

Strata Data Conference is always a great place to geek out on the data techniques and technologies that are fueling our future. As a product manager, it gives me a chance to meet and brainstorm with researchers, data scientists, executives and business thought leaders from around the world.
One of the themes for breakout sessions this year was how some organizations have evolved their AI and machine learning infrastructure to decouple storage and compute. The goal is to reach production readiness at scale and enhance engineering productivity. For this, S3-compatible storage, on-prem, offers a compelling solution.
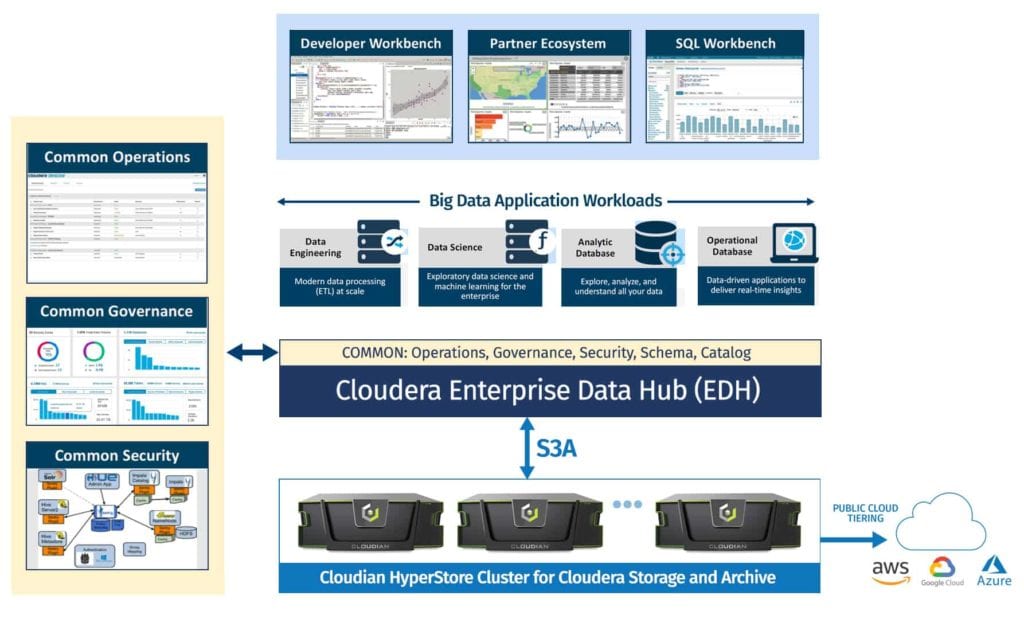
Solving the Big Data Storage Challenge
As Big Data organizations scale beyond the petabyte range with Hadoop, economics related to storing and archiving has become a major concern for them. Inability to scale storage nodes independent of compute in HDFS leads to unnecessary resource cost. This is especially true for “warm” data that only uses storage and consumes few compute resources.
As the data storage requirements grow, the need to evolve the data infrastructure for a these workloads grows with it. These reasons may vary from meeting the need for scale, performance, cost, or regulatory compliance.
Be it a ride sharing company storing 100+PBs of analytical data, or an autonomous vehicle company storing and analyzing massive amounts of simulation data, much of this data still ends up in the public cloud after all the post-processing is done. This increases operational and capital cost of the overall solution.
5 Reasons Why On-Prem S3-Compatible Storage Helps
Here are 5 ways in which a big data lake built with on-prem S3 compatible storage can help to achieve public cloud scalability at far less cost than cloud:
- Scalability– On-prem solutions work on the same hierarchical concepts as AWS. A cluster consists of regions, data centers, and nodes within them. As your storage requirements grow from terabytes to multi-petabytes, you can simply add new nodes, new data centers, or even new regions to expand geographically. A cluster can scale limitlessly within a single namespace eliminating management workload and complexity through a unified view of data.
- Fully Native S3 – Applications that work with S3 in the cloud will just as easily support S3 in your data center. Data is accessed via an S3 restful API, the de-facto standard language of cloud storage. The use of the S3 API as a simple standard interface enables engineering teams to easily interact with the data without making any changes to their existing S3 applications and services. Moreover, this enables easy access to a data lake on Cloudera via an S3A connector.
- Software-defined – Depending upon the way your data center is architected, you might benefit from the pre-configured appliance or use purpose-built servers already present in your data centers. S3-compatible storage gives you choice with software-defined storage and appliance options. It can even be deployed on bare metal instances on public clouds to leverage cloud-native tools for your AI/ML workflows.
- Data durability – Different data types have varying data protection requirements depending upon the criticality of the data. Log files might not need the same level of protection as the sensor data or simulation data from autonomous cars. Making multiple copies of the multi-petabyte data is not always feasible and could be time and cost prohibitive. Unlike AWS S3 where every object has 3 copies, bucket level storage policy on S3-compatible storage allows you to define the protection level to optimize your storage efficiency and improved read/write performance. In some cases this also helps to host multiple tenants and to provide services with different SLAs and QoS settings. With these flexible storage policies, Cloudian cluster can be configured to tolerate multiple node failures, or even the loss of an entire data center in case of a disaster.
- Cloud integration – Multi-cloud interoperability lets you enable tiering to AWS, GCP, and Microsoft Azure. S3-compatible storage lets you view local and cloud-based data within a single namespace. Data stored on any of these cloud platforms from HyperStore is directly accessible by cloud-based applications. This bi-modal access lets you employ both cloud and on-prem resources interchangeably.
Cloudian is a leader in on-prem S3-compatible storage. With systems that span from 100TB to an Exabyte, Cloudian HyperStore is proven in Big Data environments.
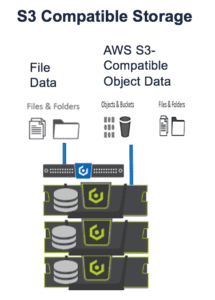
Cloudian HyperStore offers a rich set of features including quality of service controls, multi-tenancy, billing, server-side encryption, WORM compliance, cross-region replication (CRR) for your applications and workloads. Feel free to reach out in case you wish to learn more about Cloudian and its products.
Or visit cloudian.com to learn more.