

As discussed in my previous blog post, ‘An Introduction to Data Tiering’, there is huge value in using different storage tiers within a data storage architecture to ensure that your different data sets are stored on the appropriate technology. Now I’d like to explain how the Cloudian HyperStore system supports object storage ‘auto-tiering’, whereby objects can be automatically moved from local HyperStore storage to a destination storage system on a predefined schedule based upon data lifecycle policies.
Cloudian HyperStore can be integrated with any of the following destination cloud storage platforms as a target for tiered data:
- Amazon S3
- Amazon Glacier
- Google Cloud Platform
- Any Cloud service offering S3 API connectivity
- A remotely located Cloudian HyperStore cluster
Granular Control with Cloudian HyperStore
For any data storage system, granularity of control and management is extremely important – data sets often have varying management requirements with the need to apply different Service Level Agreements (SLAs) as appropriate to the value of the data to an organisation.
Cloudian HyperStore provides the ability to manage data at the bucket level, providing flexibility at a granular level to allow SLA and management control (note: a “bucket” is an S3 data container, similar to a LUN in block storage or a file system in NAS systems). HyperStore provides the following as control parameters at the bucket level:
- Data protection – Select from replication or erasure coding of data, plus single or multi-site data distribution
- Consistency level – Control of replication techniques (synchronous vs asynchronous)
- Access permissions – User and group control access to data
- Disaster recovery – Data replication to public cloud
- Encryption – Data at rest protection for security compliance
- Compression – Reduction of the effective raw storage used to store data objects
- Data size threshold – Variable storage location of data based upon the data object size
- Lifecycle policies – Data management rules for tiering and data expiration
Cloudian HyperStore manages data tiering via lifecycle policies as can be seen in the image below:
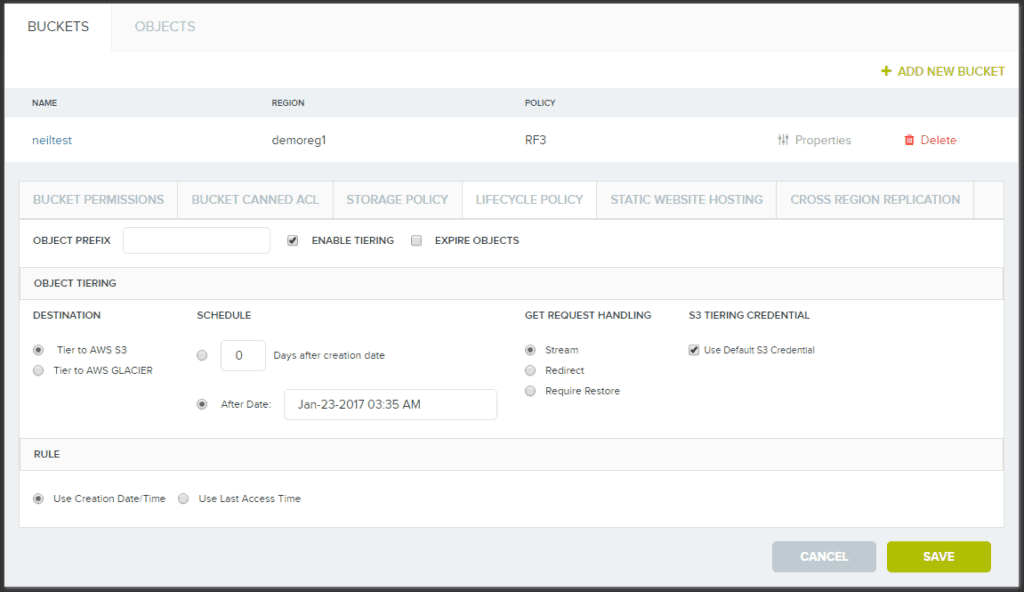
Auto-tiering is configurable on a per-bucket basis, with each bucket allowed different lifecycle policies based upon rules. Examples of these include:
- Which data objects to apply the lifecycle rule to. This can include:
- All objects in the bucket
- Objects for which the name starts with a specific prefix (such as prefix “Meetings/2015/”)
- The tiering schedule, which can be specified using one of three methods:
- Move objects X number of days after they’re created
- Move objects if they go X number of days without being accessed
- Move objects on a fixed date — such as December 31, 2016
When a data object becomes a candidate for tiering, a small stub object is retained on the HyperStore cluster. The stub acts as a pointer to the actual data object, so the data object still appears as if it’s stored in the local cluster. To the end user, there is no change to the action of accessing data, but the object does display a special icon denoting the fact that the data object has been moved.
For auto-tiering to a Cloud provider such as Amazon or Google, an account is required along with associated account access credentials.
Accessing Data After Auto-Tiering
To access objects after they’ve been auto-tiered to public cloud services, the objects can be accessed either directly through a public cloud platform (using the applicable account and credentials) or via the local HyperStore system. There are three options for retrieving tiered data:
- Restoring objects – When a user accesses a data file, they are directed to the local stub file held on HyperStore which then redirects the user request to the actual location of the data object (tiered target platform).
A copy of the data object is restored back to a local HyperStore bucket from the tiered storage and the user request will be performed on the data object once copied back. A time limit can be set for how long to retain the retrieved object locally, before returning to the secondary tier.
This is considered the best option to use when accessing data relatively frequently and you want to avoid any performance impact incurred by traversing the internet and any access costs applied by service providers for data access/retrieval. Storage capacity must be managed on the local HyperStore cluster to ensure that there is sufficient “cache” for object retrievals.
- Streaming objects – Streams data directly to the client without restoring the data to the local HyperStore cluster first. When the file is closed, any modifications are made to the object in situ on the tiered location. Any metadata modifications will be updated in both local HyperStore database and on the tiered platform.
This is considered the best option to use when accessing data relatively infrequently and concern about the storage capacity of the local HyperStore cluster is an issue, but performance will be lower as the data requests are traversing the internet and access costs may be applied by the service provider every time this file is read.
- Direct access – Objects auto-tiered to public cloud services can be accessed directly by another application or via your standard public cloud interface, such as the AWS Management Console. This method fully bypasses the HyperStore cluster. Because objects are written to the cloud using the standard S3 API, and include a copy of the object’s metadata, they can be referenced directly.
Storing objects in this openly accessible manner — with co-located rich metadata — is useful in several instances:
- A disaster recovery scenario where the HyperStore cluster is not available
- Facilitating data migration to another platform
- Enabling access from a separate cloud-based application, such as content distribution
- Providing open access to data, without reliance on a separate database to provide indexing
HyperStore provides great flexibility for leveraging hybrid cloud deployments where you get to set the policy on which data is stored in a public or private cloud. Learn more about HyperStore here.
YOU MAY ALSO BE INTERESTED IN