

Object stores need to be more than dumb pipes
It’s common knowledge that the growth rate of created data is increasing and that there is a distinction between unstructured data like an image where the data is treated as a single entity or blob and structured data where the data is formatted such as CSV, JSON, or Parquet. What’s less well-known is that though there is more unstructured data currently, structured data is growing in volume and importance. One study projected by the end of 2025 structured data will grow to 32% of new data captured, created, or replicated. Object storage systems have been very effective at storing and managing unstructured data, but they also need to be targeted for structured data where APIs can exploit the structure or format of the data. For example, software-generated transaction and application logs can be large files of 100s of GBs. Once stored, different use cases may only want to retrieve a subset of the data – e.g., a specific date range or only 2 column fields.
Object stores are ideal as data lakes because data as objects can be globally referenced for storage and retrieval and the amount of stored data can scale to the exabyte range in a fault-tolerant and cost-effective way. As users look to do more analysis and decision-making with the data, however, object stores need to be much more than dumb pipes moving large object blobs back and forth. Instead, users want the advantages of virtually storing all data in one place and also the ability to selectively query that data. Enter the AWS S3 SELECT API that uses SQL syntax to look inside an object and return a subset of that object’s data.
As a simple example, the below has an excerpt of a CSV file of bank transactions:
Date,Description,Deposits,Withdrawals,Balance
20-Aug-2020,Commission,245.00,00.00,”33,763.98″
20-Aug-2020,NEFT,”12,480.00″,00.00,”46,243.98″
20-Aug-2020,RTGS,00.00,”11,561.00″,”34,682.98″
20-Aug-2020,Miscellaneous,”88,736.00″,00.00,”123,418.98″
20-Aug-2020,Cheque,00.00,”15,427.37″,”107,991.61″
20-Aug-2020,Miscellaneous,253.50,00.00,”108,245.11″
20-Aug-2020,Purchase,00.00,”108,245.11″,00.00
20-Aug-2020,Cash,327.21,00.00,327.21
20-Aug-2020,RTGS,00.88,00.00,328.09
20-Aug-2020,Commission,00.00,82.02,246.07
20-Aug-2020,Miscellaneous,04.00,00.00,250.07
20-Aug-2020,IMPS,00.00,00.00,250.07
20-Aug-2020,Cash,41.86,00.00,296.44
20-Aug-2020,NEFT,54.00,00.00,350.44
20-Aug-2020,Transfer,”13,651.96″,00.00,”14,002.40″
20-Aug-2020,Purchase,395.00,00.00,”14,397.40″
20-Aug-2020,NEFT,00.00,”2,879.48″,”11,517.92″
…
Instead of retrieving the whole file (which may be 100s of GBs) and then processing it on the client side, the application can use the S3 SELECT API to filter out to a specific date range and only retrieve withdrawals greater than a specific value. Later, a user can make an ad hoc query for another subset of the data from that same base object. These scenarios show how S3 SELECT enables a basic type of data warehouse functionality.
The S3 SELECT API works on multiple types of structured data: CSV, JSON, Parquet, GZIP, BZIP2. For AI/ML and analytics use cases, S3 SELECT offers advantages of reducing network traffic, reducing the compute load of data processing, and reusing the same base object for multiple uses. S3 SELECT is useful in all environments, but it is especially advantageous for edge applications where fast decision-making is often required and fewer compute and storage resources are available. The rest of this article describes Cloudian’s S3-SELECT software that is Kubernetes-managed and deployable in nearly any environment.
How to make a SELECT request
As part of the S3 API, the SELECT request is sent like any other S3 request, including by REST API using HTTP POST (example below) and available in S3 client SDKs like boto3 or AWS SDKs. Some request fields to highlight:
● Key and bucket. Identifies the object to query.
● Expression. The SQL expression.
● InputSerialization. Describes the compression type and CSV, JSON, or Parquet of the object.
● OutputSerialization. Describes how results of the query are serialized, either CSV or JSON.
Sample REST API request from https://docs.aws.amazon.com/AmazonS3/latest/API/API_SelectObjectContent.html
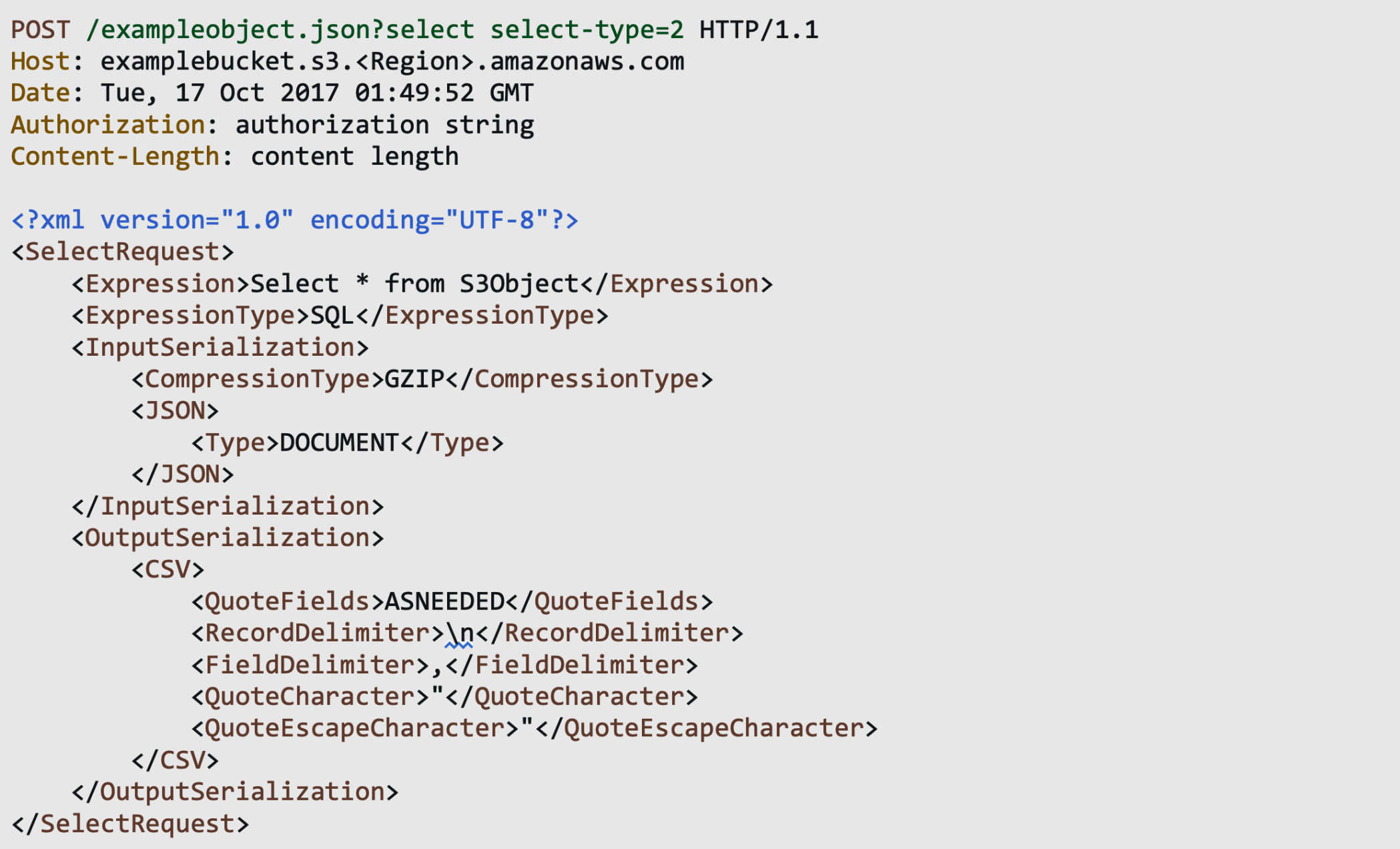
Here’s an example of a Python script that makes a SELECT request to count the number of records in the bucket “reports_20220421” and object “financialsurvey.csv”.
import boto3
from botocore.config import Config
s3_endpoint=’https://10.43.211.217:8082′
session = boto3.session.Session()
s3_client = session.client (
config=Config(s3={‘addressing_style’: ‘virtual’}),
service_name=’s3′,
endpoint_url=s3_endpoint,
aws_access_key_id = ‘ABCDEFGHIJKLMNOPQRST’,
aws_secret_access_key = ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’,
region_name=’region1′)
s3 = s3_client
r = s3.select_object_content(
Bucket=’reports_20220421′,
Key=’financialsurvey.csv’,
ExpressionType=’SQL’,
###################################
Expression=”select COUNT(*) from s3object”,
###################################
InputSerialization = {‘CSV’: {“FileHeaderInfo”: “USE”}},
OutputSerialization = {‘CSV’: {}},
)
for event in r[‘Payload’]:
if ‘Records’ in event:
records = event[‘Records’][‘Payload’].decode(‘utf-8’)
print(records)
The HTTP response will have the result of the query, formatted per the request’s OutputSerialization value. Here’s an example from the COUNT query that simply returns an integer value:
HTTP/1.1 200 OK
x-amz-id-2: ase56teao0dfgq246AGFdf2234t/323covwq4cSA13sdv4t6vcvwe4tqS=
x-amz-request-id: a3452tsd351135
Date: Tue, 22 Feb 2022 23:54:05 GMT
23634614
Following a request through the system
As previously mentioned, Cloudian’s S3-SELECT software is Kubernetes-managed, described by a set of YAML configuration files that deploys two types of Pods, a Master cluster and a Worker cluster. It is used in conjunction with an S3-compatible object store. The Master Pod communicates directly with the S3 clients and builds task lists that split a SELECT request into multiple object fragments for the Worker processes. The Worker Pod polls the Master for tasks, and for each task, retrieves the fragment of the S3 object (by byte range) from the S3 object store. The Worker Pod then applies the SELECT SQL and formatting to the object fragment and streams the result back to the Master. Depending on the type of SELECT query, the Master either starts streaming the results back to the S3 Client or accumulates the result to combine with other Worker results.
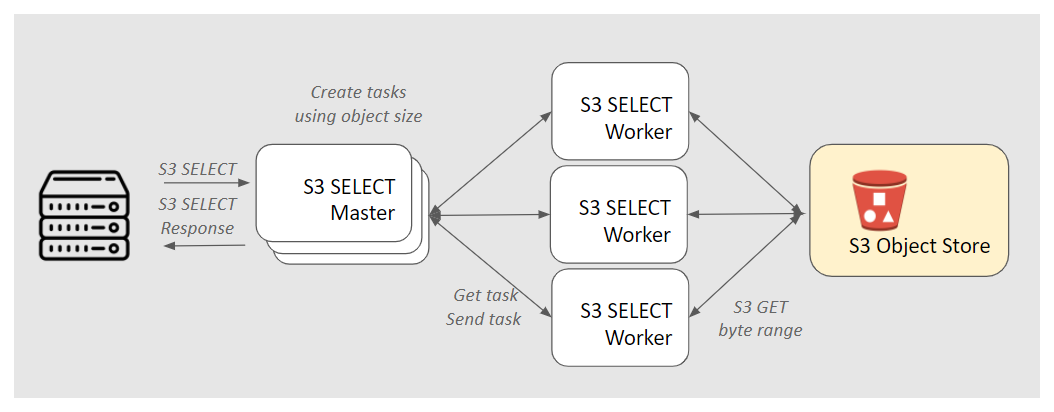
A typical SELECT request follows this sequence:
- (S3 Client) An S3 client sends a SELECT HTTPS request to a load balancer with the S3-SELECT master endpoint address and port. Typically, a DNS lookup for a virtual-host style domain (e.g., “mybucket.s3select.example.com”) is done.
- (Master) Receive the request and check Signature v4 authentication and authorization and proper request syntax.
- (Master) Using the S3 bucket and object key, get the object metadata from the S3 object store. From the object metadata and the SELECT SQL query, a list of distributable tasks is created.
- (Worker) Poll a Master node for a task. If a task is found, the Worker updates the task as “in-progress” at the Master, and retrieves the task’s object fragment from the object store.
- (Worker) Process the object fragment according to the SELECT SQL and formatting of the request, e.g., filter the column fields or value range and stream the resulting data to the Master. On completion, it updates the task status on the Master.
- (Master) If the SELECT query is an aggregation such as COUNT, the Master needs to wait for all task results from the Workers. If there is no aggregation, the Master streams the data back to the S3 Client as it receives it from the Workers. Once all results have been received from Workers and sent to the S3 Client, the connection is closed.
A fault-tolerant, scalable and distributed architecture
The above section describes processing a single request. The software is designed to scale and distribute to handle as many requests in parallel as needed. Multiple Master Pods are used to distribute the incoming traffic from S3 clients. A load balancer distributes the requests to any Master Pod since each request is handled independently of other requests. The Kubernetes load balancer service, Ingress Controllers or an external load balancer can be used. Each Master Pod manages its own set of requests, and the Worker Pods poll for tasks from all Master Pods to prevent any job starvation.
Multiple Worker Pods are normally deployed. Whereas the Master Pod’s primary role is job coordination and S3 request management, the Worker Pod’s primary role is SELECT SQL processing on the object data. Typically, more Worker Pods than Master Pods are allocated because most of the processing is done by Workers. Depending on load, the number of Master or Worker Pods is dynamically modifiable by changing the value in the Kubernetes statefulset spec for “replicas.” Qualitatively, if there are many S3 SELECT requests on smaller objects, then relatively more Master vs. Worker Pods are needed, and, conversely, if the objects are large with many tasks, then more Worker Pods are needed.
Service discovery occurs in the Kubernetes standard way, so a Worker Pod can discover all the Master Pods dynamically. This allows the overall service to tolerate Pod or Node unavailability, networking changes such as an IP address change, or scale-out/scale-in changes.
The S3-SELECT software does not alter the object data stored in the S3 object store. With respect to the object data, the S3-SELECT software is stateless and stores no persistent data. In the worst case where the Master Pods suddenly go offline, then in-progress jobs are gone, and the S3 Client can re-initiate those requests. If a Worker Pod goes offline, the tasks assigned to this Worker will timeout at the Master, and the Master will re-add the jobs to the task queue for other Workers.
Infrastructure to Enable the Edge
S3-SELECT is a part of Cloudian’s HyperStore Analytics Platform (HAP) software, a Kubernetes-managed infrastructure for compute and storage at the edge, data center, and cloud. Other plug-in HAP components include an S3-compatible object store, a streaming feature store, and an S3 Object Lambda processor. HAP is well-tuned to be used in conjunction with Cloudian’s HyperStore S3-compatible object store for on-premises and hybrid workloads.
For more information, contact us.

Gary Ogasawara, CTO, Cloudian
View LinkedIn Profile
