

Request a Demo
Join a 30 minute demo with a Cloudian expert.
The purpose of a disaster recovery policy is to identify critical business assets, and define activities needed to ensure their continuity in a disaster. The policy can cover any assets essential for business operations—equipment, software, physical facilities, and even employees—and determines what steps the business will take to protect and recover them.
Disaster recovery policies should not be confused with disaster recovery plans:
Related content: read our guide to IT disaster recovery plans
In this article, you will learn:
In today’s highly digitized world, organizations have become highly reliant on high availability. Downtime is rarely tolerated. And when it comes to mission-critical systems—downtime is not tolerated at all. When disasters strike—a power outage, a ransomware attack, a malicious insider—organizations that are not prepared might suffer significant damage.
The repercussions of a data loss and a successful breach may be different depending on the business and industry. A financial institution handling funds may face not only loss of customer trust but also fines imposed by regulatory entities. When a healthcare facility suffers from downtime or data loss, lives may be in mortal danger.
This is where a disaster recovery policy comes in—this document outlines all of the procedures and tools that must be put into place in case of a disaster. Typically, creating a disaster recovery policy involves the use of two important metrics:
The RPO and RTO helps you create a disaster recovery policy that suits your needs.
Related content: read our guide to disaster recovery and business continuity plans
It is imperative that the disaster recovery policy you design fits the needs of your organization. Here are several types of disaster recovery policies, to be applied during certain circumstances:
A virtualized environment can help you quickly spin up new virtual machine (VM) instances. This can occur within the span of minutes, ensuring high availability for application recovery. A virtualized disaster recovery policy often provides a high level of efficiency.
You can also use your virtualized environment to quickly perform testing. To achieve this, you need to add a stipulation to the policy that ensures applications can run in disaster recovery mode and then can return to normal operations according to the RPO and RTO.
A network disaster recovery policy can be as complex as the recovered network. This is why the policy should be highly detailed, including a step by step breakdown of all recovery procedures. It is also important to test the policy and keep it up to date.
There are several ways to use the cloud for disaster recovery. You can back up files in the cloud or maintain complete replicas, enabling you to transition operations to remote cloud resources in case of a disaster. Cloud DR offers compelling advantages, including costs reduction and improved resilience, compared to disaster recovery based on company-owned resources.
To ensure your cloud DR is efficient and compliant, you should keep track of cloud components and implement security measures. When creating a cloud DR policy, you need to account for the location of virtual and physical servers. Additionally, your policy should address security and compliance requirements.
A data center disaster recovery policy is designed especially for the local facility and its infrastructure. To create a relevant policy, you need to do an operational risk assessment, which analyzes components of the data center. For example, an analysis of the power systems, the location of the facility, the office space, and overall security.
The risk assessment can help you create a policy that suits the data center as a whole and its individual components. In addition to addressing risks, the data center disaster recovery policy should also address relevant possible disaster scenarios.
Here are some of the most important elements of a successful disaster recovery policy.
There are many types of crises that may affect an organization, and in each disaster scenario, every aspect of the organization’s critical assets needs to be protected. However, the exact scope of the policy is limited by the disaster recovery plan. The policy should closely follow the disaster recovery plan, and define specific rules and procedures for each asset that needs to be protected.
To recover from a disaster, you need a disaster recovery team that is familiar with your organization’s documented recovery process. The responsibilities of the recovery team should include immediate actions when a disaster occurs, and post-disaster activities.
It should be very clear who is responsible for what—and individuals with certain responsibilities should have the relevant skills and training to perform them. It is important to provide emergency procedures that take into account failure of certain parts of the business infrastructure—for example, how to communicate if there is no cellular connectivity.
Beyond the disaster recovery team itself, company employees should be trained in disaster recovery procedures, so they know what to do in time of crisis, how to protect themselves and the assets they work with, and how to continue working during the crisis. Proper training not only provides practical assistance, but also moral and psychological relief during an uncertain time.
A disaster recovery policy must include a detailed communication plan, with a list of contacts of people who need to be notified about the disaster. The plan should include precise information protocols—what information to convey, over what channel and in what format, to save time and reduce confusion during a crisis.
Here are a few best practices that can ensure your disaster recovery policy is a success:
You need to understand the hardware, software, and data that are critical to your business. Go over server rooms, data centers, virtual machines (VMs) based on-premises and in the cloud, and endpoints like employee workstations. Review networks, applications, and data stores.
Pay special attention to the configuration of networks, hypervisors and servers that will need to be restored in case of a disaster.
Ensure that each sensitive system has a working backup system, that backups are regularly performed, and there is a tested procedure for recovering these systems from backup. Assess the risk that some systems will not be able to recover from backup, and develop appropriate replacement strategies.
Downtime can not only disrupt productivity and cause revenue loss, but also damage a company’s reputation and result in legal and compliance violations. Calculating the cost of a potential failure can help you determine your investment in preventive measures.
Disaster recovery policies must evolve. You’ll need to update it whenever organizational structure, infrastructure, applications or data structure changes. Run regular drills to see if your policy still holds up, or if there are unanticipated changes to systems that need to be accounted for.
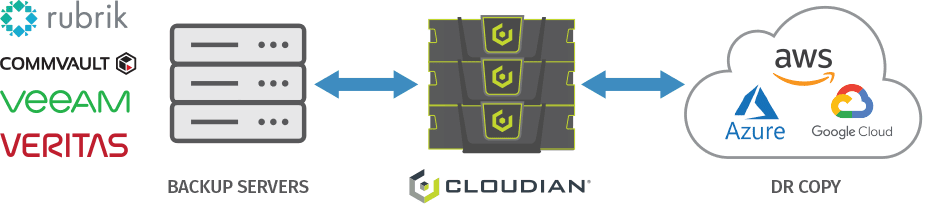
If you need to backup data to on-premises storage, Cloudian offers low-cost disk-based storage with capacity up to 1.5 Petabytes. You can also set up a Cloudian appliance in a remote site and save data directly to the remote site using our integrated data management tools.
 Alternatively, you can use a hybrid cloud setup. Backup data to a local Cloudian appliance, and configure it to replicate all data to the cloud. This allows you to access data locally for quick recovery, while keeping a copy of data on the cloud in case a disaster affects the on-premise data center.
Alternatively, you can use a hybrid cloud setup. Backup data to a local Cloudian appliance, and configure it to replicate all data to the cloud. This allows you to access data locally for quick recovery, while keeping a copy of data on the cloud in case a disaster affects the on-premise data center.
Learn more about Cloudian’s data protection solutions.