

This blog goes into some of the detail around using Cross Region Replication in a multi-cloud environment.
Cross region replication (CRR) and Single region replication (SRR) are S3 options which allows you to protect data when the latency is too high to use storage policies, or you have a multi-region system, or when you simply want to take advantage of particular functionality it offers.
Note that CRR and CSR are almost identical to Cross System Replication (CSR) in terms of its functionality. The key difference is that CRR has shared authentication where as CSR is completely independent and only available on Cloudian HyperStore.
Here is a quick overview of these replication types.
AWS Cross-region Replication (CRR)
- Data is stored in a bucket that is replicated automatically and asynchronously to a bucket in a different region.
- Since it replicates to a different bucket, you would need to use different URLs to access the files in each bucket.
- CRR uses asynchronous replication between buckets.
AWS Single-region Replication (SRR)
- Uses the CRR feature within a single service region. Objects uploaded into one bucket are replicated to a different bucket in the same service region.
Cross-system Replication (CSR)
- Cloudian-specific feature
- Using CRR with Cross System Replication allows data to be stored in a different and independent system from the source system.
- Data is accessible on DR system in hierarchical structure – as a separate bucket namespace.
A Cloudian systems architecture using CSR looks something like this:
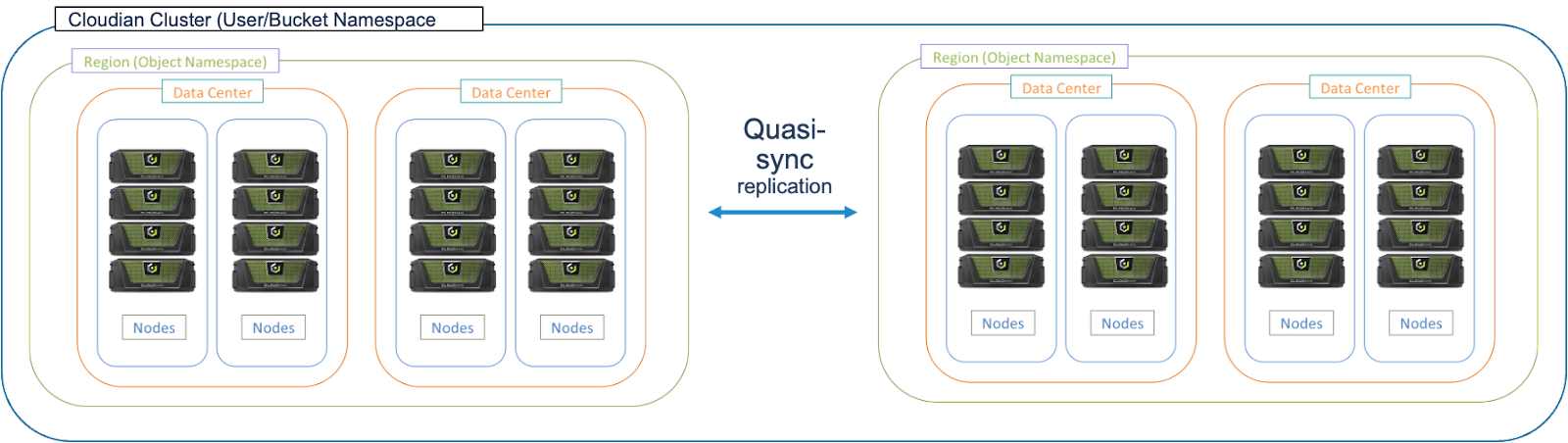
There are some noteworthy limitations/features with CSR:
- With CRR, the data stored in a bucket is replicated automatically and asynchronously to a bucket in a different region. Since it replicates to a different bucket, you need to use different URLs to access the objects in each bucket.
- Both source and destination buckets must have versioning enabled.
- If the source and destination buckets have different owners, the owner of the destination bucket must grant the owner of the source bucket permissions to replicate objects with a bucket policy.
- Objects that existed before you added the replication configuration to the bucket will not be replicated. In other words, Amazon S3 doesn’t replicate objects retroactively.
CRR is enabled at bucket-level granularity, which means that you must apply the replication rule to the bucket. In a bidirectional configuration, each bucket within each region acts as a source and a destination. NOTE: Bidirectional replication is only supported in CRR not with CSR
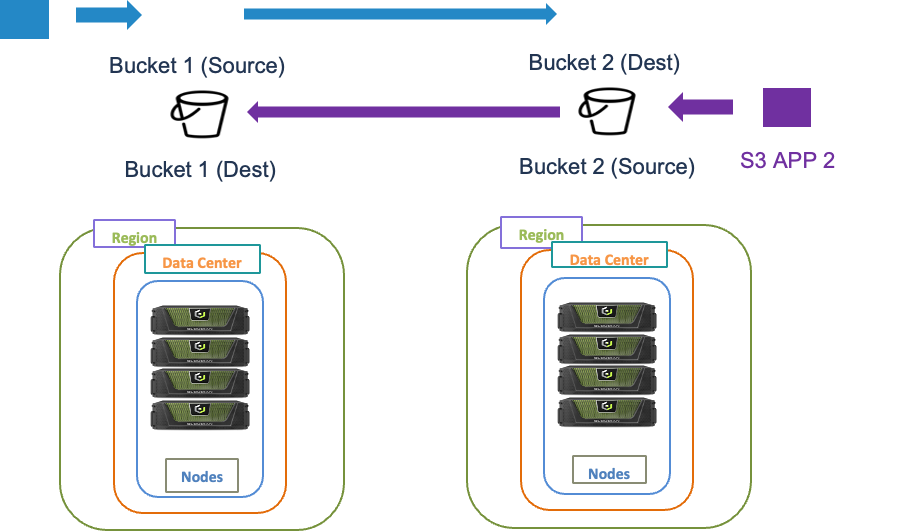
It is also very important to understand what is not replicated:
- Objects already in the source bucket before the bucket was configured for cross-region replication. Any preexisting content within a bucket is not automatically replicated after CRR is enabled. Only objects that are created from that point forward are replicated.
- Objects that are encrypted with user-managed encryption keys (SSE-C) or AWS KMS managed encryption keys
- Objects that are themselves replicas from other source buckets.
- Deletions of specific object versions. Delete requests for specific object versions are only deleted from the source. Requests to delete non-specific object versions will replicate the deletion marker to the destination bucket.
In conclusion, CRR/SRR/CSR are very powerful data protection tools but are not the ideal solution for protecting data in every scenario. In a lot of cases, replicated or distributed storage policies (as mentioned in my previous blogs) can offer similar functionality with less management overhead. But there are times when CRR/SRR/CSR is the only solution.

David Axler, Principle Architect