

Splunk is a popular platform for big data collection and analytics, often used to derive insights from huge volumes of machine data. There are two primary ways to use Splunk architecture for data analytics:
- Splunk Enterprise can collect log data from across the enterprise and make it available for analysis
- Splunk Hunk is a new way to index and query Hadoop data, easily creating dashboards and reports directly from Hadoop datasets
In this article we focus on the second method, explaining how Hunk can help you make sense of legacy Hadoop datasets.
In this article you will learn:
- What is Splunk
- Using Splunk for machine data analytics
- Introduction to Splunk Hunk
- Splunk Hunk key capabilities
- Should you use Hunk or Splunk Enterprise?
- Low-cost storage for Splunk Hunk and Splunk Enterprise with Cloudian
This is part of a series of articles about Splunk Architecture.
What is Splunk?
Splunk is an innovative technology which searches and indexes log files and helps organizations derive insights from the data. A main benefit of Splunk is that it uses indexes to store data, and so does not require a separate database to store its information.
Splunk is used for monitoring and searching through big data. It indexes and correlates information in a container that makes it searchable, and makes it possible to generate alerts, reports and visualizations. It can recognize data patterns, create metrics and help diagnose problems, for business challenges like IT management, data security and compliance.
Using Splunk for Machine Data Analytics
Splunk helps organizations extract value from server data. This enables efficient application management, IT operations management, compliance and security monitoring.
At the center of Splunk is an engine that collects, indexes and manages big data. It can handle terabytes of data or more in any format every day. Splunk analyzes data dynamically, creating schemas on the fly, allowing organizations to query data without having to understand the data structure first. It’s simply possible to pour data into Splunk and immediately begin analysis.
Splunk can be deployed on a single laptop or in a massive, distributed architecture in an enterprise data center. It provides a machine data fabric, including forwarders, indexers and search heads (see our article on Splunk architecture) that enables real-time collection and indexing of machine data from any network, data center or IT environment.
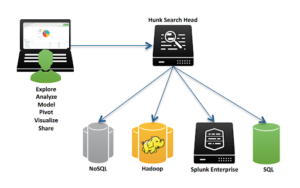
Introduction to Splunk Hunk: Splunk on Hadoop
Hunk is an alternative to Splunk Enterprise, provided and supported by Splunk, for analyzing machine data stored in Hadoop. In the past, many organizations saved machine data in Hadoop because it was the go-to tool for storing and analyzing very big data. Today, as the Hadoop ecosystem ages, organizations are struggling with its limitations.
Source: Splunk
{kind=link}
Hunk is a Splunk big data solution designed to explore and visualize data in Hadoop clusters and NoSQL databases like Apache Cassandra. Instead of writing code in Hadoop for every data-related question you need to ask, Hunk provides an integrated experience that does not require special skills, and can help you extract insights from big data without specialized schemas or a major development effort.
Hunk can help organizations make more of Hadoop datasets by:
- Bringing the Splunk technology stack to Hadoop, letting you create dashboards and share reports using one platform that works with Hadoop on the back-end.
- Creating a Splunk Virtual Index that helps separate Hadoop data storage from data access and analytics, to enable interactive exploration and analysis that is not traditionally possible with Hadoop.
- Making it as easy to develop applications leveraging Hadoop big data. Hunk provides a web framework that lets developers access Hunk using familiar tools like XML, JavaScript and Python/Django.
- Providing the Splunk Search Processing Language, just like in the Splunk Enterprise product, which helps detect patterns and anomalies in big data and find data of interest in Petabyte-scale Hadoop clusters.
- Uncovering data correlations using Splunk DB Connect, to cross reference structured data in Hadoop with data in a relational database. Hunk lets you turn these correlations immediately into visualizations and dashboards that can be shared with others.
- Accelerates queries on massive data volumes in Hadoop and provides other capabilities like stored statistics, access control and scheduling.
Splunk Hunk Key Capabilities
Hunk can perform the following functions:
- Exploring data in Hadoop—explore data interactively across large datasets with no need to analyze the structure of the data or define schemas. It facilitates deeper analysis and helps users identify anomalies, detect patterns, and enrich insights by connecting to data from relational databases.
- Reporting and visualizing Hadoop data—build graphs, charts and other visualizations based on Hadoop data to make it meaningful to others in the organization. The reports can be shared on any device.
- Custom dashboards—combine charts, views and reports into interactive dashboards that can be viewed on laptops and mobile devices, with security and access control built in.
Should You Use Hunk or Splunk Enterprise?
If your data is stored in Hadoop, Hunk is the obvious choice because it can operate directly on the data with no need for large-scale data intake. However, if you have the option of extracting data from Hadoop, the question arises whether it might be better to switch from Hadoop to Splunk Enterprise.
Advantages of Hunk:
- Hunk typically takes up less disk space compared to Splunk Enterprise, reducing storage costs
- Hunk lets you keep data in Hadoop in its original format and continue to use tools from the Hadoop ecosystem
Advantages of Splunk Enterprise:
- In many cases, searches in Splunk Enterprise run much faster than Hunk on Hadoop
- Supports real-time searches, which is not possible with Hadoop
- Latency is typically much lower for long-running searches
- You can use Splunk Forwarders to ingest log data from a large variety of IT systems, while it can be difficult to continuously ingest data from these sources to Hunk
Splunk Hunk Best Practices
To get the most out of Splunk Hunk and ensure optimal performance and results, it’s essential to follow some best practices:
- Optimize data storage: Ensure that your Hadoop data is stored in a format that is optimized for Splunk Hunk. This includes using file formats such as Parquet or Avro and compressing your data with Snappy or LZO.
- Leverage data partitioning: Make use of data partitioning in Hadoop to improve query performance. By partitioning your data based on relevant criteria, such as time or location, Splunk Hunk can execute queries more efficiently.
- Monitor and tune performance: Regularly monitor the performance of your Splunk Hunk deployment and make adjustments as needed. This includes monitoring resource usage, adjusting virtual indexes settings, and ensuring that your Hadoop cluster is properly configured for optimal performance.
- Secure your data: Ensure that your Hadoop data and Splunk Hunk deployment are secure. Implement proper access controls, encryption, and auditing to protect your data and maintain compliance with relevant regulations.
- Plan for growth: As your data analytics needs evolve, make sure your Hadoop and Splunk Hunk infrastructure can scale to meet the demands. Regularly assess your capacity requirements and plan for future growth.
By following these best practices, organizations can maximize the benefits of Splunk Hunk and ensure that their data analytics efforts deliver the best possible results. With Splunk Hunk and Hadoop working together, companies can unlock the full potential of their data, driving better decision-making and paving the way for innovation and growth.
Read more in our guides to splunk big data and splunk backup.
Reduce Splunk Storage Costs by 70% with SmartStore and Cloudian
Splunk’s new SmartStore feature allows the indexer to index data on cloud storage such as Amazon S3. Cloudian HyperStore is an S3-compatible, exabyte-scalable on-prem storage pool that SmartStore can connect to. Cloudian lets you decouple compute and storage in your Splunk architecture and scale up storage independently of compute resources.
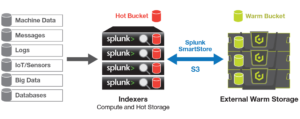
HyperStore also features full Apache Hadoop integration for Splunk Hunk users. Orgnizations can run Hadoop analytics on HyperStore appliances, with no need to offload data to other systems. Under the hood, HyperStore uses S3FS as the target for HDFS, allowing you to run Map Reduce jobs on top of data stored on a Cloudian appliance.
Learn more about Cloudian’s solution for Splunk storage or big data systems including Hadoop/HDFS.