What is Disaster Recovery on AWS?
Amazon Web Services (AWS) lets you set up disaster recovery, both for on-premise services, and for workloads deployed in the Amazon cloud.
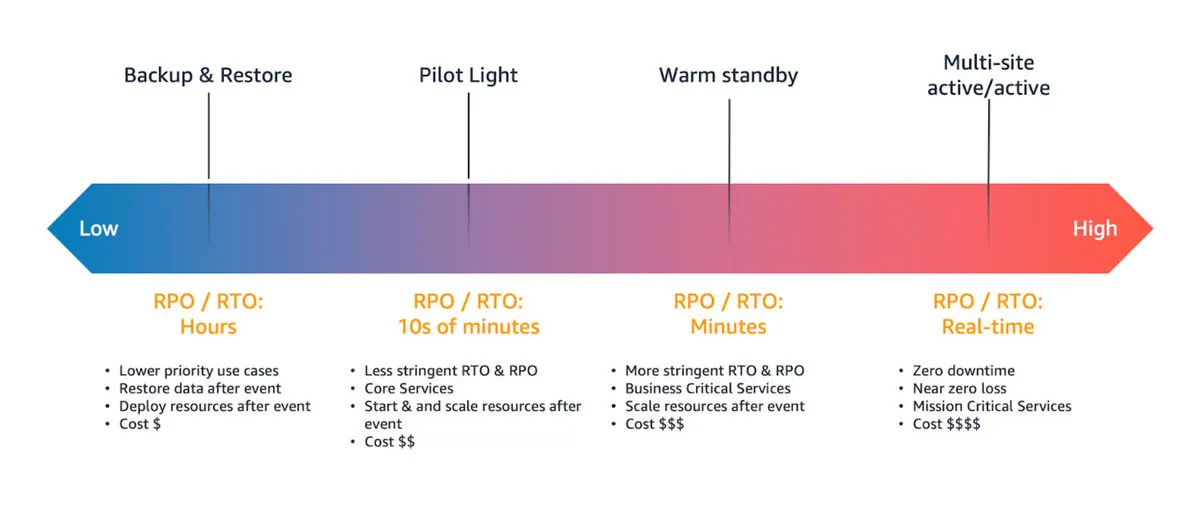
AWS offers four main disaster recovery (DR) strategies you can leverage to create backups and replicas that are available during disaster events. Each strategy has progressively higher cost and complexity, but lower recovery times:
- Backup and restore – involves backing up your systems and restoring them from backup in case of disaster.
- Pilot light – involves running core services in standby mode, and triggering additional services as needed in case of disaster.
- Warm standby – involves running a full backup system in standby mode, with live data replicated from the production environment.
- Multi-site active/active – running a full, secondary production system, ready to serve traffic when needed.
Source: Amazon
Each DR strategy on AWS offers different recovery time objectives (RTO) and recovery point objectives (RPO) designed at several ranges of costs and complexities.
Generally, the more complex and highly available DR strategies come with higher costs and the less complex strategies that provide lower availability are more cost-effective.
To ensure your DR strategy suits the needs of your organization and is properly working, you need to test it before the initial implementation, and again on a continuous basis.
In this article, you will learn:
DR Strategies on AWS and their Recovery Point Objective and Recovery Time Objective
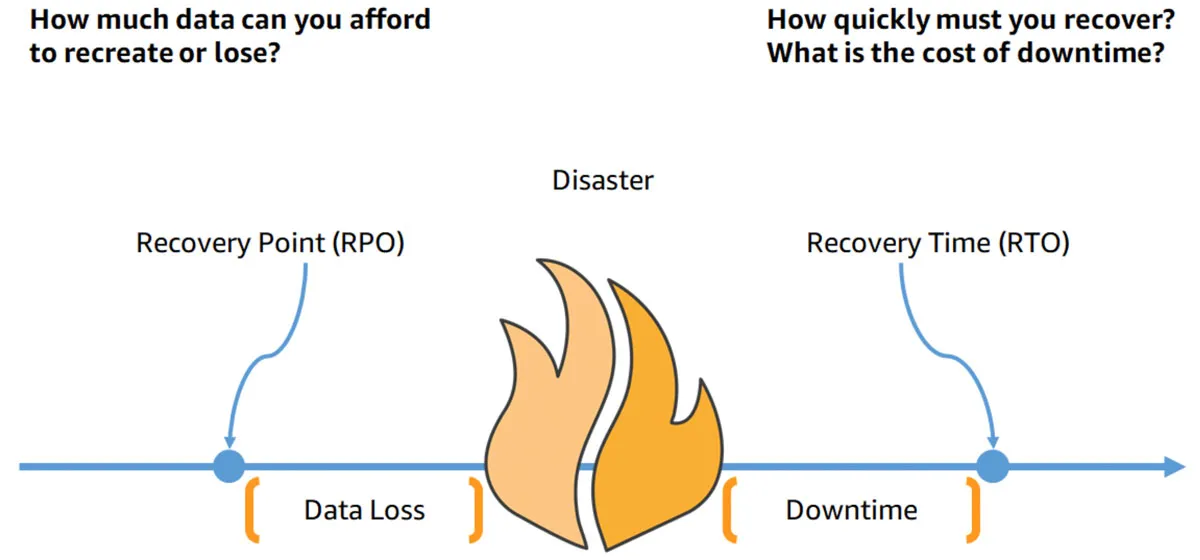
When planning your disaster recovery strategy on AWS, consider your recovery time objective (RTO) and recovery point objective (RPO), as illustrated in the image below:
- Recovery Time Objective (RTO) is the longest delay the business can tolerate between the disaster event and continuation of services.
- Recovery Point Objective (RPO) is the longest time that may pass since the last backup window. For example, if the organization backs up files once per hour, at most the organization can lose one hour of data, the RPO is 60 minutes.
Source:Amazon
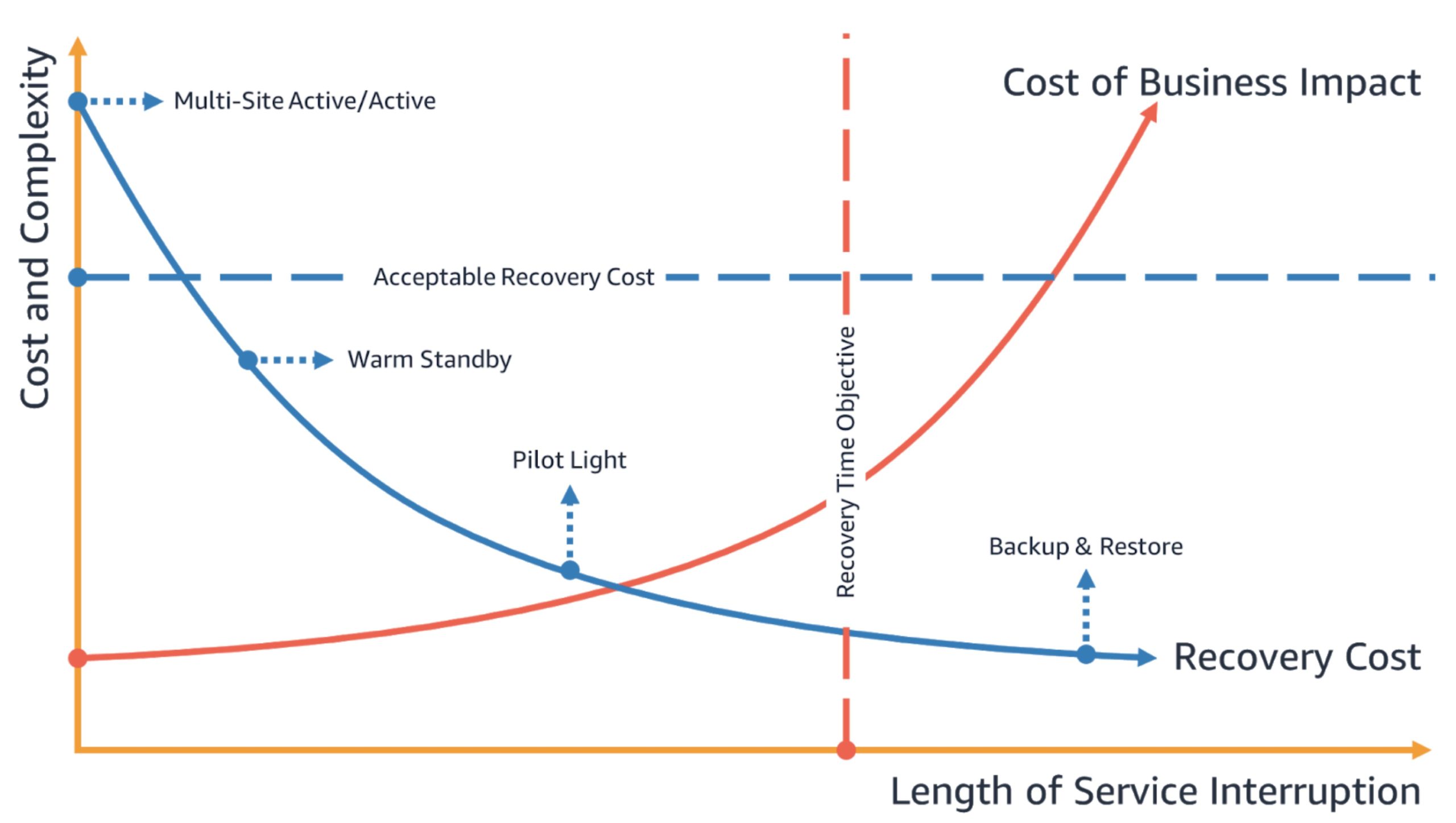
The following chart illustrates how the four disaster recovery strategies relate to RTO and RPO, adding the dimension of the cost of implementing each solution. The vertical red line shows the RTO defined by an organization—DR strategies to the right of this line are not acceptable.
- Backup & restore provides the lowest cost, but the longest RTO
- Pilot light provides a medium cost and RTO
- Warm standby provides a high cost and low RTO
- Multi-site active/active provides the highest cost and a near-zero RTO
Source: Amazon
Learn more in our detailed guides to:
DR Strategies on AWS: Reference Architecture
Let’s dive deeper into each of the disaster recovery strategies we reviewed above, and see how Amazon recommends deploying each one. These are reference architectures which you can use as a blueprint, or customize according to your specific workloads and DR requirements.
Backup and Restore
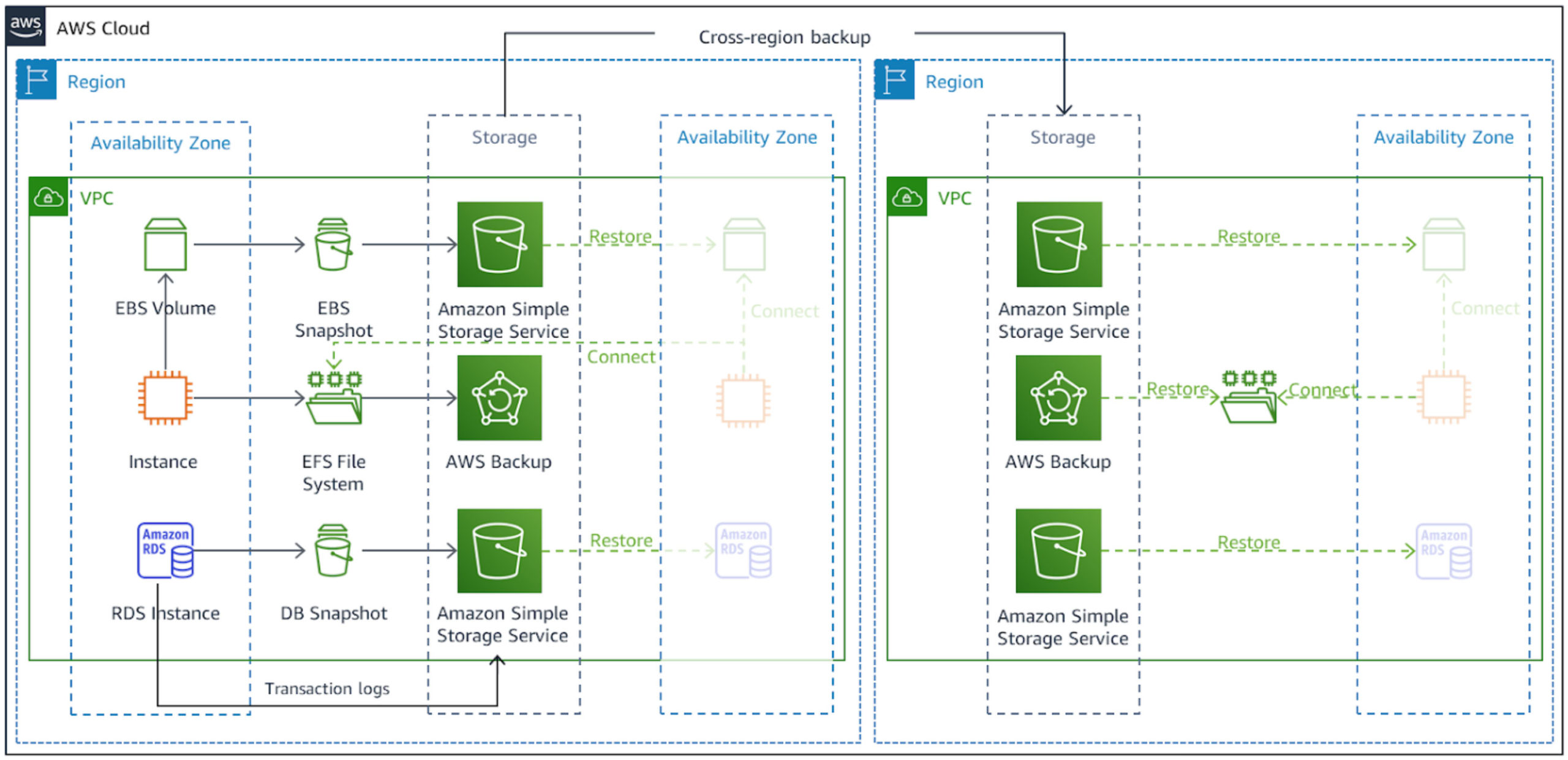
Figure 1 – Source: Amazon
The image above illustrates how several types of AWS data resources can be backed up. Here are several principles to keep in mind when using the backup and restore DR strategy on AWS:
- You can create backups in the same Region of the source.
- To ensure availability during disasters, backups are also replicated to other Regions.
- During Region failover, you can recover data from backup and restore your infrastructure from the recovery Region.
- You can leverate Infrastructure as Code (IaC) services like AWS Cloud Development Kit (AWS CDK) and AWS CloudFormation to consistently deploy your infrastructure across several Regions.
- To reduce the RTO of this strategy, you can implement techniques that improve detection and recovery. For example, you can design and execute serverless automation using Amazon EventBridge.
Pilot Light
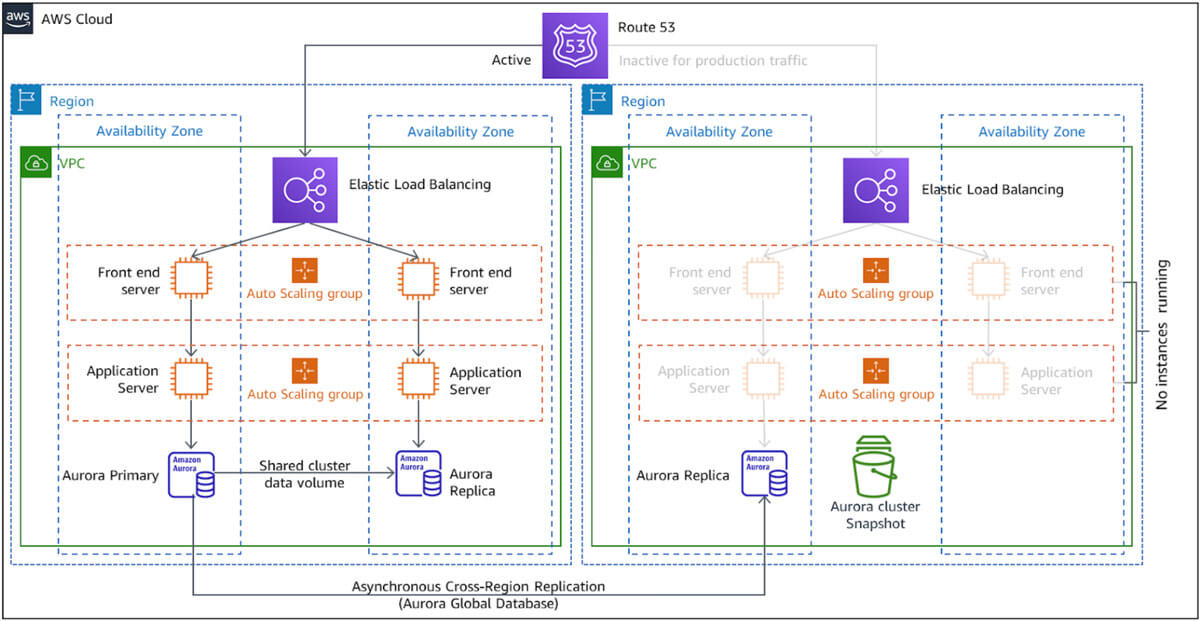
Figure 2—Source: Amazon
Business Continuity for Your Data with Cloudian
- Here are some principles to keep in mind when using the pilot light DR strategy on AWS:Idle services—requests are processed and the idle infrastructure components are deployed only when triggered. For example, in figure 2 Amazon EC2 Auto Scaling and Elastic Load Balancing serve as basic infrastructure components, whereas functional elements like compute resources are kept “shut off”.
- Shutting off resources—you can ensure your EC2 instances are shut off by not deploying any. In the image above, there are zero deployed instances.
- Turning on resources—you can turn on instances by deploying a previously used Amazon Machine Image (AMI) that was already copied to other Regions. The AMI creates EC2 instances that contain the required operating system (OS) and packages.
- Live data—databases and data stores are continuously kept up-to-date or nearly up-to-date with data located in the active Region. Live data is kept ready for when it is needed to service read operations.
- Replications and backup—creating replicas and placing them in read-only clusters is not enough to ensure availability during a data loss event. You also need to create backups that enable you to rewind to the last good state. Figure 2 illustrates how Amazon Aurora replicates your data to a read-only cluster located in a local recovery Region. Cluster snapshots are one alternative to create backups.
Warm Standby
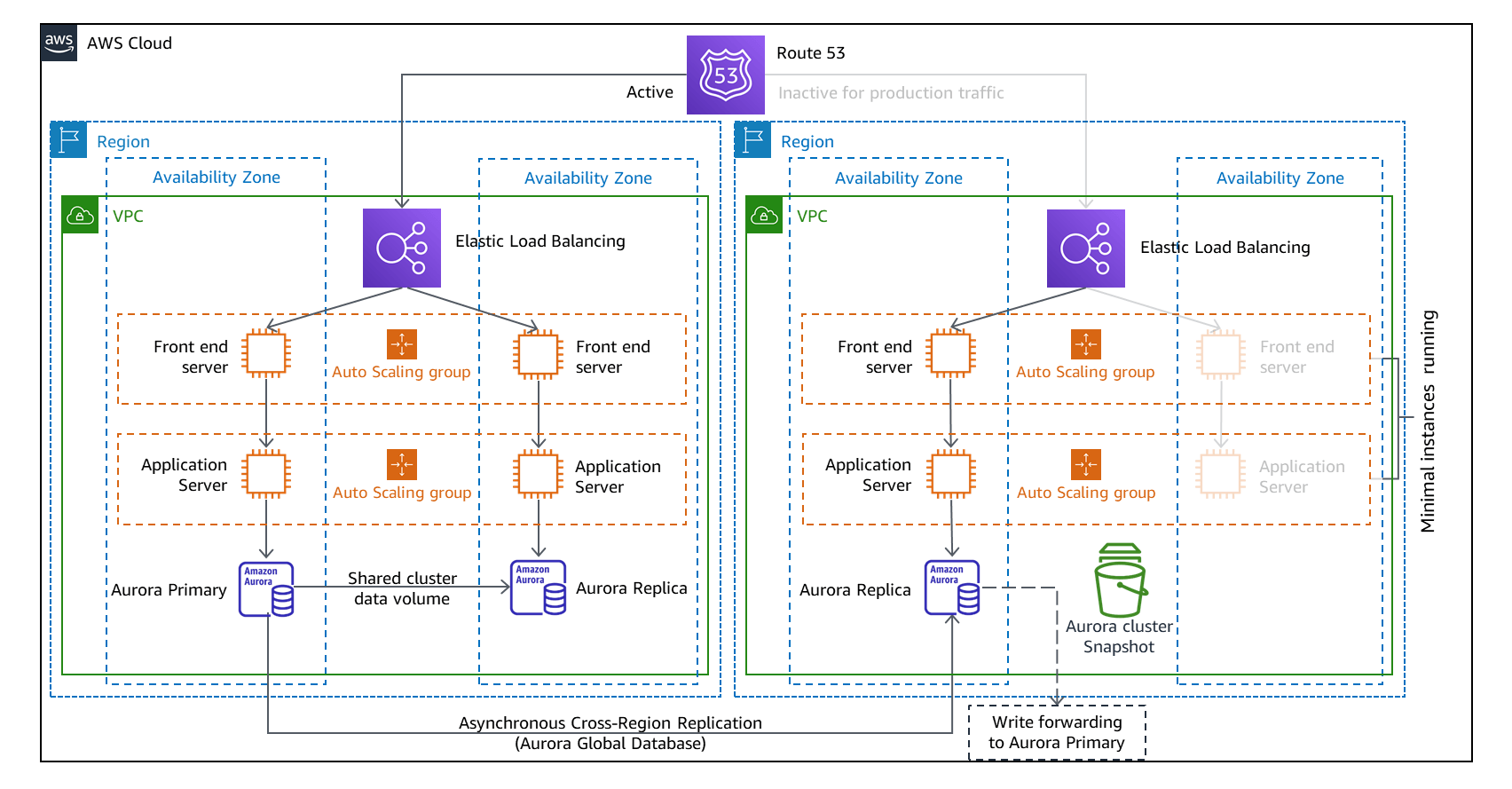 Figure 3—Source: Amazon
Figure 3—Source: Amazon
The warm standby DR strategy keeps live data (just like the pilot light DR strategy), while also maintaining periodic backups. Here are several principles to keep in mind while using the warm standby strategy on AWS:
- A warm standby cannot service production-level traffic—it maintains the minimum needed to handle requests at a reduced capacity. In the image above, you can see how only one EC2 instance is deployed per each tier.
- It is relatively easy to test warm standby—passive endpoints do not need additional work before handling synthetic testing transactions prior to deployment.
- You must scale up the infrastructure before failover—in order to meet production needs before failover.
- The main difference between the warm and pilot light strategy isT—the code and infrastructure running.
Multi-Site Active/Active
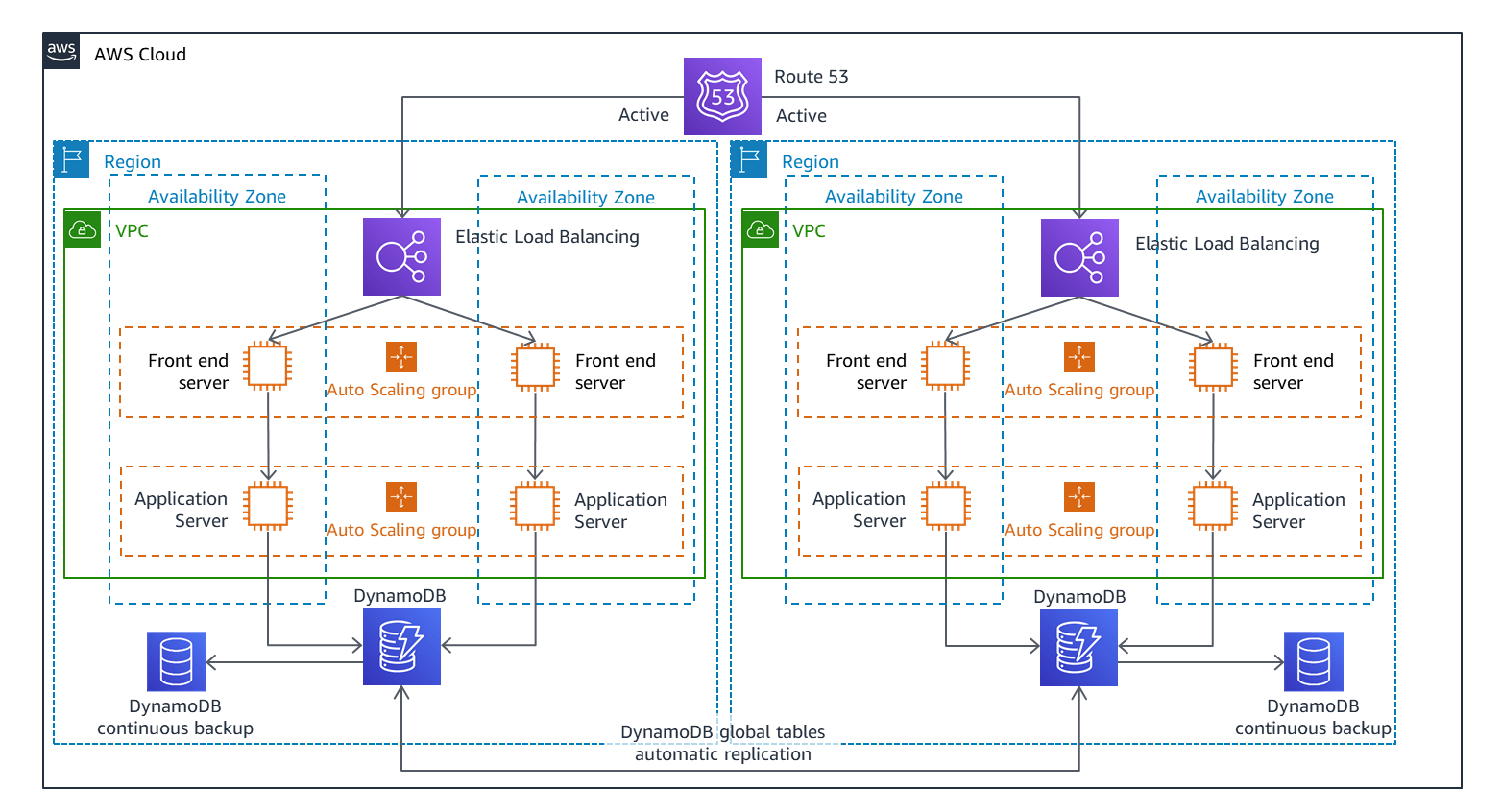
Figure 4—Source: AmazonThe multi-site active/active strategy maintains two or more active Regions available to accept requests. Here are several principles to keep in mind when using the multi-site active/active strategy on AWS:
- During failover— requests are re-routed from Regions unable to handle the requests.
- Read requests—are serviced using data replicated across Regions. The replicas are kept active to ensure availability during failover.
- Write requests—there are several options to ensure write requests are met. For example, you can re-route writes to a specific Region or write to a local Region.
- Data backup—should be created to ensure you can restore previous versions during data loss events. The image above shows how global tables are used for the database tier in Amazon DynamoDB. This ensures that tables can be written to in any location and data can be quickly propagated to any other Region.
Disaster Recovery on AWS—Single vs. Multiple Regions
There are three main redundancy options for a disaster recovery operation on AWS, each with progressively higher resilience:
Multiple Availability Zones in the Same Region
Safeguards against a disaster that disrupts one Amazon data center. By replicating across multiple AZs in the same region, your workloads are resilient to failure of an entire data center due to an error, malicious attack or natural disaster. Each AZ is isolated from faults in the other AZs in the same region.
If you have a regulatory requirement to store data in a specific geographic region (data residence), you can use the multi-AZ redundancy option, ensuring that all three AZs are within the mandated region.
Multiple AZs with Backup to Another Region
A more resilient option is to back up data, configurations, and infrastructure definitions to another Amazon region. This is significantly simpler and cheaper than multi-region deployment, discussed below. You can opt to store data in Amazon S3 Standard storage for fast retrieval, or, if retrieval can wait between minutes and hours, consider Amazon S3 Glacier or Glacier Deep Archive to conserve costs.
Multiple AWS Regions
The most resilient option is to deploy workloads across multiple AWS regions, which safeguards against the risk of failure to multiple data centers, physically distant from each other, at the same time. In case of failure of an entire Amazon region, your workloads will still be safely running in another Amazon region.
Protecting Data Effortlessly with Cloudian
If you need to backup data to on-premises storage, Cloudian offers low-cost disk-based storage with capacity up to 1.5 Petabytes. You can also set up a Cloudian appliance in a remote site and save data directly to the remote site using our integrated data management tools.
 Alternatively, you can use a hybrid cloud setup. Backup data to a local Cloudian appliance, and configure it to replicate all data to the cloud. This allows you to access data locally for quick recovery, while keeping a copy of data on the cloud in case a disaster affects the on-premise data center.
Alternatively, you can use a hybrid cloud setup. Backup data to a local Cloudian appliance, and configure it to replicate all data to the cloud. This allows you to access data locally for quick recovery, while keeping a copy of data on the cloud in case a disaster affects the on-premise data center.
Learn more about Cloudian’s data protection solutions.

