

Splunk is a distributed system that collects and logs huge amounts of data, and storage costs can be prohibitive. Some companies opt for low-cost storage options like object storage to store Splunk data. Unfortunately, Splunk does not offer a storage calculator that can help you estimate your costs. We’ll help you understand how Splunk architecture stores data in warm, cold and frozen storage tiers, the storage requirements for each tier, and give you a step-by-step guide to estimate your storage costs on your own.
In this article you will learn:
Is There a Splunk Storage Calculator?
Although there is no official Splunk storage calculator, there are techniques you can use to estimate storage requirements yourself. All you need is an understanding of Splunk data and storage tiers and the ability to use CLI commands. For example, if you’re running Linux, you can see the total storage your Splunk index is using with du -ch hot_v*.
You can see full instructions for estimating Splunk storage requirements below. Or, you can read on to understand the Slunk storage mechanism in more detail.
How Splunk Stores Data
In Splunk, you store data in indexes made up of buckets of files. Buckets contain data structures that enable Splunk to determine if the data contains terms or words. Buckets also contain compressed, raw data. This data is typically reduced to 15% of its original size, once compressed, to help Splunk store data efficiently.
Bucket storage can contain a significant amount of data but the largest storage consumption from Splunk comes from metadata. Around 35% of the original size of data stored is searchable metadata which Splunk uses to determine how to return search results.
Combined, Splunk stores data at around a 50% reduction in size from the original. This is before replication. This amount is just a baseline, however, since data compresses differently by type. If you are unsure how to anticipate your storage needs, a 50% size estimate is a good place to start.
Storage Tiering in Splunk
Splunk uses storage tiering to organize data. In Splunk, buckets are tiered according to a lifecycle policy, which is based on the state of the bucket. A bucket is in a hot state when you are actively writing data to it. Once you are no longer writing data because a bucket is full, Splunk is restarted, or you close the bucket, it is moved to a warm state.
As you run out of volume space or accumulate too many warm buckets, older buckets move to a cold state. When you run out of cold storage or a bucket gets too old, it is moved to a frozen state and will be deleted unless you change the default setting. The hot / warm / cold / frozen states enable you to tune your storage to maximize cost and efficiency of storage space.
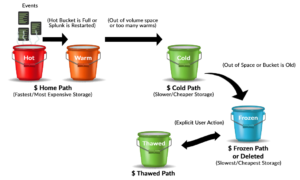
Source: Hurricane Labs
Warm Storage
Both hot and warm buckets are kept in warm storage. This storage is the only place that new data is written. Warm storage is your fastest storage and requires at least 800 input/output operations per second (IOPS) to function properly. If possible, this storage should use non-volatile memory express (NVMe) drivers and SSD to ensure performance. NVMe is designed specifically for SSD and can provide significantly higher performance than other interfaces.
If you are not able to use SSD, you will likely need to deploy a redundant array of independent disks (RAID) 10 configuration. RAID 10 operates 10 drives in parallel to achieve higher performance with lower quality hardware. Alternatively, you can use a storage area network (SAN). However, you should not use shared storage in a network file system (NFS). Be sure to protect warm data buckets using a Splunk backup strategy.
Cold Storage
Cold data storage is your second actual storage tier and is the lowest searchable tier. Cold storage is useful when you need storage to be immediately available but don’t need high performance. For example, to meet PCI compliance requirements. Cold data storage is more cost-effective than warm since you can use lower quality hardware.
Keep in mind, if you are using one large storage pool for your tiers, cold storage is a name only. Buckets still roll to cold but your performance doesn’t change.
Frozen Storage
Your lowest storage tier is frozen storage. It is primarily used for compliance or legal reasons which demand you store data for longer periods of time. By default, Splunk deletes data rather than rolling it to frozen storage. However, you can override this behavior by specifying a frozen storage location
Frozen storage is not searchable, so you can store it at a significant size reduction, typically 15% of the original. This is because Splunk deletes the metadata associated with it.
Read more in our blog about object storage.
Estimate Your Splunk Storage Requirements: A Step-by-Step Guide
When data is indexed in Splunk, a “rawdata” file with the original compressed data and an index file are stored. The ratio between these files is fairly standard and you can base future storage needs on previous use.
Typically, index files are somewhere between 10% and 110% of your “rawdata” files. The easiest way to determine the percentage you should expect is to index a representative sample of your data.
Since there’s no Splunk storage calculator, we’re going to need to use a manual process. The steps below can guide you through the basic process of estimating your Splunk storage requirements.
For Unix and Linux systems, follow these steps to evaluate your sample:
After you’ve indexed your data sample:
- Go to $SPLUNK_HOME/var/lib/splunk/defaultdb/db.
- Run du -ch hot_v* and check the size of your index on the last total line.
For Windows systems, follow these steps
- Use this link to download the Microsoft TechNet DU utility.
- From the ZIP file, extract du.exe and place it in %SYSTEMROOT%, %WINDIR%, or %PATH%.
- From your command prompt, go to %SPLUNK_HOME%\var\lib\splunk\defaultdb\db.
- Run del %TEMP%\du.txt & for /d %i in (hot_v*) do du -q -u %i\rawdata | findstr /b “Size:” >> %TEMP%\du.txt.
- Open the %TEMP%\du.txt file. Size: {number} is the size of each rawdata directory found.
- You can then add these numbers together to find out how large your compressed raw data is.
- Next, run for /d %i in (hot_v*) do dir /s %i to find out your index size.
- To get your total size, add the index size to your rawdata directory size.
Splunk Storage Calculation Example
Consider a Splunk deployment with a data ingest of 10gb/day, on a single server with no replication. This requires the following storage capacity:
10gb/day * .15 (raw data) = 1.5gb/day
10gb/day * .35 ( metadata) = 3.5gb/day
Total = 5gb/day
Assuming you keep all data in warm or cold storage, the total storage capacity is a function of the number of days.
For 90 days data retention: 5gb * 90 days = 450gb
For 1 year retention: 5gb * 365 days = 1825gb
Factors Impacting Storage Requirements
Splunk storage is impacted by your data retention periods and your daily data ingestion rate. These determine most of your Splunk storage needs.
Daily Ingestion Rate
Daily ingestion rate is simply how much raw data Splunk is consuming daily. Typically, you can use your licensed capacity for this amount. In most cases, you should not exceed your license.
There are volume discounts available for larger license sizes that you can take advantage of. These discounts reduce the cost per GB per day. These licenses can also be useful if you anticipate your needs growing.
Retention Period
Retention period refers to how long your data is stored in Splunk. This period is often restricted by compliance standards. It is also affected by your intended use of data. For example, if you are using Splunk IT Service Intelligence (ITSI) or Splunk Enterprise Security Suite (ES), you need to run constant searches over small data sets. This means a longer retention period in warm storage.
In general, you should use retention periods to ensure that your data is optimized on the correct tier as much as possible. If you’re managing big data with Splunk, check out this article about Splunk big data options.
Read more in our guides to splunk big data and splunk data model.
Reduce the Cost of Splunk Storage and Increase Scalability with Cloudian HyperStore
If you are managing large volumes of data in Splunk, you can use Splunk SmartStore and Cloudian HyperStore to create an on-prem storage pool. The storage pool is separate from Splunk indexers, and is scalable for huge data stores that reach exabytes. Here’s what you get when you combine Splunk and Cloudian:
-
- Control—Growth is modular, and you can independently scale resources according to present needs.
- Security—Cloudian HyperStore supports AES-256 server-side encryption for data at rest and SSL for data in transit (HTTPS). Cloudian also protects your data with fine-grained storage policies, secure shell, integrated firewall and RBAC/IAM access controls.
- Multi-tenancy—Cloudian HyperStore is a multi-tenant storage system that isolates storage using local and remote authentication methods. Admins can leverage granular access control and audit logging to manage the operation, and even control quality of service (QoS).
You can find more information about the cooperation between Splunk and Cloudian here.