

By Bharatendra Boddu, Principal Software Engineer and David Schleicher, Senior Technical Writer
Among the great new features of Cloudian HyperStore 5.0 is the introduction of HyperStore vNodes, which leverage and extend the virtual node technology of Cassandra. In contrast to traditional consistent hashing based storage schemes in which each physical node in the token ring is assigned a single token, with HyperStore vNode technology multiple tokens are assigned to each hard drive on each host. In essence, the storage ring is made up of many “virtual nodes”, with each disk on each host supporting its own set of vNodes.
This optimized token ring implementation provides benefits such as:
-
Higher availability. The “failure unit” is no longer a host machine, but rather a single disk. Disk failure – the most common hardware failure scenario – does not disable a host.
-
Simpler cluster maintenance. Adding and removing hosts and disks is easy and automatic. Maintenance operations like repair and cleanup are more distributed and parallelized and hence faster.
-
Improved resource utilization. Hosts with more or larger disks can be assigned more vNodes than hosts with fewer or smaller disks, boosting resource utilization across heterogeneous hardware.
That’s a powerful set of benefits. But how do HyperStore vNodes actually work? Let’s look under the hood and see how vNodes work as a mechanism for distributing object replicas across a HyperStore storage cluster.
How vNodes Work
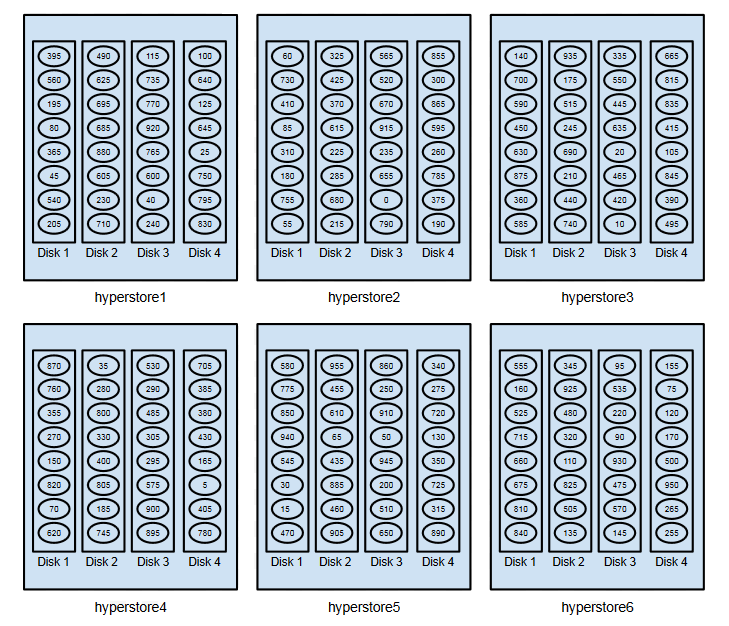
To illustrate vNodes in action, consider a cluster of six HyperStore hosts each of which has four disks designated for object storage. Suppose that each physical host is assigned 32 storage tokens (the default value), with each token constituting a vNode. In a real HyperStore system the token space ranges from 0 to 2127 -1, and individual tokens are typically very long integers. But for illustration, let’s suppose that we have a simplified token space ranging from 0 to 960, and that the values of the 192 tokens in this system (six hosts times 32 tokens each = 192 tokens) are 0, 5, 10, 15, 20, and so on up through 955.
The diagram below shows one possible allocation of tokens (vNodes) across the cluster. Note that each host’s 32 tokens are divided evenly across the four disks – eight tokens per disk – and that token assignment is randomized across the cluster.
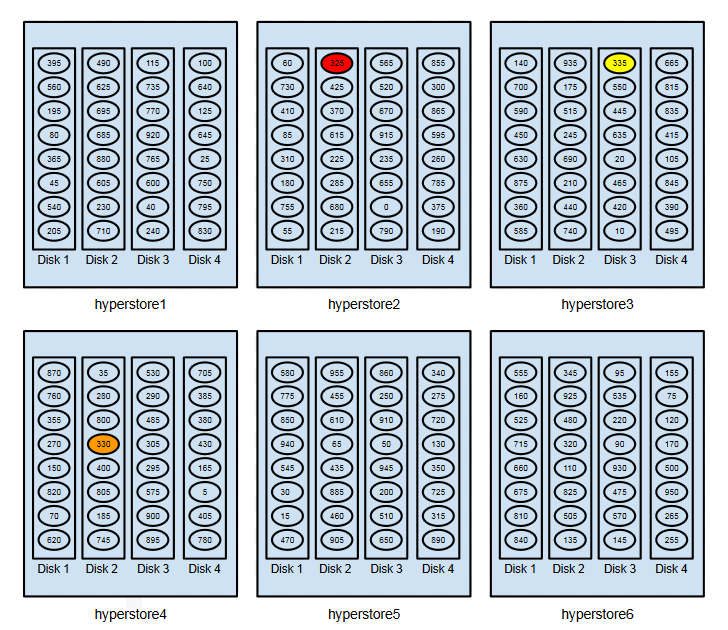
Now further suppose that you’ve configured your HyperStore system for 3X replication of objects. And say that an object is uploaded to the system and the hashing algorithm applied to the object name gives us a hash value of 322 (in this simplified hash space). The diagram below shows how three instances or “replicas” of the object will be stored across the cluster:
-
With its object name hash value of 322, the “primary replica” of the object is stored where the 325 token is — the lowest token value that’s higher than or equal to the object hash value. The 325 token (highlighted in red in the diagram) is assigned to hyperstore2:Disk2, so that’s where the primary replica of the object is stored. Note that the “primary replica” has no functional primacy compared to other replicas; it’s called that only because its placement is based simply on identifying the disk that’s assigned the token range into which the object hash falls.
-
The secondary replica is stored to the disk that’s assigned the next-higher token (330, highlighted in orange), which is hyperstore4:Disk2.
- The tertiary replica is stored to the disk that’s assigned the next-higher token after that (335, in yellow), which is hyperstore3:Disk3.
Note: When the HyperStore erasure coding feature is used, vNodes are the basis for distribution of encoded object fragments rather than entire replicated objects.
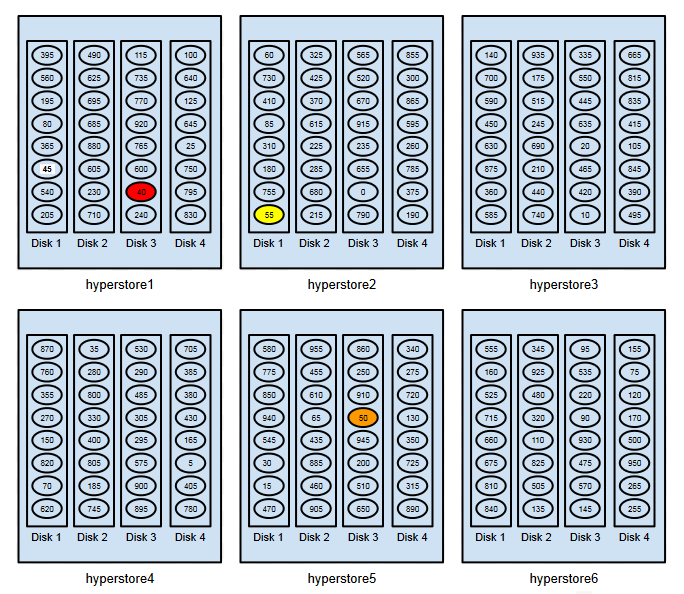
Working with the same cluster and simplified token space, we can next consider a second object replication example that illustrates an important HyperStore vNode principle: no more than one of an object’s replicas will be stored on the same host. Suppose that an object is uploaded to the system and the object name hash is 38. The next diagram shows how the object’s three replicas are placed:
-
The primary replica is stored to the disk where token 40 is — hyperstore1:Disk3 (red highlight).
-
The next-higher token — 45 (with high-contrast label) — is on a different disk (Disk1) on the same host as token 40, where the HyperStore system is placing the primary replica. Because it’s on the same host, the system skips over token 45 and places the object’s secondary replica where token 50 is — hyperstore5:Disk3 (orange highlight).
-
The tertiary replica is placed on hyperstore2:Disk1, where token 55 is (yellow highlight).
The Disk Perspective
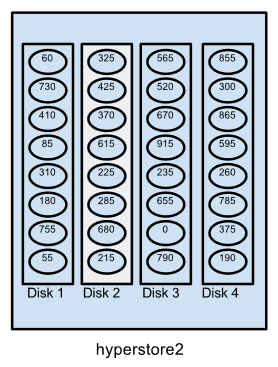
Now let’s change perspective and see how things look for a particular disk from within the cluster. Recall that we’ve supposed a simplified token space with a total of 192 tokens (0, 5, 10, 15, and so on up to 955), randomly distributed across the cluster so that each host has 32 tokens and each host’s tokens are evenly divided among its disks. We can zero in on hyperstore2:Disk2 – highlighted in the diagram below — and see that this disk has been assigned tokens 325, 425, 370, and so on.
Assuming the cluster is configured for 3X replication, on hyperstore2:Disk2 will be stored the following:
-
In association with the disk’s assigned token 325:
-
-
Primary replicas of objects for which the hash values are between 320 (exclusive) and 325 (inclusive)
-
Secondary replicas of objects with hash values between 315 (exclusive) and 320 (inclusive)
-
Tertiary replicas of objects with hash values between 310 (exclusive) and 315 (inclusive)
-
-
In association with the disk’s assigned token 425:
-
-
Primary replicas of objects for which the hash values are between 420 (exclusive) and 425 (inclusive)
-
Secondary replicas of objects with hash values between 415 (exclusive) and 420 (inclusive)
-
Tertiary replicas of objects with hash values between 410 (exclusive) and 415 (inclusive)
-
-
And so on.
And if Disk 2 fails? Disks 1, 3, and 4 will continue fulfilling their storage responsibilities. Meanwhile, objects that are on Disk 2 persist within the cluster because they’ve been replicated on other hosts.
Note: In practice, vNodes can be assigned to any directory, which in turn can correspond to a single disk or to multiple disks (for example, using LVM).
Multi-Data Center Deployments
If you deploy your HyperStore system across multiple data centers within the same service region, your multiple data centers will be integrated in one unified token space.
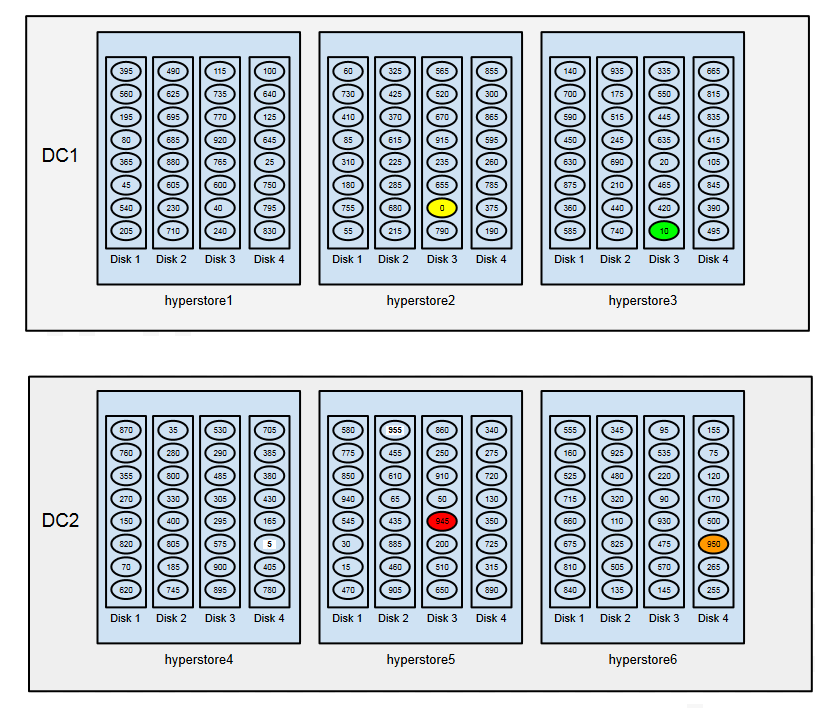
Consider an example of a HyperStore deployment that spans two data centers — DC1 and DC2 — each of which has three physical nodes. As in our previous examples, each physical node has four disks; the default value of 32 tokens (vNodes) per physical host is used; and we’re supposing a simplified token space that ranges from 0 to 960. Suppose also that object replication in this system is configured at two replicas in each data center.
We can then see how a hypothetical object with a hash value of 942 would be replicated across the two data centers:
-
The first replica is stored to vNode 945 (in red in the diagram below) — which is located in DC2, on hyperstore5:Disk3.
-
The second replica is stored to vNode 950 (orange) — DC2, hyperstore6:Disk4.
-
The next-higher vNode (955, with high-contrast label) is in DC2, where we’ve already met the configured replication level of two replicas — so we skip that vNode.
-
The third replica is stored to vNode 0 (yellow) — DC1, hyperstore2:Disk3. Note that after the highest-numbered token (955) the token ring circles around to the lowest token (0).
-
The next-higher vNode (5, high-contrast label) is in DC2, where we’ve already met the configured replication level — so we skip that vNode.
- The fourth and final replica is stored to vNode 10 (green) — DC1, hyperstore3:Disk3.
HyperStore vNodes for Highly Available, Hardware-Optimized Object Storage
For more information about how a vNode-powered HyperStore system can provide your enterprise with highly available object storage that makes optimal use of hardware resources, contact us today.
For more on virtual node technology in Cassandra, see http://www.datastax.com/dev/blog/virtual-nodes-in-cassandra-1-2.