Path to Data Insights – Data Observability Platform with an S3-Compatible Data Lake
More than 90% of all data in the world was generated in just the last few years, and, according to IDC, the amount of data generated annually is expected to nearly triple from 2020 to 2025. This incredible growth presents the challenge of not only storing large data volumes but also, more importantly, of being able to ingest, access and analyze the data to get insights on demand. That’s why organizations are turning to data observability solutions backed by scalable S3 data lakes to break the silos and get business insights.
Monitoring vs Observability
Let’s first distinguish between monitoring and observability.
Monitoring refers to the processes and systems used by organizations to flag data for performance degradation and/or potential security breaches. Organizations can then configure these systems to send alerts and also automate the types of responses to certain events. Useful as it is, monitoring typically stays at one layer, either application or infrastructure and is only a partial solution.
Observability, on the other hand, provides full visibility into the health and performance of each layer of your environment. It starts with the capability to connect and ingest data from multiple sources into multiple tools and gives IT teams full visibility into their environment, from applications to infrastructure assets. Organizations are then able to observe their entire IT environment together and get insights to forecast future trends and outcomes which helps save time and money.
The Cloudian-Cribl Observability Platform
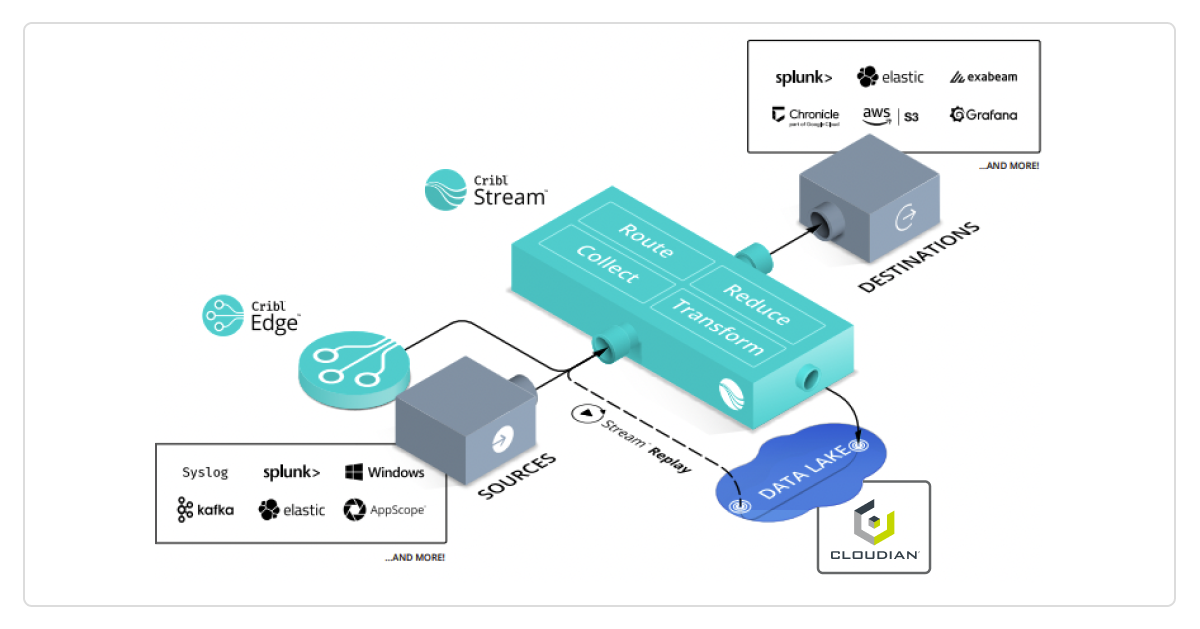
Cribl—a leading data analytics company and a key Cloudian technology alliance partner—has developed cutting-edge technology to solve the challenge of ingesting, managing and analyzing data more productively as well as efficiently. Cribl’s Stream product is an observability pipeline that connects to various sources of data, like networks, servers, applications, and software agents, and centralizes all of your observability data with full fidelity into an S3 data lake with Cloudian HyperStore object storage. This forms a modern observability platform based on a scale-out S3-compatible data lake designed for managing massive amounts and varieties of data, giving IT teams full control over every aspect of the data. The data is stored in HyperStore and always available for search and analysis. Cribl then allows customers to Replay (Cribl function) the data in Cloudian – applying filters and transformations as required – and feed it to higher level analytic tools like Splunk, Elastic and others.
The observability solution is also hybrid cloud-compatible, enabling organizations to reduce costs by having both on-prem and cloud assets simultaneously. Together, the solution built on Cribl and Cloudian lets you parse, restructure, and enrich data in flight – ensuring that you get the right data, where you want, and in the format you need. This provides organizations the opportunity to discover and understand their dynamic environments in real time and use the resulting data insights to make better informed decisions.
To learn more about the newly minted Cloudian-Cribl partnership how it can help you, register for the upcoming Cribl-Cloudian webinar on Nov. 9, 8am PST. You can also read more about the Cribl-Cloudian solution here.
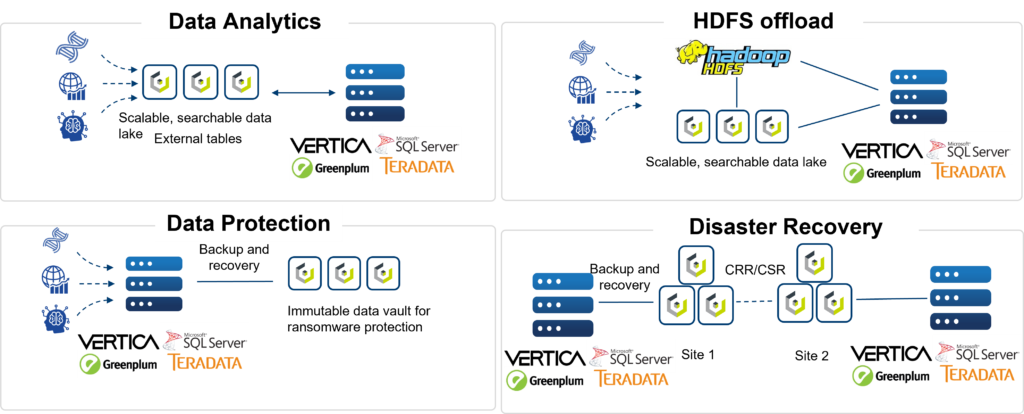
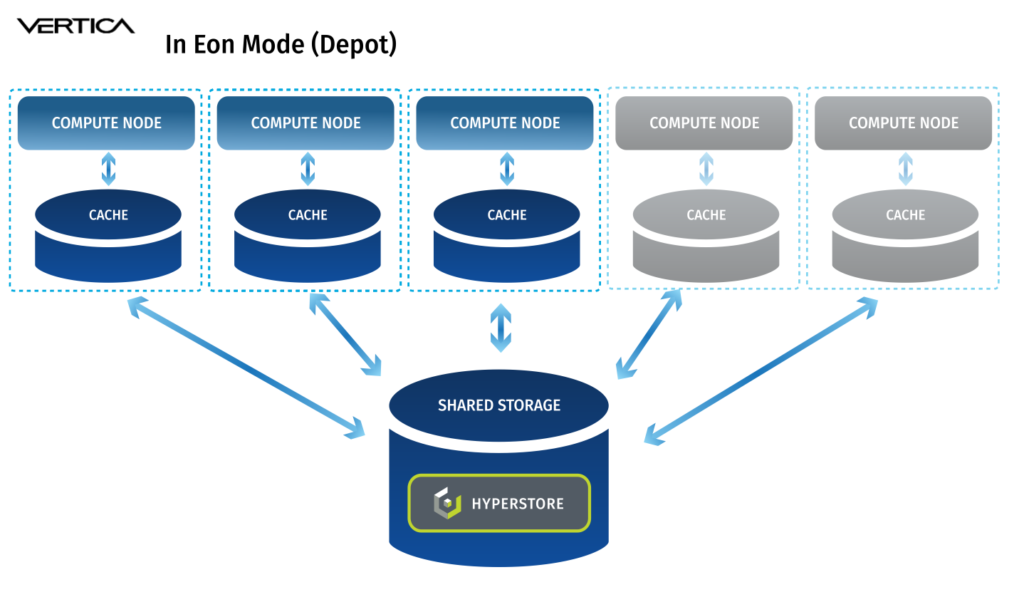 In the data analytics space, Vertica is known for performance, whether it is run in “Enterprise Mode” or “Eon Mode.” In Enterprise Mode each database node stores a portion of the dataset and performs a portion of the computation. In Eon Mode, Vertica brings its cloud architecture to on-premises deployments and decouples compute and storage. In Eon Mode, each Vertica node can access a shared communal storage space via S3 API. The advantages are: a) compute can be scaled as required without having to scale storage, meaning no more server sprawl and b) storage can be consolidated into a single platform and accessed by various data tools:
In the data analytics space, Vertica is known for performance, whether it is run in “Enterprise Mode” or “Eon Mode.” In Enterprise Mode each database node stores a portion of the dataset and performs a portion of the computation. In Eon Mode, Vertica brings its cloud architecture to on-premises deployments and decouples compute and storage. In Eon Mode, each Vertica node can access a shared communal storage space via S3 API. The advantages are: a) compute can be scaled as required without having to scale storage, meaning no more server sprawl and b) storage can be consolidated into a single platform and accessed by various data tools: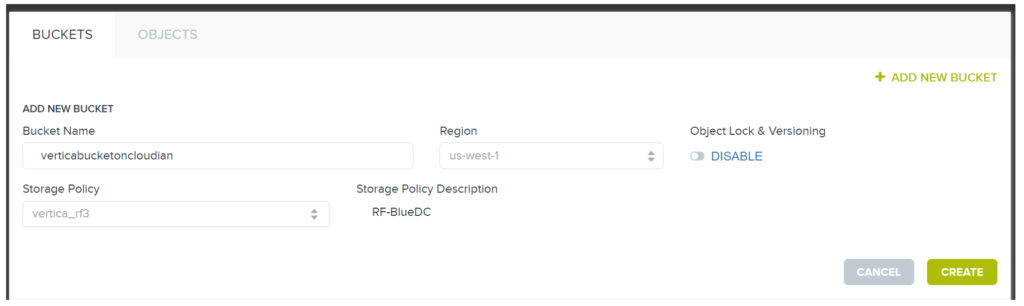
 Let’s consider the following scenario… we have an ORC dataset, which was generated by an Apache Hive instance, stored on Cloudian, and we need to connect to it with Vertica. To analyze this dataset in-place, use the following Vertica syntax to connect to the ORC dataset:
Let’s consider the following scenario… we have an ORC dataset, which was generated by an Apache Hive instance, stored on Cloudian, and we need to connect to it with Vertica. To analyze this dataset in-place, use the following Vertica syntax to connect to the ORC dataset:




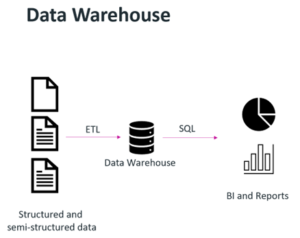
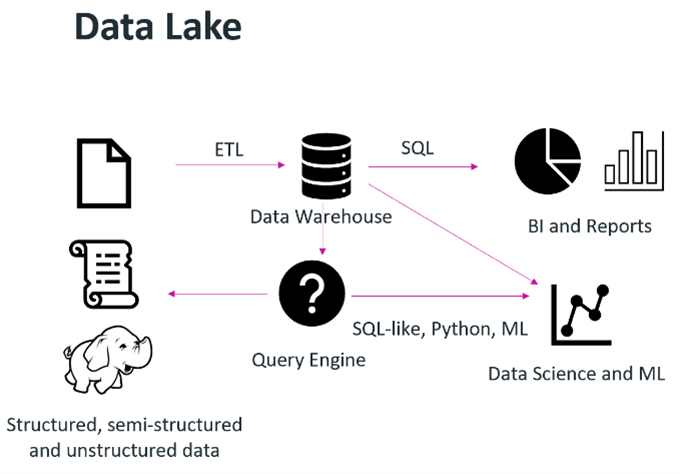 Organizations wanted to leverage data science or machine learning techniques to provide some desired output or piece of monetizable information, such as a formula that would predict the failure rate of a widget based on millions of data points. The term “data lake” was coined, and a data lake’s purpose was to store data in raw formats. The challenge here was that data lakes are good for storing data, not enforcing data quality or running transactions on top of them.
Organizations wanted to leverage data science or machine learning techniques to provide some desired output or piece of monetizable information, such as a formula that would predict the failure rate of a widget based on millions of data points. The term “data lake” was coined, and a data lake’s purpose was to store data in raw formats. The challenge here was that data lakes are good for storing data, not enforcing data quality or running transactions on top of them.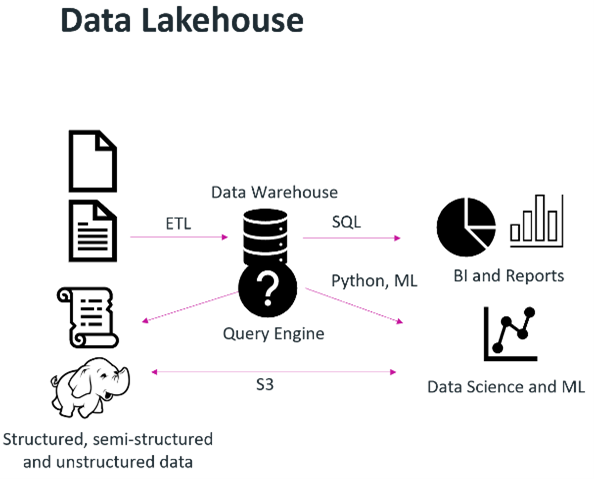 S3-based object storage enables the creation of a modern data lakehouse, where storage can be decoupled from compute, diverse analytic workloads can be supported and tools/platforms are able to access data directly with standard S3 API calls.
S3-based object storage enables the creation of a modern data lakehouse, where storage can be decoupled from compute, diverse analytic workloads can be supported and tools/platforms are able to access data directly with standard S3 API calls.