By Shamik Mehta
Product Marketing Director