

Reading Brendan Burns’ The History of Kubernetes & the Community Behind It, I was struck by the common technical foundations of Kubernetes and object storage. Burns lists Kubernetes’ “basic feature set” as an orchestrator to deploy and manage containers as:
- Replication to deploy multiple instances of an application
- Load balancing and service discovery to route traffic to these replicated containers
- Basic health checking and repair to ensure a self-healing system
- Scheduling to group many machines into a single pool and distribute work to them
For modern object storage systems like Cloudian HyperStore, the foundational feature set is:
- Distributed and replicated services and data for availability and durability
- Scale-out capacity across multiple locations
- Fault tolerance and self-healing
- A single, global namespace to address data via a REST API
Though somewhat different in scope and focus, these four technical foundations of Kubernetes and object storage overlap to a large extent. There are other features for both, such as multi-tenancy to organize users, that are not reflected, but mapping these four listed features show the striking similarities:
| FEATURE | KUBERNETES | OBJECT STORAGE |
|---|---|---|
| Availability, durability | Pod replication strategies as deployments, stateful sets, services. This ensures service availability and data durability in case of temporary failures. | Distributed and replicated services and data to ensure service availability. Replication and erasure coding (EC) methods for data to ensure data durability in case of partial and/or temporary failures. |
| Load-balancing, routing | The Service resource defines a logical set of Pods and a policy to access them. DNS is used for resolving Services by their DNS name. Example: a Service my-service in a namespace my-ns has a DNS record for my-service.my-ns. A Pod can do a DNS name lookup for my-service. | Scale-out, elastic capacity across multiple locations (e.g., geographic zones) is networked together. DNS is used for resolving data location by their DNS name. Example: S3 uses a virtual-hosted-style URI where the S3 bucket name is part of the domain name in the format |
| Self-healing | Controllers are control loops that reconcile the actual state of the cluster to the desired state. An obvious case is ensuring the spec number of Pods of a Deployment matches the actual number of Pods, and if not, then starting a new Pod. | Object data can be missing or out-of-date in a particular replica or EC fragment due to temporary failures when writing or new disk or node failures. In these cases, automatic data “repair” using the other replicas or EC fragments is done to restore full data integrity. |
| Distribute work across a single resource pool | The Kubernetes scheduler places a Pod on the best Node based on resource requirements and explicit labels. Dynamic configuration changes can cause rescheduling of the Pod to a different Node. | Buckets and objects are addressable in a single, global namespace. This contrasts from many file-based storage systems where data is partitioned in silos. Data API requests can be made to any load-balanced server. |
One more important similarity is the primacy of the declarative API of both Kubernetes and object storage.
| FEATURE | KUBERNETES | OBJECT STORAGE |
|---|---|---|
| Declarative API | Resources are declarative, described in explicit YAML specifications. In particular, a “spec” defines what a resource should be, and it is up to Kubernetes to implement. | Amazon’s S3 API is the standard object storage API. App developers can reliably use the S3 API at both Amazon and other S3-compatible object storage systems without regard to the implementation underlying the S3 API. |
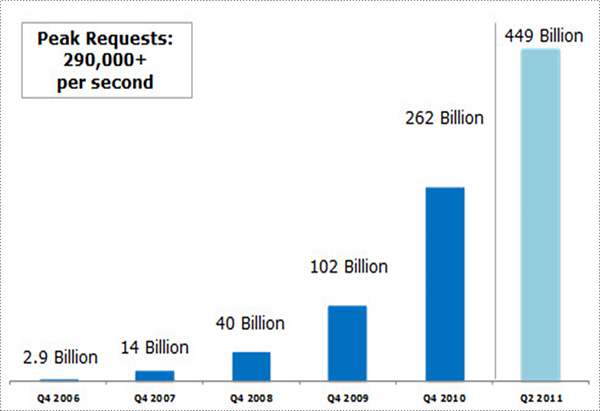
A possible reason for these similar foundations is that Kubernetes and distributed data stores underlying object stores rapidly developed in the same time period around 2010 to address the needs of new use cases Around that time, new apps and services started requiring massive data stores and cloud-native deployment and management. Examples include always-connected mobile devices, deep learning and map-reduce analyses, and social media apps like Instagram. Jeff Barr’s post from 2011 showed Amazon S3’s exponential growth of stored objects around that time:
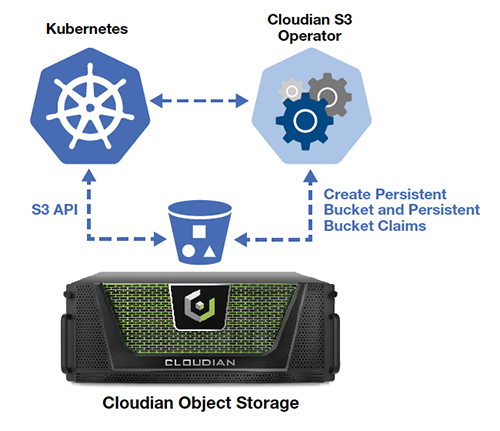
Given the common technical foundations, there is a natural fit when incorporating object storage software to Kubernetes. The Kubernetes control plane can manage distributed object storage Pods in a standard way, especially in regards to failure handling and resilience. With an object store’s single, global pool of data, Kubernetes apps can directly use the S3 API to address data at any location or execution status. For example, machine learning training can exploit training data stored in an object store, and streaming apps can write and process data utilizing storage policies with different data distribution and consistency levels. From the app developer’s perspective, the goal is always how to make it easier to build apps — e.g., build apps faster. Kubernetes plus object storage makes this goal more achievable.
As a side note, Kubernetes added the Container Storage Interface (CSI) as a standard for exposing arbitrary block and file storage systems. Block and file storage systems can implement a CSI driver, and then apps can use standard Kubernetes resources (PersistentVolumeClaims (PVCs), PersistentVolumes (PVs), and StorageClasses) to access that storage. For example, a PVC can be dynamically created with a specific StorageClass that represents an external block storage system. There is promising, ongoing development of a similar standard for object storage (Container Object Storage Interface) that would make object storage even more consumable by Kubernetes workloads.
Learn more about Kubernetes and Object Storage
Cloudian Storage for Kubernetes Solution
![]()
ANALYST REPORT
How Private Cloud Overcomes the Top 5 Kubernetes Storage Challenges
![]()
ON-DEMAND WEBINAR
Data Protection for Kubernetes