

What Is Disaster Recovery?
Disaster recovery (DR) is the organization’s ability to respond to and recover from events that negatively affect business operations.
A disaster recovery plan is a documented policy or process designed to standardize an organization’s response to disasters, and enable faster and more effective recovery. It details all actions the relevant roles must take before, during, and after a disaster.
A disaster recovery plan must address:
- Man-made disasters—including cyber attacks, terrorism, and human error.
- Natural disasters—including earthquakes, landslides, lightning, volcanic eruptions, wildfires, tornadoes, floods, hurricanes, and extreme weather conditions.
What Is High Availability?
High availability (HA) is a system’s ability to operate continuously without experiencing failure for a predefined period.
High availability processes help ensure the system meets a predefined operational performance level. The standard is typically five-nines availability, which aims to achieve 99.999% availability for the system or product at all times.
High availability systems strive to keep critical systems operational even during disasters.
High availability is critical for business continuity, and can even save lives. For example, autonomous vehicles, military control systems, healthcare, and industrial systems are critical and must remain available and operational at all times.
Related content: Read our guide to disaster recovery plans
In this article:
- How Disaster Recovery Works
- How Does High Availability Work?
- Disaster Recovery vs High Availability
- High Availability and Disaster Recovery Reinforce One Another
- Built-in Data Protection for Disaster Recovery with Cloudian
This article is part of a series on Disaster Recovery.
How Disaster Recovery Works
Today, businesses of all sizes can implement disaster recovery more easily due to cloud and virtualization technologies. Advances in these fields have made it possible to easily package complex systems, save them to a remote site, and restore them at the click of a button.
Public cloud platforms provide a scalable, resilient infrastructure which can save as a company’s remote DR site. Some companies still maintain their own DR infrastructure, but they also make use of virtualization and containerization to make backup and restore easier and more effective.
Organizations use a DR site—whether internal, external, or cloud-based—to backup data, technical infrastructure, and business applications. When the primary data center is unavailable, they can transition operations to systems running in the DR site, and when systems are back online, restore them from the backups.
Disaster recovery solutions take many forms. DR providers can offer backup and recovery software, infrastructure hosting services, DR management services, or end-to-end disaster recovery as a service (DRaaS) solutions.
It is important to remember that disaster recovery is not just an IT concern, and has additional organizational components, such as security, risk management, and compliance. Therefore, some vendors combine disaster recovery with other aspects of security planning, such as incident response and contingency planning.
Learn more in our guides about:
How Does High Availability Work?
No system can be 100% available, but a high-availability system strives for an operational performance standard of 99.999%. Here are some main principles to consider when designing an HA system:
- Avoid a single point of failure—the system must not rely on one component to run applications, which can cause the entire system to fail.
- Ensure reliable crossover—the system must have built-in redundancy to allow backup components to replace failed ones, ensuring reliable failover and crossover.
- Detect failures—failures must be visible. The system should automatically identify and avoid issues that may result in failures.
Load balancing is important for ensuring high availability when multiple users access the system. The load balancer distributes workloads automatically, determining which system resource can best handle each workload. Using several load balancers helps prevent resources from being overwhelmed.
HA systems have tiered architectures with multiple servers in different clusters enabling failover. If one cluster or server fails, another can take over without impacting performance. Ensuring high availability is more challenging in complex systems with more potential points of failure.
Disaster Recovery vs. High Availability
Disaster recovery and high availability are closely related, but they address different parts of business continuity. High availability focuses on keeping systems running with minimal interruption, while disaster recovery focuses on restoring systems after a disruptive event has already affected operations.
Primary Goal
High availability is designed to prevent downtime. Its goal is to keep applications, services, and infrastructure available even when individual components fail. For example, if one server stops responding, another server can automatically take over so users experience little or no disruption.
Disaster recovery is designed to recover from downtime. Its goal is to restore data, applications, infrastructure, and business operations after a major incident, such as a cyberattack, data center outage, natural disaster, or large-scale system failure. DR assumes that a disruption has occurred and defines how the organization will return to normal operations.
Failure Scope
High availability typically addresses localized or component-level failures. These can include a failed server, storage device, network path, application instance, or load balancer. HA architectures are built with redundancy so that if one component fails, another can immediately continue serving traffic.
Disaster recovery addresses larger and more disruptive events. These may affect an entire data center, cloud region, office, application environment, or business process. DR planning considers scenarios where normal HA mechanisms are not enough, such as widespread infrastructure damage, ransomware encryption, or a prolonged regional outage.
Timeframe
High availability operates in real time or near real time. Failover often happens automatically within seconds or minutes, depending on the system design. The goal is to make the transition fast enough that users experience minimal service degradation.
Disaster recovery usually works on a longer timeline. Recovery may take minutes, hours, or even days, depending on the organization’s recovery objectives, the severity of the incident, and the complexity of restoring systems. DR processes often involve investigation, coordination, validation, and controlled restoration.
Recovery Metrics
High availability is commonly measured by uptime percentages, such as 99.9%, 99.99%, or 99.999% availability. These metrics indicate how much downtime is acceptable over a given period.
Disaster recovery is commonly measured using recovery time objective and recovery point objective. Recovery time objective defines how quickly systems must be restored after an outage. Recovery point objective defines how much data loss is acceptable, usually measured by the time between the last usable backup or replication point and the disaster event.
Architecture
High availability relies on redundancy within the production environment. This can include clustering, load balancing, automatic failover, replicated databases, redundant power, multiple network paths, and health monitoring. These components are usually active or ready to become active immediately.
Disaster recovery relies on backup, replication, and alternate recovery environments. These may include offsite backups, cloud-based recovery sites, warm standby environments, cold standby environments, or disaster recovery as a service. DR architecture is often separate from the primary production environment to ensure systems can be restored even if the main site is unavailable.
Automation
High availability is usually highly automated. Monitoring systems detect failures and trigger failover without requiring manual intervention. This automation is essential because HA is intended to maintain service continuity while the system is still running.
Disaster recovery may be partially automated, but it often includes manual decision-making and operational procedures. Teams may need to declare a disaster, activate the DR plan, assess damage, restore backups, redirect users, validate data integrity, and communicate with stakeholders.
Data Protection
High availability protects service continuity, but it does not always protect against data corruption or malicious changes. For example, if ransomware encrypts files in a highly available environment, those encrypted files may be replicated across redundant systems.
Disaster recovery focuses more heavily on data protection and restoration. DR strategies typically include backups, immutable storage, versioning, retention policies, and recovery testing. These capabilities allow organizations to restore clean data from a known good point in time.
Cost and Complexity
High availability can be expensive because it requires redundant infrastructure, continuous monitoring, load balancing, failover mechanisms, and often active-active or active-passive system designs. The cost increases as the required availability level becomes stricter.
Disaster recovery costs depend on the recovery strategy. A cold standby site may be less expensive but slower to recover, while a hot standby or fully replicated DR environment is faster but more costly. Organizations usually balance DR investment against business risk, compliance requirements, and acceptable downtime.
Testing
High availability testing usually focuses on failover behavior. Teams test whether workloads continue operating when a server, application instance, database node, or network component fails.
Disaster recovery testing is broader. It validates whether the organization can restore systems, recover data, follow the DR plan, meet recovery objectives, and coordinate across IT, security, compliance, and business teams. DR testing may include tabletop exercises, backup restoration tests, and full failover simulations.
Business Impact
High availability reduces the likelihood that users will notice service interruptions. It is especially important for mission-critical systems that must remain online continuously, such as payment platforms, healthcare systems, industrial control systems, and customer-facing applications.
Disaster recovery reduces the impact of major disruptions after they occur. It helps organizations avoid prolonged outages, permanent data loss, regulatory penalties, reputational damage, and operational paralysis. While HA keeps the business running during smaller failures, DR helps the business survive larger incidents.
High Availability and Disaster Recovery Reinforce One Another
Organizations need to use high availability alongside disaster recovery to ensure business continuity. High availability and disaster recovery are both extremely important for business continuity—each playing a critical role in maintaining day-to-day uptime and data recoverability during a major disaster.
High availability helps protect against day-to-day events that might interrupt system availability, such as network failures, hardware failures, application failures, or load-induced outages. It ensures these failures result only in minimal or no impact at all. Disaster recovery processes kick in when a major outage occurs due to man-made or natural disasters.
Creating backups of business-critical systems and storing offsite data recovery copies ensures organizations have resilient backups available for restoring data during data loss events. Replication helps protect the organization during a site-wide disaster that takes an entire site offline. Replicating virtual machines (VMs) to a data recovery facility enables organizations to reroute resources to the data recovery site when the main production site goes down.
Built-In Data Protection for Disaster Recovery with Cloudian
Do you need to backup data to on-premises storage, as part of your disaster recovery setup? Cloudian offers a low-cost disk-based storage technology that lets you backup data locally with a capacity of up to 1.5 Petabytes. You can also set up a Cloudian appliance in a remote site and use our integrated data management tools to save data there.
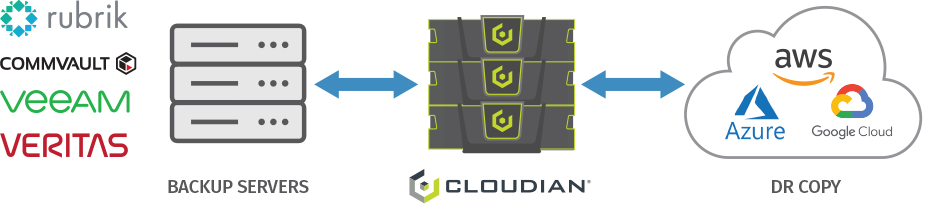
 Another deployment option is a hybrid cloud configuration. You can backup data to a local Cloudian appliance, then replicate to the cloud for DR purposes. This combines the low latency of local storage with the resilience of the cloud.
Another deployment option is a hybrid cloud configuration. You can backup data to a local Cloudian appliance, then replicate to the cloud for DR purposes. This combines the low latency of local storage with the resilience of the cloud.
Learn more about Cloudian’s data protection solution.