

Disaster can strike a business at any moment. Research shows that without preparation and data protection, over 50% of businesses will not survive a major disaster. It is crucial to assess your IT infrastructure and understand what information security measures you can take to decrease the damage caused by a disaster and recover operations quickly. Learn about four essential elements you must include in your disaster recovery program for it to be effective.
This is part of an extensive series of guides about cybersecurity.
In this article you will learn:
- Why Is Disaster Recovery Important?
- What Is a Disaster Recovery Plan?
- What Is the Difference Between Disaster Recovery and Business Continuity?
- How Does Disaster Recovery Work? Key Features of a Disaster Recovery Program
- Building Your Disaster Recovery Plan
- Types of Disaster Recovery Solutions and Services
- Built-In Data Protection for Disaster Recovery with Cloudian
What is Disaster Recovery?
Disaster recovery is the practice of anticipating, planning for, surviving, and recovering from a disaster that may affect a business. Disasters can include:
- Natural events like earthquakes or hurricanes
- Failure of equipment or infrastructure, such as a power outage or hard disk failure
- Man-made calamities such as accidental erasure of data or loss of equipment
- Cyber attacks by hackers or malicious insiders
What is a Disaster Recovery Plan?
A disaster recovery plan enables businesses to respond quickly to a disaster and take immediate action to reduce damage, and resume operations as quickly as possible.
A disaster recovery plan typically includes:
- Emergency procedures staff can carry out when a disaster occurs
- Critical IT assets and their maximum allowed outage time
- Tools or technologies that should be used for recovery
- A disaster recovery team, their contact information and communication procedures (e.g. who should be notified in case of disaster)
Why is Disaster Recovery Important?
Drafting a disaster recovery plan, and ensuring you have the right staff in place to carry it out, can have the following benefits:
- Minimize interruption – in the event of a disaster, even if it is completely unexpected, your business can continue operating with minimal interruption.
- Limit damages – a disaster will inevitably cause damage, but you can control the extent of damage caused. For example, in hurricane-prone areas, businesses plan to move all sensitive equipment off the floor and into a room with no windows.
- Training and preparation – having a disaster recovery program in place means your staff are trained to react in case of a disaster. This preparation will lower stress levels and give your team a clear plan of action when an event occurs.
- Restoration of services – having a solid disaster recovery plan means you can restore all mission critical services to their normal state in a short period of time. Your Recovery Time Objective (RTO) will determine the longest time you are willing to wait until service is restored.
What Is the Difference Between Disaster Recovery and Business Continuity?
Business continuity (BC) and disaster recovery (DR) are often grouped into one corporate identity called BCDR. However, while the two share similar objectives that help improve the organization’s resiliency, business continuity and disaster recovery differ in scope.
Business continuity is a proactive approach to minimizing risks and ensuring the organization can continue to deliver products and services regardless of the circumstances. BC primarily focuses on defining ways to ensure employees can continue their work and enable the business to continue operations during disaster events.
Disaster recovery is a subset of BC focused mainly on the IT systems required for business continuity. DR defines specific steps needed to resume technology operations after an event occurs. It is a reactive process that requires planning, but organizations implement DR only when a disaster truly occurs.
Related content: Read our guide to disaster recovery and business continuity
How Does Disaster Recovery Work? Key Features of a Disaster Recovery Program
Here are four things you must include in your disaster recovery plan and process, to ensure your business continuity.
Know Your Threats
Learn about the history of your business, the industry and the region, and map out the threats you are most likely to face. These should include natural disasters, geopolitical events like wars or civil unrest, failure to critical equipment like servers, Internet connections or software, and cyber attacks that are most likely to affect your type of business.
Ensure your disaster recovery plan is effective against all, or at least the most likely or most significant threats. If necessary, develop separate DR plans or separate sections within your DR plan for specific types of disasters.
Know Your Assets
It’s important to be comprehensive. Get your team together and make a big list of all the assets that are important for the day-to-day operations of your business. In the IT sphere this includes network equipment, servers, workstations, software, cloud services, mobile devices, and more. Once you have your list organize it into:
- Critical assets your business cannot operate without – for example, an email server
- Important assets that can seriously hamper some activities – for example, a projector used for presentations
- Other assets that will not have a major effect on the business – for example, a recreational system used by employees on their lunch break
Define Your RTO and RPO
Define your Recovery Time Objective (RTO) for critical assets. What period of downtime can you sustain? For example, a high traffic eCommerce site sustains major financial damage for every minute of downtime. An accounting firm may be able to sustain a day or two of downtime and resume normal operations, provided there is no data loss. Build a process and obtain technological means that can help you bring operations back online within the RTO.
The term recovery point objective (RPO) refers to the maximum age of files the organization must recover from backup storage to resume normal operations after a disaster occurs. Organizations use RPO to determine the minimum frequency of backups. For example, a four-hour RPO requires backing up at least every four hours.
Set Up Disaster Recovery Sites
A cornerstone of almost every disaster recovery plan is having a way to replicate data between multiple disaster recovery sites. While many businesses schedule periodic data backups, for disaster recovery purposes, the preferred approach is to continuously replicate data to another system. Data may be replicated to:
| On-Site Cold Storage
A backup device within your data center. |
On-Site Warm Backup
A redundant operational unit in your data center, for example, a secondary server. |
| Off-Site Cold Storage
A backup device in a remote data center, or cloud storage with high latency, involving a delay or extra cost to retrieve data. |
Off-Site Warm Backup
A redundant operational unit in a remote data center, or cloud storage with low latency, enabling immediate data access. |
Local storage is less resilient to disaster but gives you a shorter RTO. It also allows you to replicate or backup data more frequently, improving your Recovery Point Objective (RPO) – meaning you can restore your data from almost every point in time.
Test Backups and Restoration of Services
Just like business systems can fail in a disaster, so can backups. There are many horror stories of organizations that had a backup system in place, but discovered too late that backups were not actually working properly. A configuration problem, software error or equipment failure can render your backups useless, and you may never know it unless you test them.
An inseparable part of any disaster recovery plan is to test that data is being replicated correctly to the target location. It’s just as important to test that it’s possible to restore data back to your production site. These tests must be conducted once, when you set up your disaster recovery apparatus, and repeated periodically to ensure the setup is still working.
5 Expert Tips that can help you better strengthen your DR strategy

Jon Toor, CMO
With over 20 years of storage industry experience in a variety of companies including Xsigo Systems and OnStor, and with an MBA in Mechanical Engineering, Jon Toor is an expert and innovator in the ever growing storage space.
Prioritize application dependencies: Map out application interdependencies. Knowing which applications rely on others helps ensure that critical apps are brought online in the correct sequence during disaster recovery, avoiding bottlenecks and delays.
Incorporate advanced threat detection in your DR plan: Integrate cybersecurity monitoring tools that detect threats during the disaster recovery process. This ensures that the restored environment is not compromised by latent threats that may have caused the disaster in the first place.
Leverage immutable backups: Use immutable backups, especially to safeguard against ransomware attacks. These backups cannot be altered or deleted within a specified time frame, ensuring a clean recovery point.
Implement geodiverse backups: Instead of relying on one geographic location, replicate your backups across multiple regions to ensure data availability even in the event of a regional disaster like earthquakes or hurricanes.
Encrypt backups at rest and in transit: Ensure backups are encrypted both at rest and while being transmitted to your disaster recovery site. This adds an extra layer of protection.
Building Your Disaster Recovery Plan
Here are key steps to help guide you through the process of creating a disaster recovery plan:
Risk Assessment
A disaster recovery plan should start with business impact analysis (BIA) and risk assessment that address the relevant potential disasters. Here are key aspects of considerations:
- Analyze all functional areas of the organization – this analysis can help you identify possible consequences, such as data loss or leakage.
- Evaluate risks and define suitable goals – disaster recovery is a key component in larger business continuity plans. Evaluating risks and setting goals can help organizations recover critical business operations that enable continuity even while IT teams address the incident.
- Determine geographical and infrastructure risk factors – a risk analysis should factor these complex risks to enable organizations to prepare a suitable recovery strategy for these events. You should determine whether you need cloud backup, whether a single site will suffice or do you need multiple sites, and who is allowed access.
Evaluate Critical Needs
Once you have completed a risk assessment, you need to evaluate the critical needs of each department and establish priorities for operations and processing. It involves creating written agreements for predetermined alternatives and specifying the following details:
- Special security procedures
- Availability, cost, and duration
- Guarantee of compatibility
- Hours of operation
- Scenarios the organization defines as emergencies
- System testing
- A procedure for notifying users of system changes
- Personnel requirements
- Specifications of hardware required for critical processes
- Service extension negotiation process
- Any relevant contractual issue
Set Disaster Recovery Plan Objectives
Here are key aspects to help you set disaster recovery plan objectives:
- Create a list of mission-critical operations needed for business continuity – when creating your list, decide which applications, data, user accesses, and equipment are needed to support these operations.
- Document your RTO and RPO – finalize the required RTO and RPO for each critical asset and document it.
- Assess service level agreements (SLAs) – all of your objectives should account for SLAs promised to any stakeholder, including users and executives.
Collect Data and Create the Written Document
Data helps create informed and relevant disaster recovery plans. Here are key data types to collect at this stage:
- Lists – include critical contact information lists, master vendor lists, backup employee position listings, notification checklists, master call lists.
- Inventories – include communications equipment, documentation, data center computer hardware, forms, microcomputer hardware and software, insurance policies, office equipment, workgroup hardware, and off-site storage location equipment.
- Schedules – include schedules defined for software and data files backup or retention.
- Procedures – include all procedures defined for system restore or recovery.
- Locations – include all temporary disaster recovery locations.
- Documentation – include any relevant inventories, materials, and lists.
Organize and include this data in a written, documented plan.
Test and Revise
A disaster recovery plan should remain theoretical – you need to regularly test and revise the plan to ensure it remains relevant. Testing can help obtain the following benefits:
- Ensure the organization is adopting feasible, compatible backup procedures and facilities.
- Identify areas in the plan that require modification.
- Training your team to ensure they are well prepared to implement the plan.
- Prove the value of your plan and the organization’s ability to withstand disasters.
Here are several types of disaster recovery plan tests you can employ:
- Disaster recovery plan checklist tests
- Parallel tests
- Full interruption tests
- Simulation tests
Before running the test, you should determine the criteria and procedures for testing your disaster recovery plan. After choosing a test, you should conduct a structured walk-through test or an initial dry run and correct any issues. Ideally, you should run this run dry outside normal business hours to avoid disrupting work.
Related content: Read our guide to disaster recovery plans
Types of Disaster Recovery Solutions and Services
Organizations may choose various DR strategies according to the infrastructure and assets they wish to protect and the backup and recovery methods they use. The scale and vision of an organization’s DR plan may require specific teams for departments like networking or data centers. Here are some examples of DR solutions:
Data Center Disaster Recovery
Data centers are the backbone of modern businesses, housing critical IT infrastructure, applications, and data. When a disaster impacts a data center, the consequences can be severe, leading to significant downtime, data loss, and financial losses. Implementing a comprehensive data center disaster recovery plan is essential to ensure the continuity of business operations and minimize the impact of such events.
A data center disaster recovery plan typically includes several components to ensure the quick and efficient recovery of data and systems. These components may include:
- Risk assessment and business impact analysis: Identifying potential risks and assessing their impact on business operations.
- Disaster recovery strategies: Developing strategies to recover critical data and systems, such as offsite data backups, redundant infrastructure, and failover mechanisms.
- Recovery objectives: Establishing recovery time objectives (RTOs) and recovery point objectives (RPOs) to determine the acceptable levels of downtime and data loss.
Testing and maintenance: Regularly testing the disaster recovery plan to ensure its effectiveness and updating it as needed to address changes in the business environment.
Network Disaster Recovery
Network disaster recovery focuses on the restoration of an organization’s network infrastructure, ensuring that critical systems and applications remain accessible during and after a disaster. This type of recovery is essential for maintaining communication, collaboration, and data exchange between employees, customers, and partners.
Effective network disaster recovery planning involves several key elements, including:
- Network redundancy: Implementing redundant network connections and equipment to ensure continuous availability in the event of a failure.
- Network segmentation: Dividing the network into smaller segments to isolate issues and minimize the impact of a disaster on the entire network.
- Failover mechanisms: Configuring systems and devices to automatically switch to an alternate network path or component in case of a failure.
Regular testing and monitoring: Continuously monitoring network performance and conducting regular tests to identify potential issues and assess the effectiveness of the disaster recovery plan.
Cloud-Based Disaster Recovery (Disaster Recovery as a Service)
Cloud disaster recovery, also known as disaster recovery as a service (DRaaS) is a modern approach to protecting your organization’s data and applications by leveraging cloud-based resources. This type of disaster recovery offers several benefits, including:
- Cost savings: Cloud disaster recovery eliminates the need for costly on-premises infrastructure and allows you to pay only for the resources you need, reducing capital and operational expenses.
- Scalability: Cloud disaster recovery solutions can easily scale to accommodate the needs of growing businesses, ensuring that you always have sufficient resources to recover from a disaster.
- Flexibility: Cloud disaster recovery allows you to choose from various recovery options, such as full data restoration or partial recovery of specific applications and systems, depending on your organization’s needs.
Implementing a cloud disaster recovery plan involves several steps, such as:
- Assessing your organization’s needs: Determine the criticality of your data and applications, as well as your RTOs and RPOs, to identify the appropriate recovery strategy.
- Selecting a cloud disaster recovery provider: Choose a reputable cloud provider with a strong track record in disaster recovery and a robust, secure infrastructure.
- Configuring the cloud environment: Set up and configure the cloud environment to replicate your on-premises infrastructure, ensuring that all critical systems and applications are protected.
Testing and monitoring: Regularly test the cloud disaster recovery plan to ensure its effectiveness and monitor the cloud environment to detect potential issues.
Related content: Read our guide to
- Disaster recovery in the cloud
- Disaster recovery as a service
- Disaster recovery and business continuity
- Disaster recovery policy
- Disaster recovery plan examples
- Disaster recovery solutions
- Disaster recovery vs. high availability
- Disaster recovery on aws
- IT disaster recovery plan
Virtualized Disaster Recovery
Virtualized disaster recovery leverages virtualization technology to replicate and recover entire systems, including operating systems, applications, and data, on virtual machines (VMs). This approach offers several advantages, such as:
- Faster recovery times: Virtualized disaster recovery allows for the rapid recovery of systems and applications, as VMs can be quickly provisioned and configured.
- Simplified management: Virtualization simplifies disaster recovery management by consolidating multiple systems onto a single platform, reducing the complexity of the recovery process.
- Improved resource utilization: Virtualized disaster recovery enables the efficient use of resources, as VMs can be dynamically allocated and scaled according to your organization’s needs.
To implement a virtualized disaster recovery plan, you should:
- Assess your organization’s virtualization capabilities: Determine the extent to which your existing infrastructure can support virtualization and identify any gaps that need to be addressed.
- Develop a virtualization strategy: Create a plan for implementing virtualization across your organization, including the selection of appropriate virtualization platforms and tools.
- Configure and test the virtual environment: Set up and configure the virtual environment to replicate your on-premises infrastructure, ensuring that all critical systems and applications are protected.
Monitor and maintain the virtual environment: Continuously monitor the virtual environment to detect potential issues and perform regular maintenance to ensure optimal performance and reliability.
Built-In Data Protection for Disaster Recovery with Cloudian
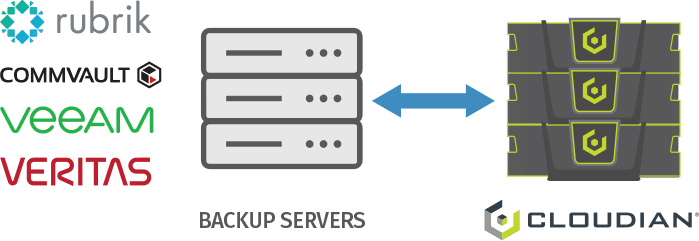
Do you need to backup data to on-premises storage, as part of your disaster recovery setup? Cloudian offers a low-cost disk-based storage technology that lets you backup data locally with a capacity of up to 1.5 Petabytes. You can also set up a Cloudian appliance in a remote site and use our integrated data management tools to save data there.
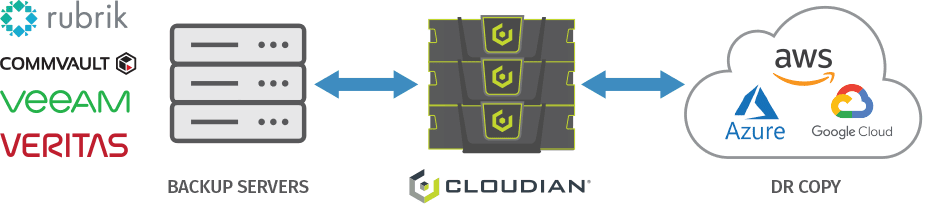
Another deployment option is a hybrid cloud configuration. You can backup data to a local Cloudian appliance, then replicate to the cloud for DR purposes. This combines the low latency of local storage with the resilience of the cloud.
Learn more about Cloudian’s data protection solutions.
See Additional Guides on Key Cybersecurity Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of cybersecurity.
AWS Backup
Authored by N2WS
- [Guide] AWS Backup: Top 15 Questions, How It Works, Pricing and Pros/Cons
- [Guide] AWS Backup for RDS: How It Works, Limitations & Doing It Right
- [Checklist] AWS Backup & DR
- [Product] N2WS | Cloud Backup and Restore
Azure Backup
Authored by N2WS
- [Guide] Azure Backup: Pricing, Best Practices, & Common Pitfalls to Avoid
- [Guide] Azure Storage Cost Factors, Pricing Examples & Optimization Tips
- [Guide] Cross-Cloud Guide
- [Product] N2WS | Cloud Backup and Restore
UEBA
Authored by Exabeam