

Guest Blog Post by George Crump
Hadoop, first used by large cloud providers like Yahoo, Facebook and Google, is designed to allow massive amounts of compute resources to process very large, unstructured datasets. The technology is now firmly entrenched in government agencies and is now working its way into more traditional enterprise IT. The goal of a Hadoop project is to improve decision making by providing rapid and accurate answers. The larger the data set the more accurate those answers. The more servers that can be applied to that task the faster those decisions can be made.
What is Hadoop?
 Hadoop was created as an open source software solution to enable organizations to do this kind of massive scale processing across a very large data set. The standard Hadoop architecture has four components. The two most obvious components are the compute component and the storage component. On the compute component of the Hadoop process, called MapReduce, this is an algorithmic approach to processing a large data set and trying to “reduce” it to a smaller more manageable data set from which users can then draw conclusions.
Hadoop was created as an open source software solution to enable organizations to do this kind of massive scale processing across a very large data set. The standard Hadoop architecture has four components. The two most obvious components are the compute component and the storage component. On the compute component of the Hadoop process, called MapReduce, this is an algorithmic approach to processing a large data set and trying to “reduce” it to a smaller more manageable data set from which users can then draw conclusions.
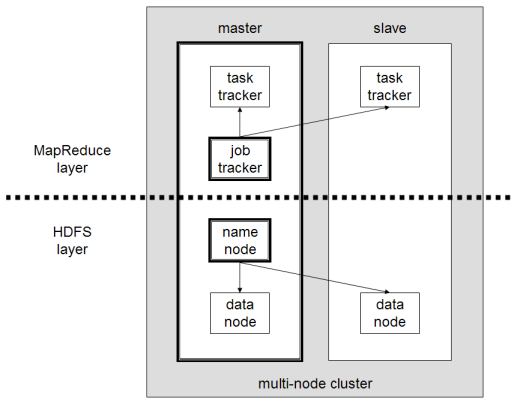
One of the basic tenets of Hadoop is to take the compute to where the data is. Typically there is so much data to be processed that it would be inefficient to move the data over a network to a compute node. To accomplish this Hadoop uses the Hadoop Distributed File System (HDFS), which allows data to be partitioned across nodes in a cluster. Each of these “slave” nodes will run their own MapReduce function as well as store parts of the total data set to be processed.
Hadoop uses a master node as a job tracker to parse out all the required data processing tasks to the slave Hadoop nodes in the Hadoop cluster. It makes sure that each slave node runs the right MapReduce function for the data that it is currently storing. This allows processing of the data to occur locally. The results from each slave node are then funneled up to the master for analysis and conclusion.
The Storage Challenges with Hadoop
There are three key challenges that Hadoop creates for traditional enterprises looking to implement it. The first is capacity inefficiency. To protect data, HDFS as a default makes three copies of the dataset, so that if a node or its drive fails, data is still accessible on other nodes. The 3X requirement is particularly significant in the Hadoop use case because these are typically very large data sets. Multiple Petabytes (PB) are not uncommon. Imagine if your core data set is 3PB, that means you will need to have enough capacity to store at least 9PBs of information. Cost of capacity can be a big concern when designing a Hadoop design.
The second challenge is … [to keep reading, click HERE]