

In the evolving landscape of enterprise storage, the distinction between scale-up and scale-out storage architectures remains a focal point. As organizations face exponential data growth, understanding the nuances of these architectures is crucial for efficient storage management and expansion.
Storage capacity is the primary benchmark for evaluating storage devices, closely followed by the ease of capacity expansion. The urgency of scaling is a critical concern for storage administrators, often requiring a choice between adding hardware to an existing system or architecting a more complex solution such as a new data center. The former, known as scale-up, and the latter, scale-out, are differentiated by their inherent architectural designs.
The Traditional Scale-Up Model
Scale-up storage has been the traditional approach. It typically involves a central pair of controllers overseeing multiple shelves of drives. Expansion is linear and limited; when space runs out, additional shelves of drives are integrated. The limitation of this model lies in the finite scalability of the storage controllers themselves.
As storage demands increase, the scale-up model encounters bottlenecks. New systems must be introduced to manage additional data, leading to increased complexity and isolated storage silos. This architecture also struggles with resource allocation inefficiency, as determining the optimal location for workloads becomes increasingly challenging.
RAID technology underpins drive failure protection in scale-up systems. However, RAID does not extend across multiple storage controllers, anchoring the drives to a specific controller and consequently cementing the scalability challenge of this architecture.
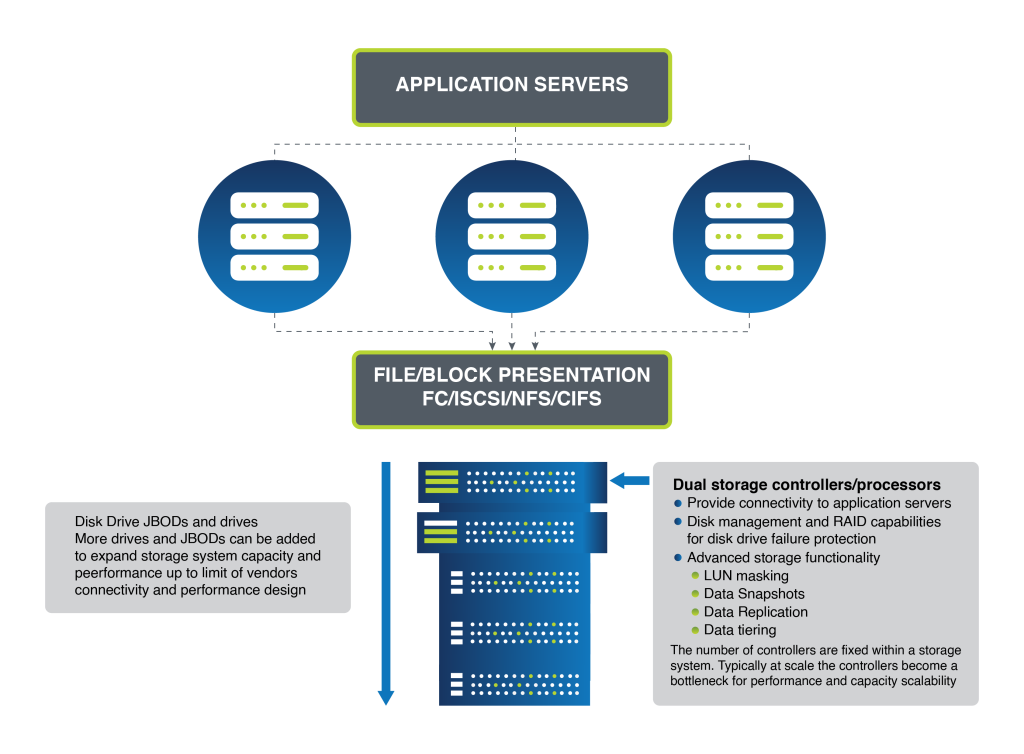
Figure 1 – Modular/Scale-up Storage Architecture
As an organization’s data volume grows, completely new systems need to be added to cope with the additional demands. Ultimately, this architecture becomes highly complex to manage. Inefficient resource allocation becomes an issue in deciding where workloads need to reside.
Figure 2 shows the potential for storage system sprawl.
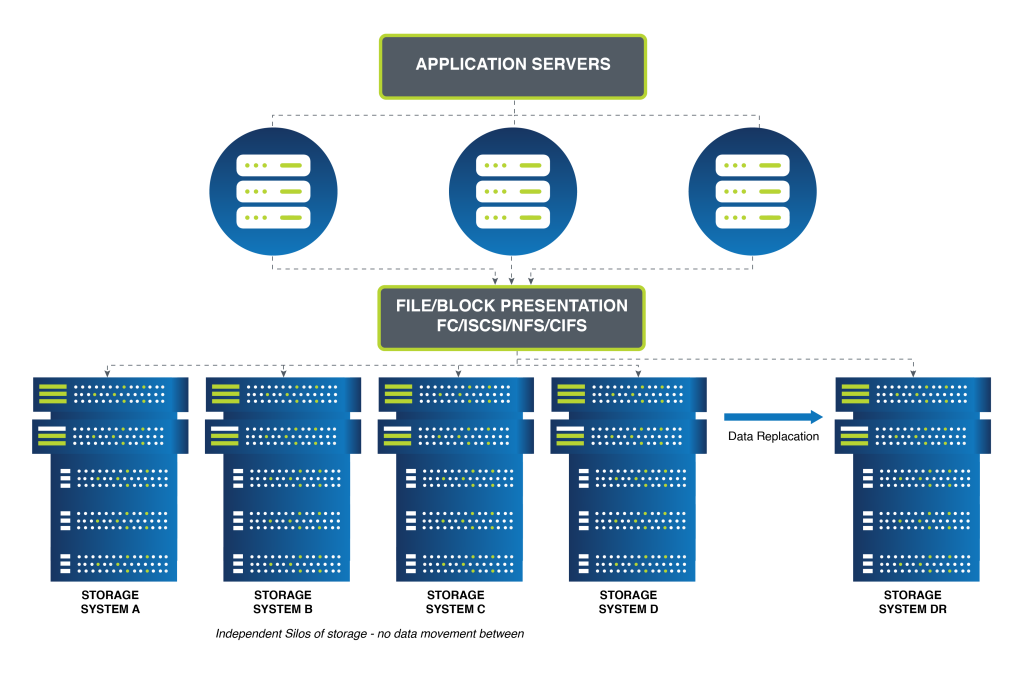
Figure 2 – Modular/Scale-up Storage Silos
The Modern Scale-Out Strategy
In contrast, scale-out storage architectures, particularly those utilizing object storage, offer a dynamic alternative. Constructed with industry-standard servers, storage is linked to each node, reminiscent of Direct Attached Storage (DAS). Object storage software on each node unifies the nodes into a single cluster, creating a pooled storage resource with a unified namespace accessible to users and applications.
Protection against drive failure in a scale-out environment is not reliant on RAID but on RAIN (Redundant Array of Independent Nodes), which offers data resilience across nodes. RAIN supports several data protection methods, including replicas and erasure coding, which mirror RAID’s data safeguarding principles but are optimized for multi-node environments.
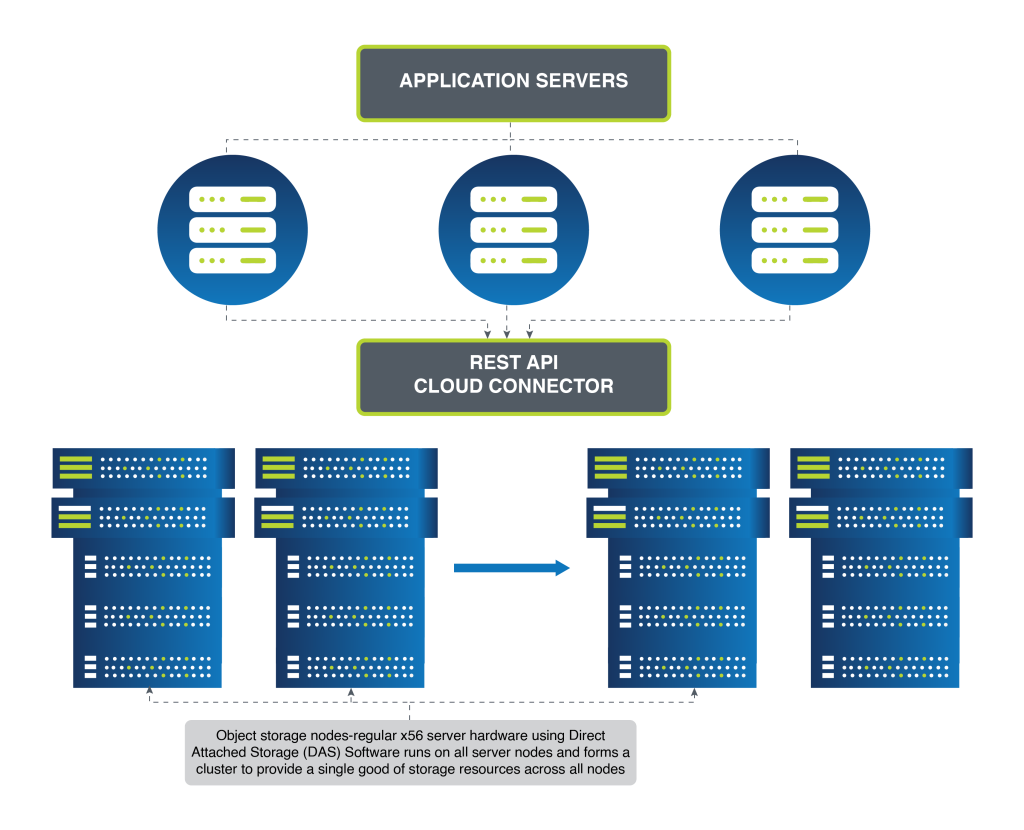
Figure 3 – Object/Scale-out Storage Architecture
Scale-Out with Cloudian HyperStore
Cloudian HyperStore exemplifies the scale-out storage solution. HyperStore utilizes object storage technology to enable seamless scalability, providing a storage platform that expands horizontally by adding nodes. Each node addition enhances storage capacity, as well as compute and networking capabilities, ensuring that performance scales with capacity.
HyperStore’s architecture allows for simple integration of new nodes, which the system then incorporates into the existing cluster. Data is intelligently distributed across the new configuration, maintaining performance and reliability without the limitations of traditional scale-up architectures.
In a multi-data center setup, Cloudian HyperStore’s geo-distributed capabilities shine. Nodes can be deployed across various geographical locations, and thanks to HyperStore’s geo-awareness, data can be strategically placed to optimize access speeds. Users access storage through a virtual address, with the system directing requests to the closest or most optimal node. This ensures fast response times and consistent data availability, irrespective of the user’s location.
HyperStore’s innovative approach not only addresses the immediate scalability challenges but also provides a future-proof solution that accommodates the ever-increasing volume and complexity of enterprise data. Its efficient use of resources, simplified management, and robust data protection mechanisms make it a compelling choice for enterprises looking to overcome the traditional hurdles of storage expansion.
In summary, the evolution from scale-up to scale-out storage, epitomized by solutions like Cloudian HyperStore, marks a significant transition in enterprise storage. Organizations can now address their data growth challenges more effectively, with architectures designed for the demands of modern data management.
For more information, watch our overview on object storage or read the Object Storage Buyer’s Guide.
You may also be interested in:
Using Storage Archives to Secure Data and Reduce Costs