


Sascha Uhl, Solution Architect for Global Strategic Alliances
The Hybrid Data Lakehouse Solution with Cloudian and Snowflake
A growing amount of Data Lakehouse products are or already have integrated the S3 API into their solution to support Cloudian HyperStore. Not only on-premises solutions are leveraging the open API. Also the cloud based Data Lakehouse solution Snowflake is now validated with Cloudian HyperStore.
Snowflake Data Cloud connects with object data stored in the Cloudian HyperStore system, bringing the platform’s analytics and data warehousing capabilities on premises. Data Cloud’s capabilities include analytics, data lake generation, and governance or security policy creation.
In this blog we are covering the configuration and the two biggest use cases of the integration:
- Extending the Data Lakehouse with Snowflake external tables and Cloudian
- Protecting Snowflake datasets with data backup to Cloudian
With its upcoming update Snowflake Data Cloud can also move data from Cloudian HyperStore Object Storage into hyperscalers storage services as well as back on premises, enabling users to shift data for workload demands or cost savings as needed.
Configuring a Data Lakehouse with Snowflake and Cloudian
Once the new functionality is available Cloudian HyperStore can be easily integrated into Snowflake. In the Snowflake Workspace a new “stage” must be created. This “stage” is the key part for the connection to the HyperStore system. It is important that the HyperStore system is using valid CA cert for the TLS encryption.
1. Create bucket and upload sample files
Inside Cloudian HyperStore we need to create a bucket we can use:
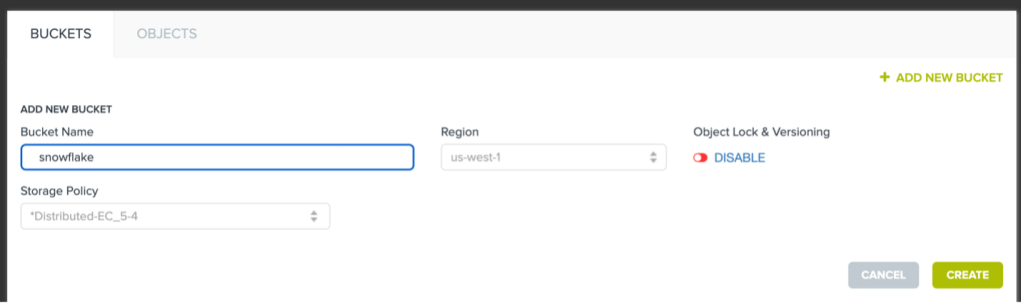
Once the bucket is created we can use the Cloudian Management Console or any other S3 File Browser to upload some data into the bucket we want to analyze. In our example we are uploading some CSV files into the bucket.
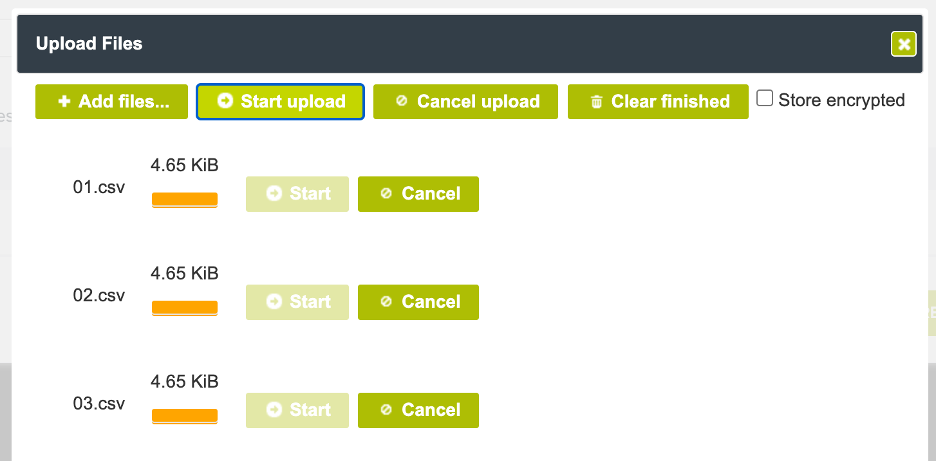
2. Configure Stage in Snowflake
First, we need to tell Snowflake where the external tables should be stored. To do this a new stage has to be created inside Snowflake.
The following command will create the stage:
Parameters required are:
Bucketname
S3 Endpoint URL
Access-Key
Secret-Key
create or replace stage my_s3compat_stage url='s3compat://bucketname/' endpoint='s3-endpoint-url credentials=(aws_key_id='access-key' aws_secret_key='secret-key');
Now as we have the general connection established and we are able to generate the external tables.
3. Create external tables
Snowflake supports a couple file formats which includes CSV and PARQUET files. In our example we want to use data from CSV files which we uploaded to our bucket.
To make these files usable within Snowflake we need to create a table which is point to the uploaded CSV files:
create or replace external table my_ext_table3csv with location = @ my_s3compat_stage/data/csv/ auto_refresh = false refresh_on_create = true file_format = (type = csv);
In our example we do not update the files in the bucket. Because of this we do not need to enable
auto_refresh
It’s important to tell Snowflake which files it should use. /data/csv/ is the subfolder in our bucket hosting the CSV files. type = csv tells Snowflake to load the data as CSV.
With connecting to the bucket and loading the meta data it can be used now within Snowflake.
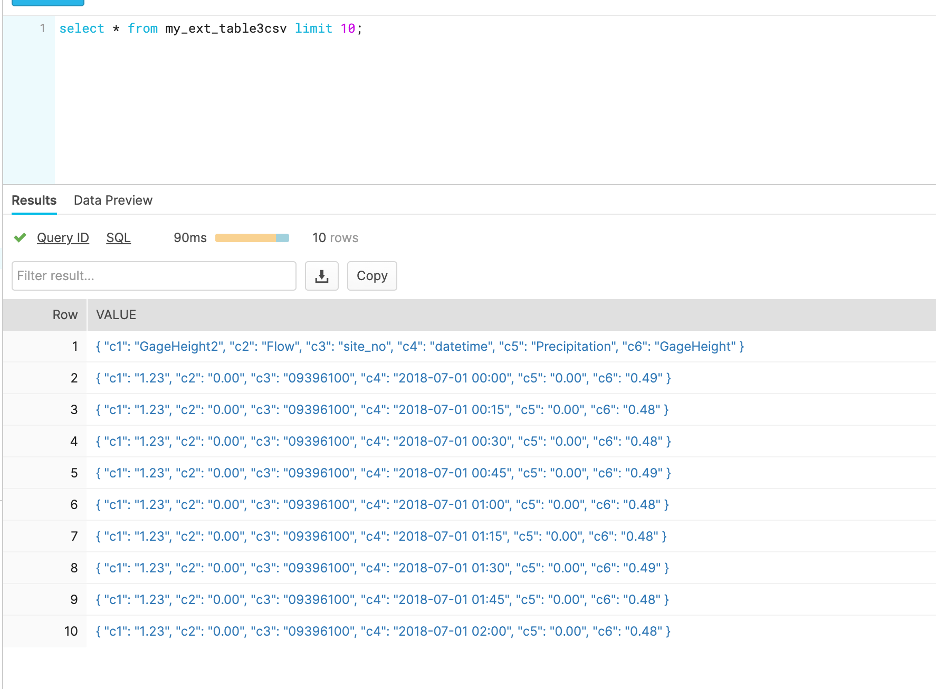
4. Access the data
The data can be access by using the created table. In our example this is
my_ext_table3csv
Most of the SQL statements will work the same way as normal local tables.
Here an example to display the data:
select * from my_ext_table3parquet limit 10;
5. Copy data from Snowflake to Cloudian HyperStore
With the full SQL functionality in mind, we can copy data to the bucket by using the copy into SQL statement:
copy into @my_s3compat_stage/export from ext_onprem_data;
This command allows you to copy the data from Snowflake to your local Cloudian HyperStore system. Full explanation of the “copy into” syntax can be found in the Snowflake help: https://docs.snowflake.com/en/user-guide/data-load-s3-copy.html
This is the foundation on how to use data residing in your own data center inside Snowflake. With the power of SQL a lot of things are possible.
For more information about Cloudian data lakehouse / data analytics solutions go to S3 Data Lakehouse for Modern Data Analytics.